








Googleは3月に、テンソル処理ユニット(Edge TPU)AIアクセラレータチップを搭載したコンパクトなPCであるCoral Dev Boardと、既存のRaspberry PiおよびLinuxシステムでの機械学習の推論を高速化するために設計されたUSBドングル(Coral USB Accelerator )。 それ以来、キットのサポートリソースの更新は着実に行われ、本日、Googleは分類モデルの新しいファミリであるEfficientNet-EdgeTPUをリリースしました。Coralボードのシステムオンモジュールでの実行に最適化されています。

EfficientNet-EdgeTPUのトレーニングコードと事前トレーニングモデルの両方がGitHubで利用可能です。
機械学習アクセラレータアーキテクトのSuyog GuptaとGoogle Researchのソフトウェアエンジニアは、次のように述べています。 明星タン。 「皮肉なことに、これらのアーキテクチャはデータセンターやエッジコンピューティングプラットフォームで着実に普及していますが、それらで実行される[AIモデル]は、基礎となるハードウェアを活用するためにカスタマイズされることはめったにありません。」
EfficientNet-EdgeTPUプロジェクトの目標は、GoogleのEfficientNetsから派生したモデルを電力効率の良い、オーバーヘッドの少ないEdge TPUチップに合わせることでした。 以前のテストでは、EfficientNetsは既存のAIシステムの特定のカテゴリーよりも高い精度と効率の両方を実証し、パラメーターサイズとFLOPS(浮動小数点計算)を1桁削減しました。
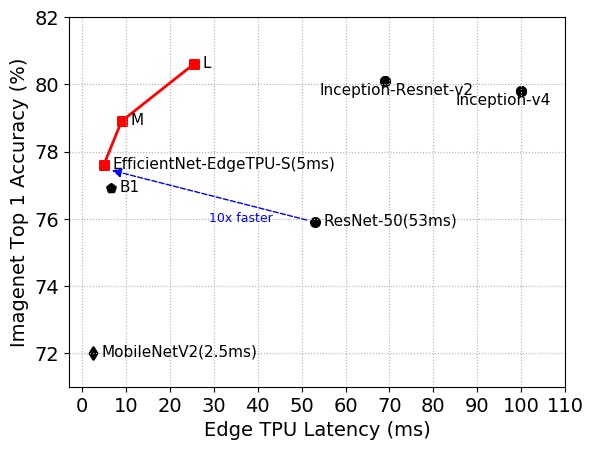
EfficientNet-EdgeTPU-Sは、ResNet-50よりも高い精度を実現しつつ、10倍高速に動作します。
これは、EfficientNetsがグリッド検索を使用して、固定リソース制約の下でベースラインAIモデルのスケーリングディメンション間の関係を識別するためです。 検索により各次元の適切なスケーリング係数が決定され、係数が適用されてベースラインモデルが目的のモデルサイズまたは計算予算にスケールアップされます。
Gupta、Tan、および同僚によると、EfficientNetsを再構築してEdge TPUを活用するには、Googleが開発したAutoML MNASフレームワークを呼び出す必要がありました。 MNASは、ハードウェアの制約(特にオンチップメモリ)を考慮した強化学習を組み込むことにより、候補のリストから理想的なモデルアーキテクチャを特定し、さまざまなモデルを実行し、実物のパフォーマンスを測定してから作物のクリームを選択します。 チームは、Edge TPUでの実行時にアルゴリズムのレイテンシの推定値を提供するレイテンシ予測モジュールでこれを補完しました。
全体論的なアプローチにより、ベースラインモデルEfficientNet-EdgeTPU-Sが作成されました。研究者は、入力画像解像度スケーリング、ネットワーク幅、深度スケーリングの最適な組み合わせを選択することでスケールアップしました。 実験では、結果として得られるより大きなアーキテクチャ-EfficientNet-EdgeTPU-MおよびEfficientNet-EdgeTPU-L-は、Inception-resnet-v2やResnet50のような一般的な画像分類モデルと比較して、レイテンシを増加させてより高い精度を実現し、Edge TPUでより高速に実行しました。

- Google Coral Edge TPU 官方海外代理店: https://store.gravitylink.com/global
EfficientNet-EdgeTPUのリリースは、ハイブリッド量子化、完全整数量子化、プルーニングを含むツールスイートであるGoogleのTensorFlow用Model Optimization Toolkitのデビューの翌日です。 注目すべきは、トレーニング後のfloat16量子化です。これにより、AIモデルのサイズが最大50%削減され、精度はほとんど低下しません。









※コメント投稿者のブログIDはブログ作成者のみに通知されます