








この記事はただのシェアです。元記事はここです。
記事の内容は以下の通りです。
以前、サイトスクレイピングツールのimport.ioを紹介しました。現在、無料版は利用できなくなっているようです。
import.ioは、URLを入力するだけでサイト上のデータを自動的に判断してデータ化してくれる便利なWEBサービスでした。
けれど、データ化したい箇所を詳細に設定するのには、向いていませんでした(WEBサイト上のツールでは)。
それで先日、Octoparseというツールを教えてもらい、使ってみたところ、結構手軽ながら詳細にスクレイピングする箇所を設定できるツールだったので紹介です。
Octoparseとは
Octoparseは、どんなWEBサイト上のデータも手軽に抽出することができる無料スクレイピングツールです。
無料版だと、一部機能に制限がありますが、ヘビーユーズでもしない限りは、十分すぎるくらいの機能があります。無料版と有料版の違いについては、Pricingを参照してみてください。有料版だと、タスクの登録数や自動実行数が多くなり、クラウド上で動作させることもできます。
実際に使ってみた感じでは、視覚的に分かりやすくデータ抽出箇所を設定することができ、実行することができるツールになっています。
例えば以下のようなデータ抽出なら簡単にできてしまいます。
1.単一ページ上のデータを抽出する
2.ページネーションを移動しながらリストデータを取得する
3.リストのリンク先もたどって取得する
4.URLを複数指定して全てのページから指定したデータを取得する
Octoparseは、上記のように様々なスクレイピング方法を利用する事ができますが、以降では一般的なデータ抽出方法を紹介したいと思います。
Octoparse利用の主な手順
Octoparseを利用するには、主に以下の手順が必要です。
1.Octoparseに登録する
2.Octoparseのダウンロード
3.Octoparseのインストール
4.Octoparseでデータ抽出
以下では、それぞれの手順について詳しく紹介したいと思います。
Octoparseに登録する
Octoparseは、無料から利用できるツールではありますが、ツールを使用するにはOctoparseへの無料登録が必要です。
まずは、Octoparseの「Sign up」をクリックしてください。
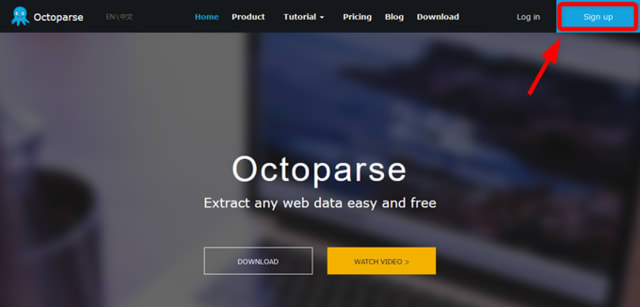
「ユーザーネーム」、「パスワード」、「メールアドレス」を入力して登録作業を行ってください。
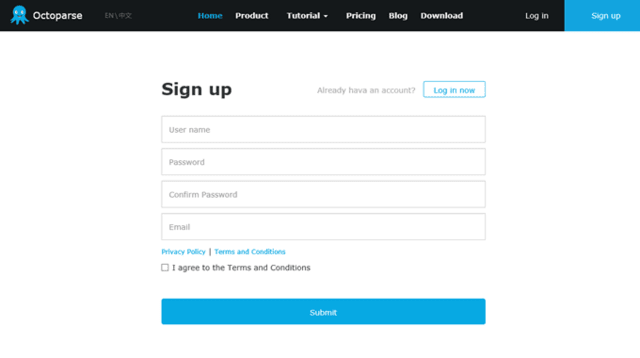
アカウント情報登録したら、メールが届くので、確認用のリンクをクリックしたら登録完了です。

Octoparseのダウンロード
ダウンロードは、Octoparse free downloadから行うことができます。
ブラウザでダウンロードページを開いたら、「Download」ボタンを押して「From Dropbox」と書かれているアイコンをクリックしてください。
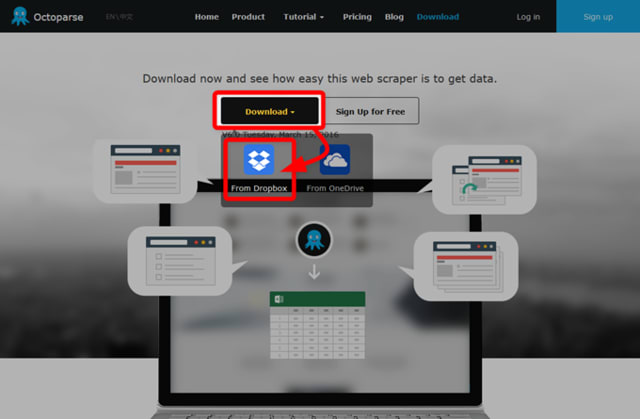
すると、Dropbox上に以下のようなOctoparseのダウンロードページが表示されます。

ダウンロードページ右上にある「ダウンロードボタンの▼」をクリックして「直接ダウンロード」を選択してください。
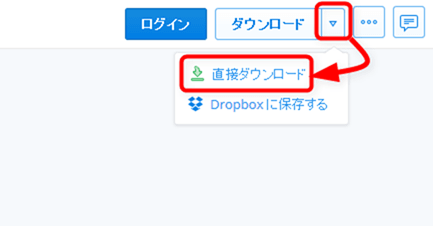
すると「Octoparse V6.0Setup.zip」のようなファイルがダウンロードされます。

ダウンロードが終了したら、ZIPファイルを展開(解凍)しておいてください。
Octoparseのインストール
展開(解凍)後のフォルダに「setup.exe」というファイルがあるので起動します。
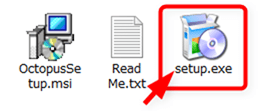
すると、以下のようなOctoparseのインストーラーが起動するので、基本的に「Next」ボタンを押していけばインストールは終了します。

このインストーラで、変更できる箇所といえば、「Install場所」くらいなもんなので、特に難しい設定はありません。
Octoparseでデータ抽出
Octoparseのインストールが終了したら、以下のようなショートカットがデスクトップ上にあると思うので起動します。

Octoparseにログイン
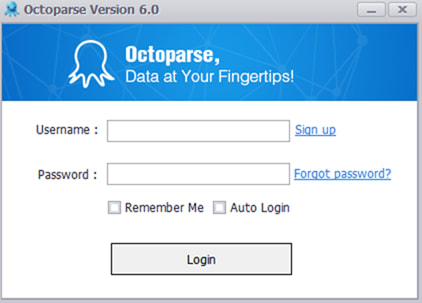
すると以下のようなログインダイアログが表示されるので、登録時に入力した「ユーザーネーム」と「パスワード」を入力して「Login」ボタンを押してください。
すると、以下のようにOctoparseが起動します。

初回起動時はユーザーガイド画面が表示されると思いますが、上記はそれを閉じた状態です。
Octoparseでデータを抽出
Octoparseでは、様々なデータ抽出方法があるのですが、今回はその中から最も一般的な「リスト状となっているコンテンツからデータを抽出する方法」を紹介したいと思います。
Octoparseには、ウィザード形式で抽出データを指定する「Wizard mode(ウィザードモード)」と、自由に抽出データを指定できる「Advanced mode(アドバンスドモード)」がありますが、今回は初めての場合でも手軽に行えるウィザードモードの利用方法を紹介します。
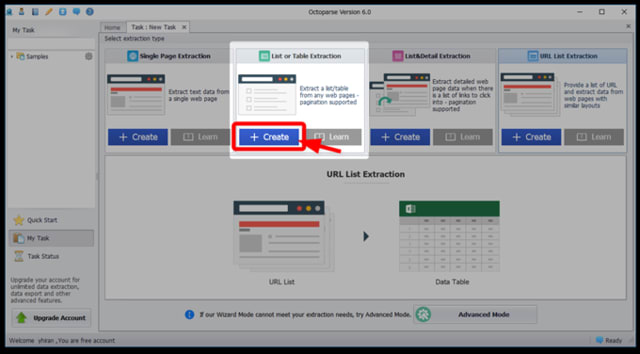
まずは「Wizard mode(ウィザードモード)」の「Start」ボタンをクリックしてください。

「List or Table Extraction」項目の「Create」ボタンを押してください。
もしかしたら初回起動時、「List or Table Extraction」のチュートリアルが表示されるかもしれませんが、そのチュートリアルは終わったものとして説明します。
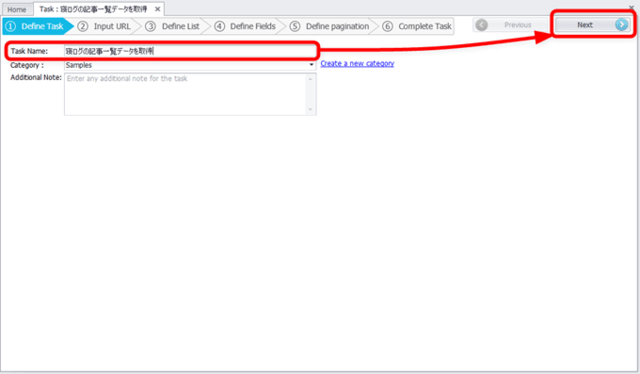
タスク名を入力
まずは、タスク名をつけて「Next」ボタンをクリックします。
抽出ページのURLを入力
次に、スクレイピングするページのURLを入力して「Next」ボタンを押します。
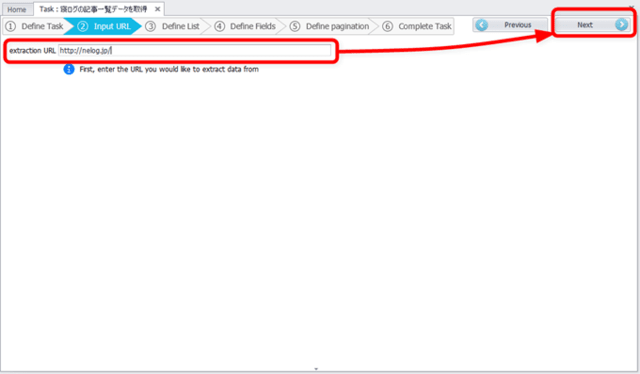
今回は、「当サイトの記事一覧リストをスクレイピングすること」を例に紹介します。
すると以下のように、ブラウザコンポーネント部分にページが表示されます。

リストの定義
次にリストの定義を行います。
リストの定義は、リストデータとなるHTML要素を2つを選択することで行います。
リストデータ部分のHTML要素上にマウスオーバーすると、以下のように背景が水色に表示されるのでクリックして選択します。
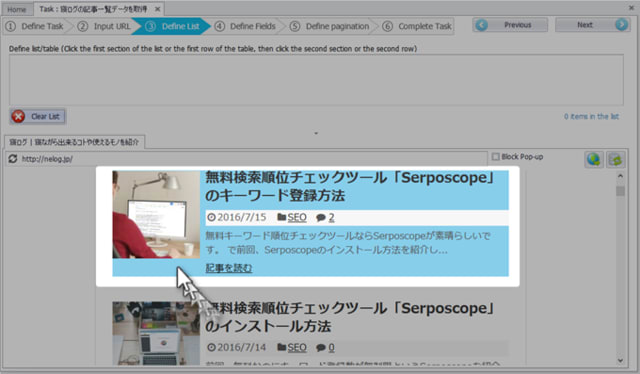
1つ目のHTML要素を選択すると、要素内の情報が上部情報欄に加えられます。

次に、2つ目のリストデータとなるHTML要素を1つ目と同様に選択します。

2つ目のリスト要素を選択すると、ツールに法則性が伝わるので、全てのリスト情報が抽出されます。
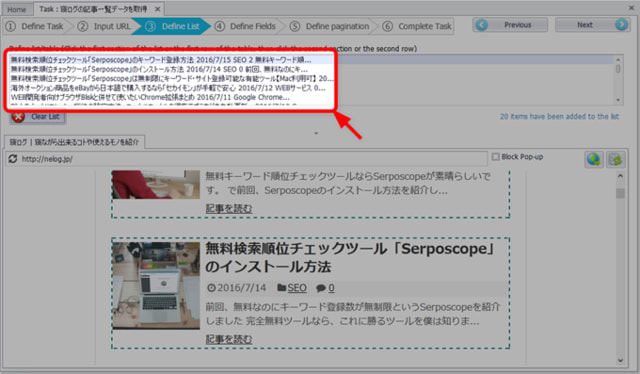
リスト要素を選択し終わったら、「Next」ボタンをクリックしてください。

抽出するデータの選択
次に、抽出するデータの選択を行います。
今回は例として以下のデータを抽出したいと思います。
タイトル
公開日
サムネイル
まずは、タイトル部分の指定です。
タイトル部分にマウスオーバーすると、背景が水色になるので、クリックして選択します。
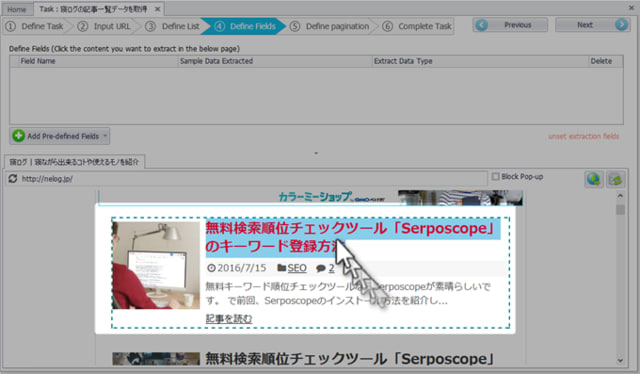
選択を行うと、上部情報欄に登録されます。
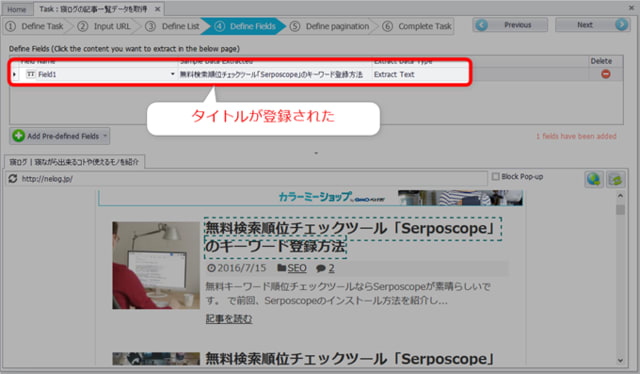
この要領で公開日も選択します。
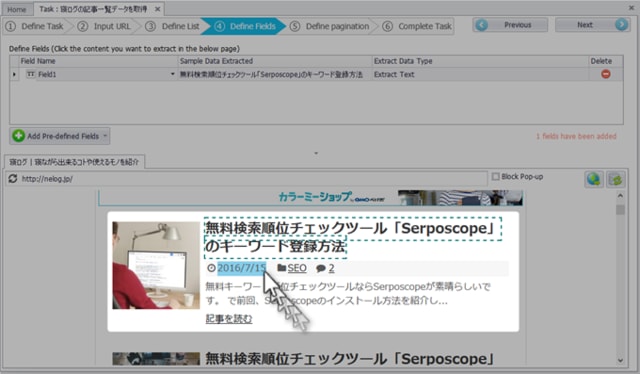
選択を終えると公開日も登録されました。
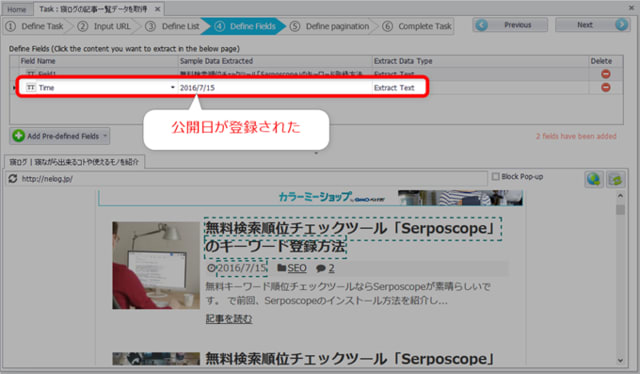
最後に、サムネイルもこれまでと同様に選択します。

サムネイルも登録されました。
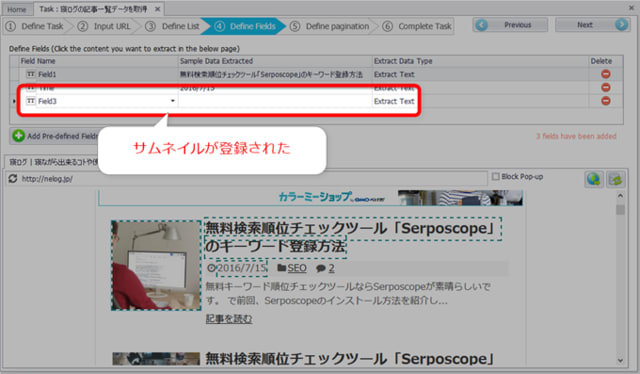
ただ、サムネイル抽出の設定をしたはいいものの、抽出データにURLが表示されていません。

この部分にURLを指定するには、「Extract text」と書かれた部分をクリックしてリストボックスを表示させ、「Extract “src” attribute(IMG address or IFRAME address)」と書かれているアイテムを選択します。

このようにすることで、imgタグのsrc属性から画像URLを抽出することができます。

抽出データの選択を終えたら「Next」ボタンを押してください。

ページネーションの設定
複数にわたるページを遷移しながらデータをスクレイピングしていくために、ページネーションの設定を行います。
まずはオプションの「Pagenation」を選択してください。

次にブラウザ部分でサイトのページネーション部分を表示させ、「次のページへ行くためのリンク」を選択し、「Next」ボタンを押します。

Octoparseは、この「次のページへ行くためのリンク」をたどってページを移動していきます。
タスクの実行を行う
最後に、タスクの実行オプションを選択します。
今回は、ローカルクライアント上でスクレイピングを行うので、「Local Extraction(ローカル抽出)」を選択してください。
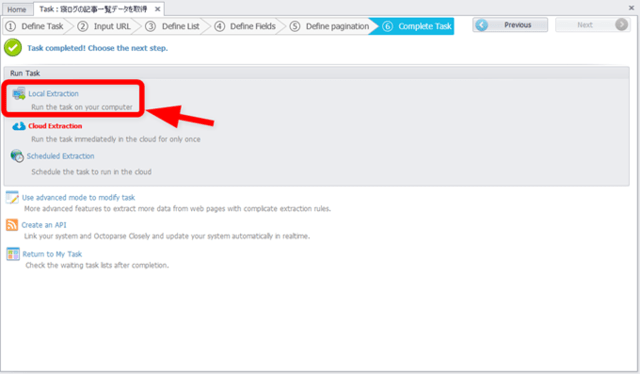
有料版などになると、クラウド上でスクレイピングを行うこともできます。
すると、新しいダイアログが表示されスクレイピングが開始します。
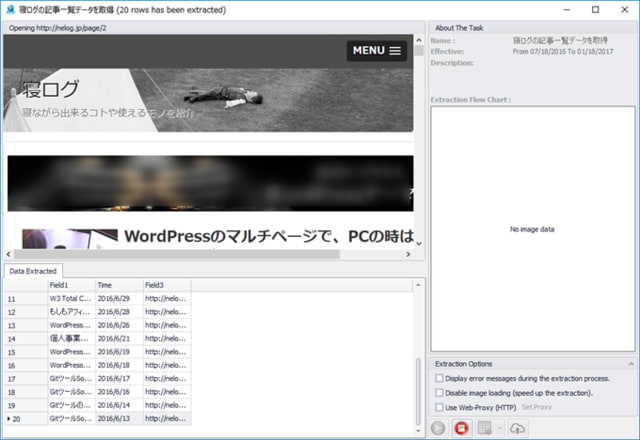
1ページが終わると、ページネーションの設定からページを移動しながら、どんどんデータを取得してくれます。

全てのデータ抽出が終了すると、以下のようなダイアログが表示されます。

最後に抽出したデータを保存するには、以下のボタンから行います。
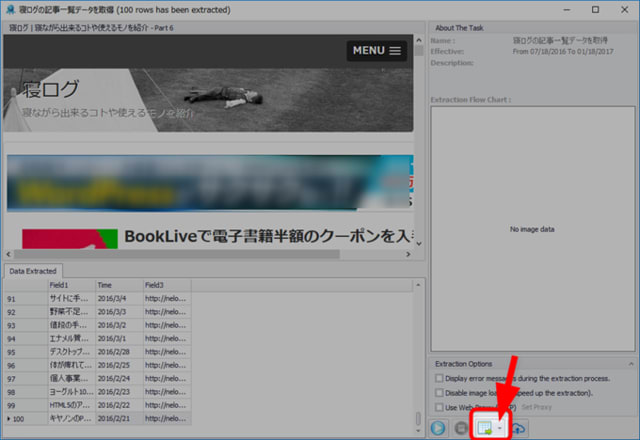
抽出したデータをエクセルで表示すると以下のように、ちゃんと取得されています。

Octoparseには、その他にもビデオチュートリアルも沢山あるので、その他の抽出設定方法も、手軽に学ぶことができます。
まとめ
Octoparseでは、このように(プログラムでスクレイピング処理を書くよりは)かなり手軽に思い通りのスクレイピングを行うことができます。
僕はこれまで、Rubyでスクレイピングコードは書いたことがあります。Rubyには、Nokogiri&Mechanizeという便利なライブラリがあって、ある程度手軽にスクレイピング出来るようにはなっています。
ただそれでも、コードがどういった振る舞いを行うか処理を書いたり、データの取得箇所をCSSセレクター(もしくは、Xpath)で指定したりする必要があり、やはり手軽に「やろう!」という気にはなりません。
今回紹介したOctoparseを利用することで、複雑なコードは一切書く必要がなく手軽にスクレイピング処理を実行できるようになると思います(もちろんコードで直接書くほど自由度は高くないけど)。
というわけで、スクレイピングをしてサイトをデータ化したいけど「コードを書くのが面倒くさい」もしくは「コードを書けない」なんて場合には、結構重宝するのではないかと思います。
サイトのスクレイピングは、スクレイピング先のサーバーに負荷をかけてしまいます。Octoparseを利用する場合は、節度を守ってご利用ください。また、サイトの利用規約などに「スクレイピング禁止」と書かれているサイトでのご利用は控えてください。
記事の内容は以下の通りです。
以前、サイトスクレイピングツールのimport.ioを紹介しました。現在、無料版は利用できなくなっているようです。
import.ioは、URLを入力するだけでサイト上のデータを自動的に判断してデータ化してくれる便利なWEBサービスでした。
けれど、データ化したい箇所を詳細に設定するのには、向いていませんでした(WEBサイト上のツールでは)。
それで先日、Octoparseというツールを教えてもらい、使ってみたところ、結構手軽ながら詳細にスクレイピングする箇所を設定できるツールだったので紹介です。
Octoparseとは
Octoparseは、どんなWEBサイト上のデータも手軽に抽出することができる無料スクレイピングツールです。
無料版だと、一部機能に制限がありますが、ヘビーユーズでもしない限りは、十分すぎるくらいの機能があります。無料版と有料版の違いについては、Pricingを参照してみてください。有料版だと、タスクの登録数や自動実行数が多くなり、クラウド上で動作させることもできます。
実際に使ってみた感じでは、視覚的に分かりやすくデータ抽出箇所を設定することができ、実行することができるツールになっています。
例えば以下のようなデータ抽出なら簡単にできてしまいます。
1.単一ページ上のデータを抽出する
2.ページネーションを移動しながらリストデータを取得する
3.リストのリンク先もたどって取得する
4.URLを複数指定して全てのページから指定したデータを取得する
Octoparseは、上記のように様々なスクレイピング方法を利用する事ができますが、以降では一般的なデータ抽出方法を紹介したいと思います。
Octoparse利用の主な手順
Octoparseを利用するには、主に以下の手順が必要です。
1.Octoparseに登録する
2.Octoparseのダウンロード
3.Octoparseのインストール
4.Octoparseでデータ抽出
以下では、それぞれの手順について詳しく紹介したいと思います。
Octoparseに登録する
Octoparseは、無料から利用できるツールではありますが、ツールを使用するにはOctoparseへの無料登録が必要です。
まずは、Octoparseの「Sign up」をクリックしてください。
「ユーザーネーム」、「パスワード」、「メールアドレス」を入力して登録作業を行ってください。
アカウント情報登録したら、メールが届くので、確認用のリンクをクリックしたら登録完了です。
Octoparseのダウンロード
ダウンロードは、Octoparse free downloadから行うことができます。
ブラウザでダウンロードページを開いたら、「Download」ボタンを押して「From Dropbox」と書かれているアイコンをクリックしてください。
すると、Dropbox上に以下のようなOctoparseのダウンロードページが表示されます。
ダウンロードページ右上にある「ダウンロードボタンの▼」をクリックして「直接ダウンロード」を選択してください。
すると「Octoparse V6.0Setup.zip」のようなファイルがダウンロードされます。
ダウンロードが終了したら、ZIPファイルを展開(解凍)しておいてください。
Octoparseのインストール
展開(解凍)後のフォルダに「setup.exe」というファイルがあるので起動します。
すると、以下のようなOctoparseのインストーラーが起動するので、基本的に「Next」ボタンを押していけばインストールは終了します。
このインストーラで、変更できる箇所といえば、「Install場所」くらいなもんなので、特に難しい設定はありません。
Octoparseでデータ抽出
Octoparseのインストールが終了したら、以下のようなショートカットがデスクトップ上にあると思うので起動します。
Octoparseにログイン
すると以下のようなログインダイアログが表示されるので、登録時に入力した「ユーザーネーム」と「パスワード」を入力して「Login」ボタンを押してください。
すると、以下のようにOctoparseが起動します。
初回起動時はユーザーガイド画面が表示されると思いますが、上記はそれを閉じた状態です。
Octoparseでデータを抽出
Octoparseでは、様々なデータ抽出方法があるのですが、今回はその中から最も一般的な「リスト状となっているコンテンツからデータを抽出する方法」を紹介したいと思います。
Octoparseには、ウィザード形式で抽出データを指定する「Wizard mode(ウィザードモード)」と、自由に抽出データを指定できる「Advanced mode(アドバンスドモード)」がありますが、今回は初めての場合でも手軽に行えるウィザードモードの利用方法を紹介します。
まずは「Wizard mode(ウィザードモード)」の「Start」ボタンをクリックしてください。
「List or Table Extraction」項目の「Create」ボタンを押してください。
もしかしたら初回起動時、「List or Table Extraction」のチュートリアルが表示されるかもしれませんが、そのチュートリアルは終わったものとして説明します。
タスク名を入力
まずは、タスク名をつけて「Next」ボタンをクリックします。
抽出ページのURLを入力
次に、スクレイピングするページのURLを入力して「Next」ボタンを押します。
今回は、「当サイトの記事一覧リストをスクレイピングすること」を例に紹介します。
すると以下のように、ブラウザコンポーネント部分にページが表示されます。
リストの定義
次にリストの定義を行います。
リストの定義は、リストデータとなるHTML要素を2つを選択することで行います。
リストデータ部分のHTML要素上にマウスオーバーすると、以下のように背景が水色に表示されるのでクリックして選択します。
1つ目のHTML要素を選択すると、要素内の情報が上部情報欄に加えられます。
次に、2つ目のリストデータとなるHTML要素を1つ目と同様に選択します。
2つ目のリスト要素を選択すると、ツールに法則性が伝わるので、全てのリスト情報が抽出されます。
リスト要素を選択し終わったら、「Next」ボタンをクリックしてください。
抽出するデータの選択
次に、抽出するデータの選択を行います。
今回は例として以下のデータを抽出したいと思います。
タイトル
公開日
サムネイル
まずは、タイトル部分の指定です。
タイトル部分にマウスオーバーすると、背景が水色になるので、クリックして選択します。
選択を行うと、上部情報欄に登録されます。
この要領で公開日も選択します。
選択を終えると公開日も登録されました。
最後に、サムネイルもこれまでと同様に選択します。
サムネイルも登録されました。
ただ、サムネイル抽出の設定をしたはいいものの、抽出データにURLが表示されていません。
この部分にURLを指定するには、「Extract text」と書かれた部分をクリックしてリストボックスを表示させ、「Extract “src” attribute(IMG address or IFRAME address)」と書かれているアイテムを選択します。
このようにすることで、imgタグのsrc属性から画像URLを抽出することができます。
抽出データの選択を終えたら「Next」ボタンを押してください。
ページネーションの設定
複数にわたるページを遷移しながらデータをスクレイピングしていくために、ページネーションの設定を行います。
まずはオプションの「Pagenation」を選択してください。
次にブラウザ部分でサイトのページネーション部分を表示させ、「次のページへ行くためのリンク」を選択し、「Next」ボタンを押します。
Octoparseは、この「次のページへ行くためのリンク」をたどってページを移動していきます。
タスクの実行を行う
最後に、タスクの実行オプションを選択します。
今回は、ローカルクライアント上でスクレイピングを行うので、「Local Extraction(ローカル抽出)」を選択してください。
有料版などになると、クラウド上でスクレイピングを行うこともできます。
すると、新しいダイアログが表示されスクレイピングが開始します。
1ページが終わると、ページネーションの設定からページを移動しながら、どんどんデータを取得してくれます。
全てのデータ抽出が終了すると、以下のようなダイアログが表示されます。
最後に抽出したデータを保存するには、以下のボタンから行います。
抽出したデータをエクセルで表示すると以下のように、ちゃんと取得されています。
Octoparseには、その他にもビデオチュートリアルも沢山あるので、その他の抽出設定方法も、手軽に学ぶことができます。
まとめ
Octoparseでは、このように(プログラムでスクレイピング処理を書くよりは)かなり手軽に思い通りのスクレイピングを行うことができます。
僕はこれまで、Rubyでスクレイピングコードは書いたことがあります。Rubyには、Nokogiri&Mechanizeという便利なライブラリがあって、ある程度手軽にスクレイピング出来るようにはなっています。
ただそれでも、コードがどういった振る舞いを行うか処理を書いたり、データの取得箇所をCSSセレクター(もしくは、Xpath)で指定したりする必要があり、やはり手軽に「やろう!」という気にはなりません。
今回紹介したOctoparseを利用することで、複雑なコードは一切書く必要がなく手軽にスクレイピング処理を実行できるようになると思います(もちろんコードで直接書くほど自由度は高くないけど)。
というわけで、スクレイピングをしてサイトをデータ化したいけど「コードを書くのが面倒くさい」もしくは「コードを書けない」なんて場合には、結構重宝するのではないかと思います。
サイトのスクレイピングは、スクレイピング先のサーバーに負荷をかけてしまいます。Octoparseを利用する場合は、節度を守ってご利用ください。また、サイトの利用規約などに「スクレイピング禁止」と書かれているサイトでのご利用は控えてください。

※コメント投稿者のブログIDはブログ作成者のみに通知されます