








Webサイトからデータを抜き出し、xls、csv、txt、xmlなどに変換するには、コピペが一番使われますよね。でも、データの量が多いなら、相当な労力を費やします。もしPythonなどのプログラミング技術があれば、Webスクレイピングでコピペを自動化でき、その仕事が楽になります。プログラミングの知識がないなら、コピペしかありませんか?そこで、Googleスプレッドシートを試してみてください。
Googleスプレッドシートはリリース以来、多くの人々の日常業務に使われていますが、多くの組み込み関数があることを知らないかもしれません。実は、スプレッドシートを利用して、コードを書く必要なしに、Webから自動的にデータを取得できます。
この記事では、まずGoogleスプレッドシートだけで簡易なスクレイピングができる方法をお伝えします。次に、スクレイピングツールOctoparseを使って、データ取得のプロセスを比較します。皆さんは、スクレイピングニーズに適した方法を選択することができます。
GoogleスプレッドシートでIMPORTXML関数を使って簡単なWebクローラーを構築する
ステップ1:新しいGoogleスプレッドシートを開来ます。
ステップ2:ChromeブラウザでターゲットWebサイトsteamspy.comを開きます。ページを右クリックして「検証」を選択し、コンビネーションキー「Ctrl + Shift + C」を押して「セレクタ」を有効にします。そうすると、必要な箇所にカーソルを置くと、対応する情報が「検証パネル」に表示されます。
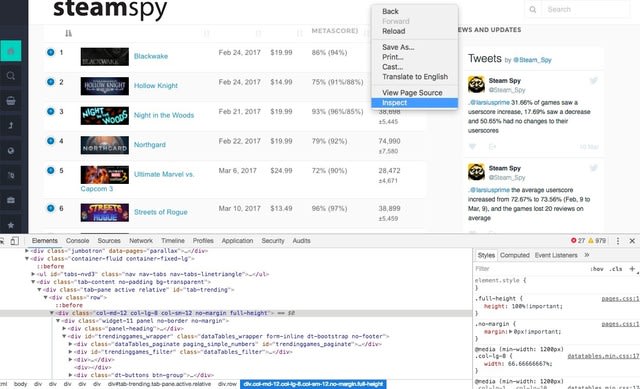
コンビネーションキー「Ctrl + Shift + C」
ステップ3:URLをスプレッドシートにコピペします。ここではA2に指定します。
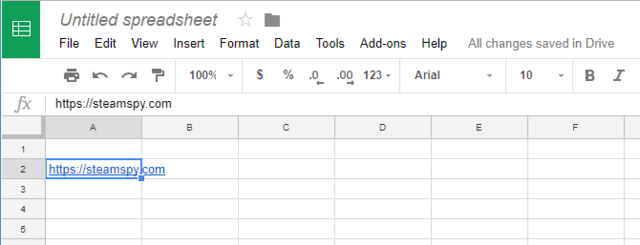
IMPORTXMLという非常に便利な関数を使って、価格データを取得します。
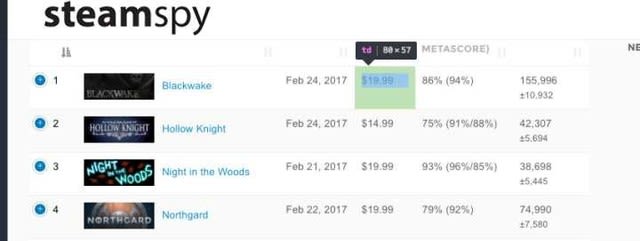
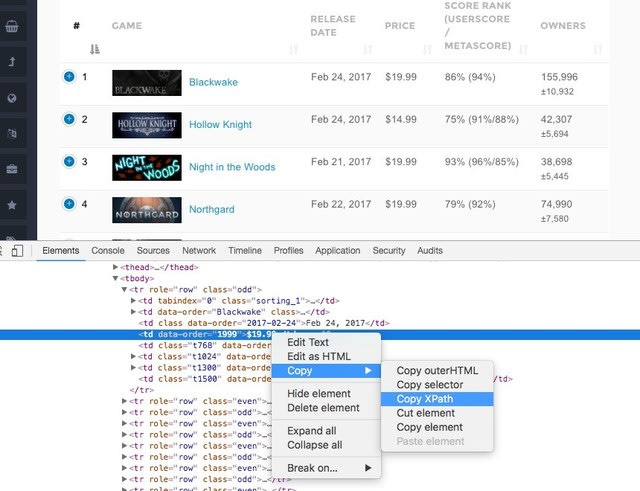
まず、要素のXpathをコピーする必要があります。
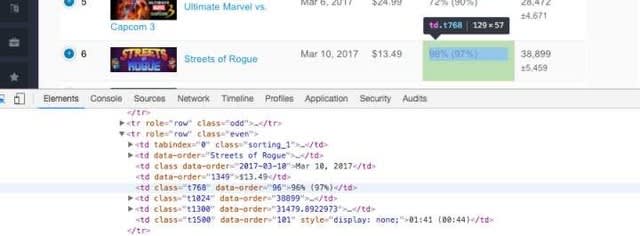
価格の箇所を選択 → Copy → Copy XPath をクリック。
//*[@id="trendinggames"]/tbody/tr[1]/td[4]
XPathを取得しました。
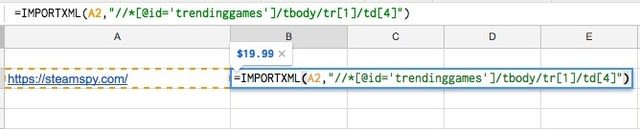
次、シートに下の関数式を入力します。
=IMPORTXML(URL, XPathクエリ)
そして、URLとXPathクエリを指定します。ダブルクオートがスプレッドシートの引数とぶつかってしまうため、そこだけシングルクオートに変更してください。
=IMPORTXML(A2,"//*[@id=’trendinggames’]/tbody/tr[1]/td[4]")
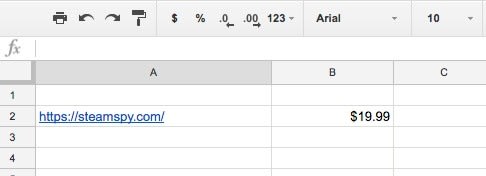
これで無事、"$19.99" という文字列が取得できました。
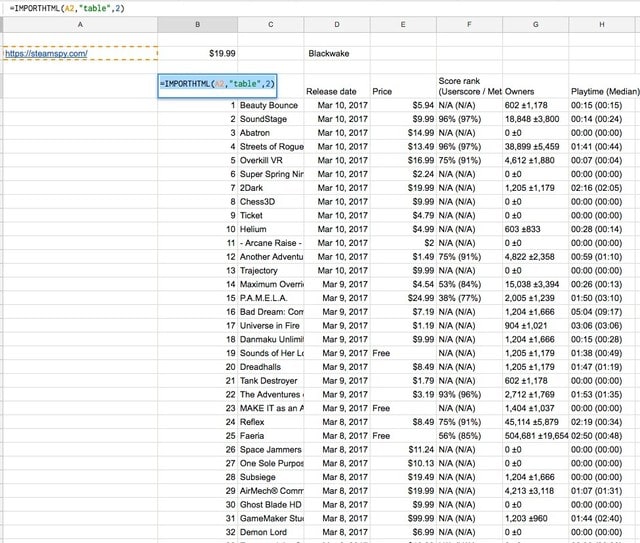
テーブルの取得方法もあります。
= IMPORTHTML(URL, クエリ, 指数)
この式を使うと、テーブル全体を簡単に抽出できます。
さて、スクレイピングツールOctoparseを使って、同じ作業をどのように達成できるかを見てみましょう。
ステップ1:Octoparseでスクレイピングするサイトを開く
Octoparseには、ウィザード形式で手軽に行える「Wizard mode」と、自由度高い「Advanced mode」がありますが、今回は「Advanced mode」を利用してみます。URLを入力し、下部にある「Save URL」をクリックします。ちなみに、インターフェイスの右上にある「ワークフロー」ボタンを開くと、タスクの実行順番を確認できます。

ステップ2: ページ遷移のループを作る
ページのある「Next」ボタンをクリックし、「Action Tips」パネルから「Loop click next page」を選択します。

ステップ3:Webクローラーを定義する
すべての情報を読み込んだ後、「Loop Item」を作します。
まず、第一行のデータをクリックします。各行を全体として取得するには「Action Tips」パネルに「TR」をクリックしてください。
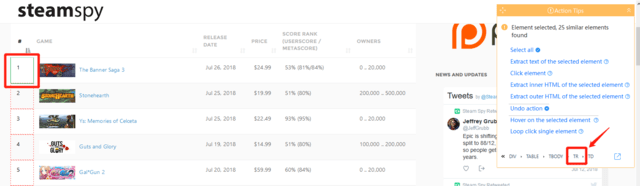
そうすると、第一行全体が指定されました。
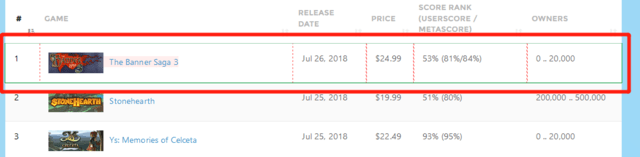
アイテムが1行しか選択されません。ですから、25行になるまで次のアイテムを同じように指定します。
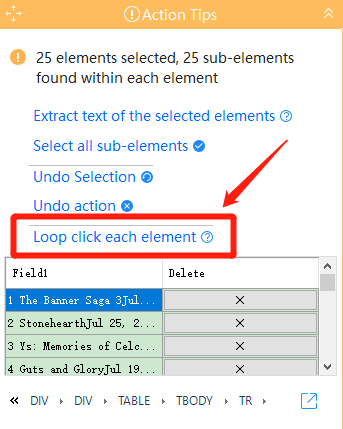
「Loop click each element」をクリックした後、「Loop Item」ができました。
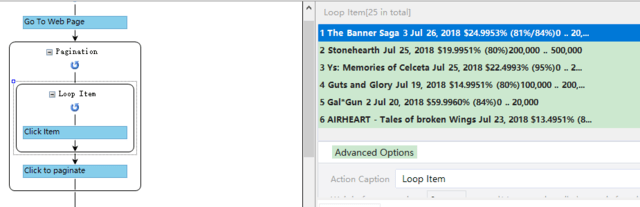
でも、クリックするのではなく、各行のデータをスクレイピングしたいので、「Click Item」を右クリックして「Delete」を選択します。
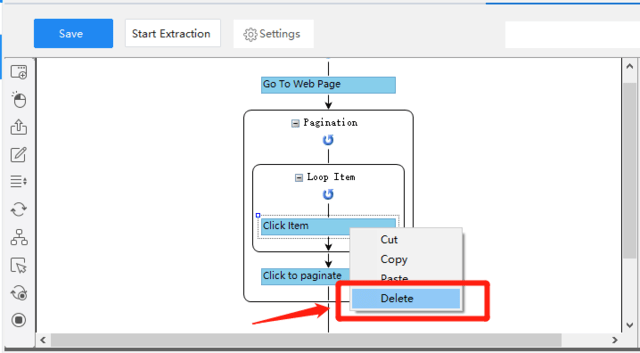
それから、ワークフローで、「Extract data」のアイコンを「Loop Item」に引きずって、「Loop Item」の中に置きます。
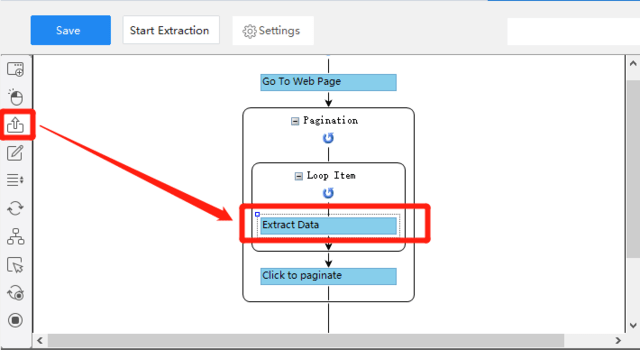
ステップ4:抽出したいデータを選択する
必要なデータをクリックし、「Action Tips」にある「Extract text of the selected element」を選択します。
必要に応じて、フィールド名を編集します。
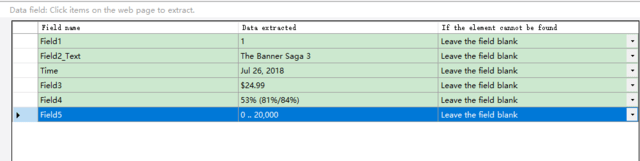
ステップ5:クローラーを行い、データを抽出する
「Save」をクリックして、クローラーの設定を保存します。それから、「Start Extraction」をクリック、クローラーを行い、以下のようにデータを取得しました!CSV、Excelなどの形式で出力できます。
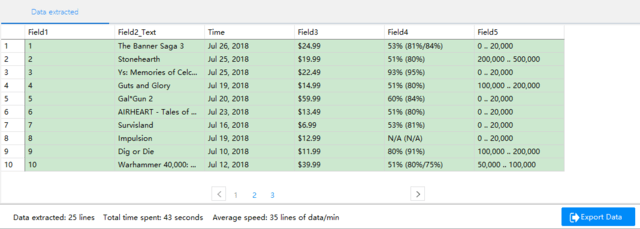
いかがでしたか?簡単にデータを取得できますね!皆さんもお試してみてください。
Googleスプレッドシートはリリース以来、多くの人々の日常業務に使われていますが、多くの組み込み関数があることを知らないかもしれません。実は、スプレッドシートを利用して、コードを書く必要なしに、Webから自動的にデータを取得できます。
この記事では、まずGoogleスプレッドシートだけで簡易なスクレイピングができる方法をお伝えします。次に、スクレイピングツールOctoparseを使って、データ取得のプロセスを比較します。皆さんは、スクレイピングニーズに適した方法を選択することができます。
GoogleスプレッドシートでIMPORTXML関数を使って簡単なWebクローラーを構築する
ステップ1:新しいGoogleスプレッドシートを開来ます。
ステップ2:ChromeブラウザでターゲットWebサイトsteamspy.comを開きます。ページを右クリックして「検証」を選択し、コンビネーションキー「Ctrl + Shift + C」を押して「セレクタ」を有効にします。そうすると、必要な箇所にカーソルを置くと、対応する情報が「検証パネル」に表示されます。
コンビネーションキー「Ctrl + Shift + C」
ステップ3:URLをスプレッドシートにコピペします。ここではA2に指定します。
IMPORTXMLという非常に便利な関数を使って、価格データを取得します。
まず、要素のXpathをコピーする必要があります。
価格の箇所を選択 → Copy → Copy XPath をクリック。
//*[@id="trendinggames"]/tbody/tr[1]/td[4]
XPathを取得しました。
次、シートに下の関数式を入力します。
=IMPORTXML(URL, XPathクエリ)
そして、URLとXPathクエリを指定します。ダブルクオートがスプレッドシートの引数とぶつかってしまうため、そこだけシングルクオートに変更してください。
=IMPORTXML(A2,"//*[@id=’trendinggames’]/tbody/tr[1]/td[4]")
これで無事、"$19.99" という文字列が取得できました。
テーブルの取得方法もあります。
= IMPORTHTML(URL, クエリ, 指数)
この式を使うと、テーブル全体を簡単に抽出できます。
さて、スクレイピングツールOctoparseを使って、同じ作業をどのように達成できるかを見てみましょう。
ステップ1:Octoparseでスクレイピングするサイトを開く
Octoparseには、ウィザード形式で手軽に行える「Wizard mode」と、自由度高い「Advanced mode」がありますが、今回は「Advanced mode」を利用してみます。URLを入力し、下部にある「Save URL」をクリックします。ちなみに、インターフェイスの右上にある「ワークフロー」ボタンを開くと、タスクの実行順番を確認できます。
ステップ2: ページ遷移のループを作る
ページのある「Next」ボタンをクリックし、「Action Tips」パネルから「Loop click next page」を選択します。
ステップ3:Webクローラーを定義する
すべての情報を読み込んだ後、「Loop Item」を作します。
まず、第一行のデータをクリックします。各行を全体として取得するには「Action Tips」パネルに「TR」をクリックしてください。
そうすると、第一行全体が指定されました。
アイテムが1行しか選択されません。ですから、25行になるまで次のアイテムを同じように指定します。
「Loop click each element」をクリックした後、「Loop Item」ができました。
でも、クリックするのではなく、各行のデータをスクレイピングしたいので、「Click Item」を右クリックして「Delete」を選択します。
それから、ワークフローで、「Extract data」のアイコンを「Loop Item」に引きずって、「Loop Item」の中に置きます。
ステップ4:抽出したいデータを選択する
必要なデータをクリックし、「Action Tips」にある「Extract text of the selected element」を選択します。
必要に応じて、フィールド名を編集します。
ステップ5:クローラーを行い、データを抽出する
「Save」をクリックして、クローラーの設定を保存します。それから、「Start Extraction」をクリック、クローラーを行い、以下のようにデータを取得しました!CSV、Excelなどの形式で出力できます。
いかがでしたか?簡単にデータを取得できますね!皆さんもお試してみてください。

※コメント投稿者のブログIDはブログ作成者のみに通知されます