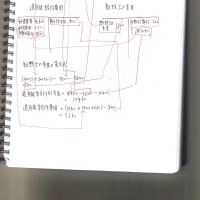
前の章では、バイナリサーチツリー(binary search tree)が大変便利なデータ構造であることを学びました。
データの項目の探索や挿入、それに削除が、とても素早く出来ましたね。
配列、ソート済み配列、連結リストなどのデータ構造は、これらの操作が大変遅いのです。
(Javaで学ぶアルゴリズムとデータ構造 第九章 レッドグラフツリー P359より)
現在のPCのGUI技術は木構造(ツリー)を用いている。
それは、プログラマーの立場から見ると、データの探索・挿入・削除がそこそこのスピードを保てて、プログラミングを行いやすいためだ。
しかし、あまりにもツリーが深くなると探索のアルゴリズムが前から一つ一つ調べていくのと変わらくなる。
HDDの容量が大容量化した現在、単純なツリーの探索アルゴリズムだとデータを検索するために非常に時間がかかる。
だから、MacのTigerやMS、Googleのデスクトップ検索では"インデックスによる検索"を採用した。
つまり、データ構造の中で一番早くデータが検索できる"配列(ハッシュテーブル?)構造"を使うようになった。
"Javaで学ぶアルゴリズムとデータ構造"を読んで、ふと↑のような考えが浮かんだのですけど、どうでしょう?
私は、最近はやりの"デスクトップ検索"について細部まで把握していないので的外れなことを言っているかもしれませんが
データの項目の探索や挿入、それに削除が、とても素早く出来ましたね。
配列、ソート済み配列、連結リストなどのデータ構造は、これらの操作が大変遅いのです。
(Javaで学ぶアルゴリズムとデータ構造 第九章 レッドグラフツリー P359より)
現在のPCのGUI技術は木構造(ツリー)を用いている。
それは、プログラマーの立場から見ると、データの探索・挿入・削除がそこそこのスピードを保てて、プログラミングを行いやすいためだ。
しかし、あまりにもツリーが深くなると探索のアルゴリズムが前から一つ一つ調べていくのと変わらくなる。
HDDの容量が大容量化した現在、単純なツリーの探索アルゴリズムだとデータを検索するために非常に時間がかかる。
だから、MacのTigerやMS、Googleのデスクトップ検索では"インデックスによる検索"を採用した。
つまり、データ構造の中で一番早くデータが検索できる"配列(ハッシュテーブル?)構造"を使うようになった。
"Javaで学ぶアルゴリズムとデータ構造"を読んで、ふと↑のような考えが浮かんだのですけど、どうでしょう?
私は、最近はやりの"デスクトップ検索"について細部まで把握していないので的外れなことを言っているかもしれませんが