元記事:https://jp.scrapestorm.com/tutorial/5-paid-software-scrape-tool/
より多くの企業がデータ分析の重要さを了解していきますから、様々なスクレイピングツールが出できます。洞察力のあるビジネスマンがきっとこのスクレイピングツールの商機を外さないでしょう。今回は五つの有料なソフトウェア型スクレイピングツールを紹介しよう。
1.Mozenda
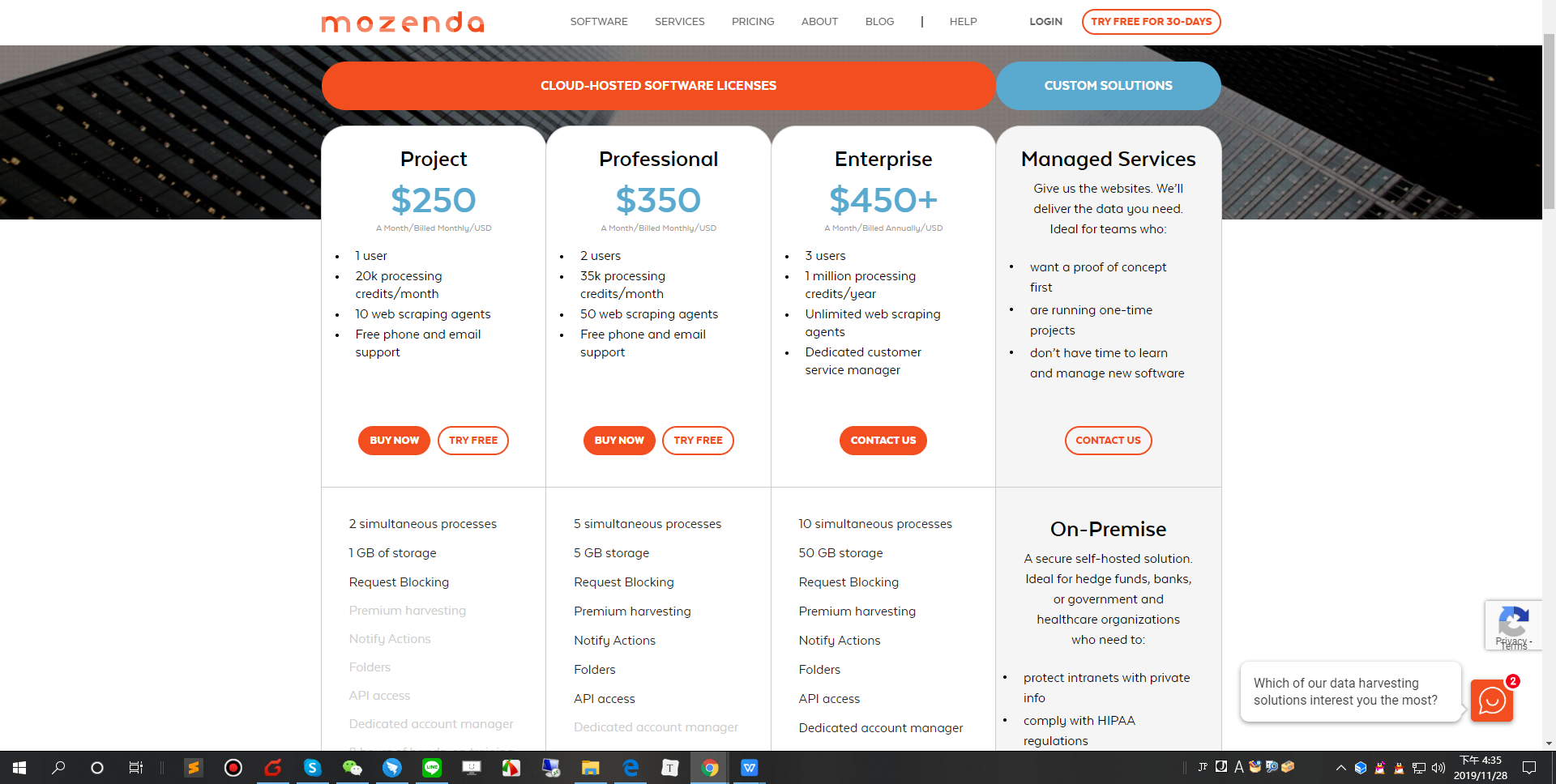
Mozendaは、ソフトウェア(SaaSおよびオンプレミスオプション)またはマネージドサービスの’形式で技術を提供します。これにより、人々は非構造化Webデータをキャプチャし、構造化形式に変換でき、企業が使いようになります。
Mozendaは以下のサービスを提供します:1)クラウドホストソフトウェア2)オンプレミスソフトウェア3)データサービス15年以上の経験を持つMozendaは、あらゆるWebサイトからのWebデータ抽出を自動化することを可能にします。
プラン:30日間の無料トライアルが提供します。
2.ScrapeStorm
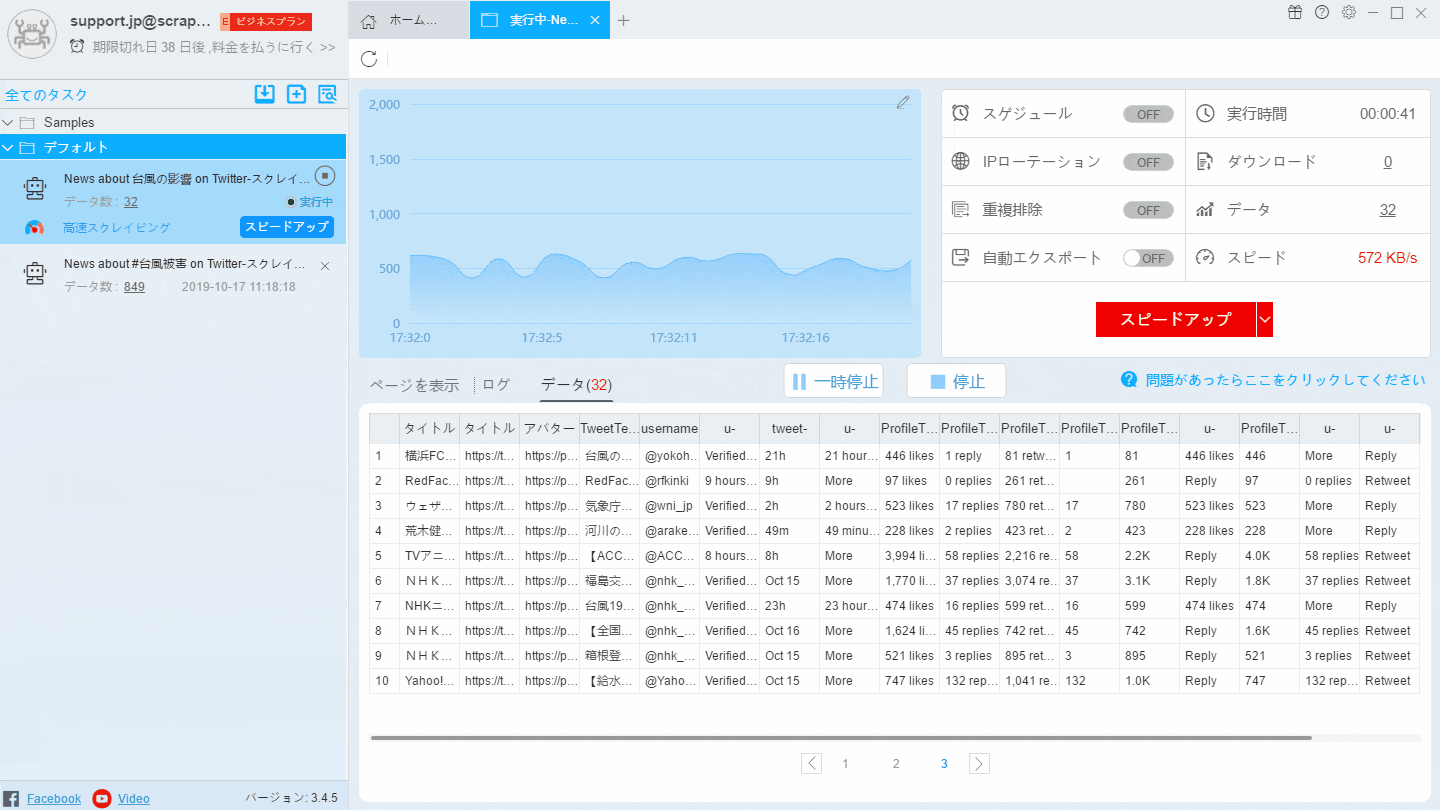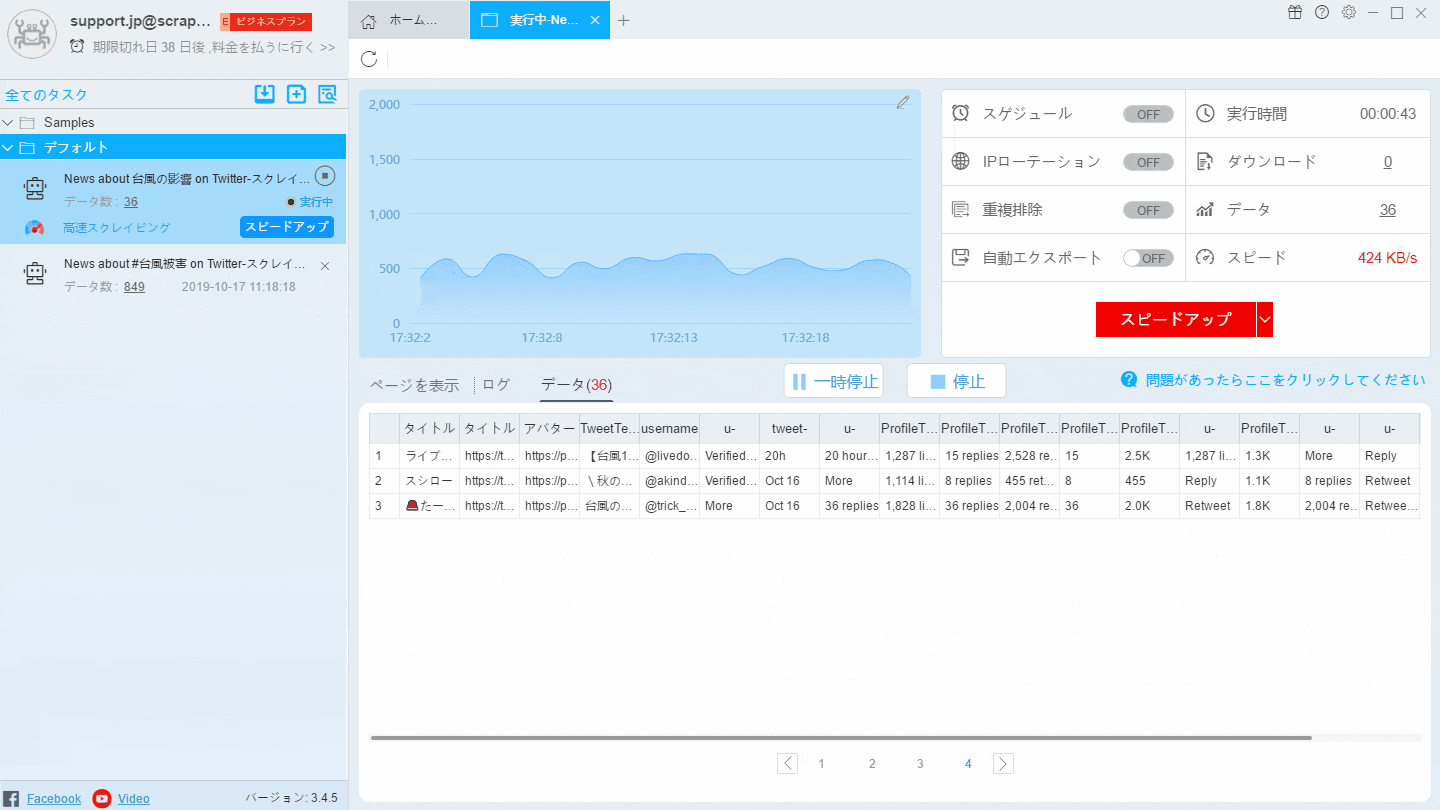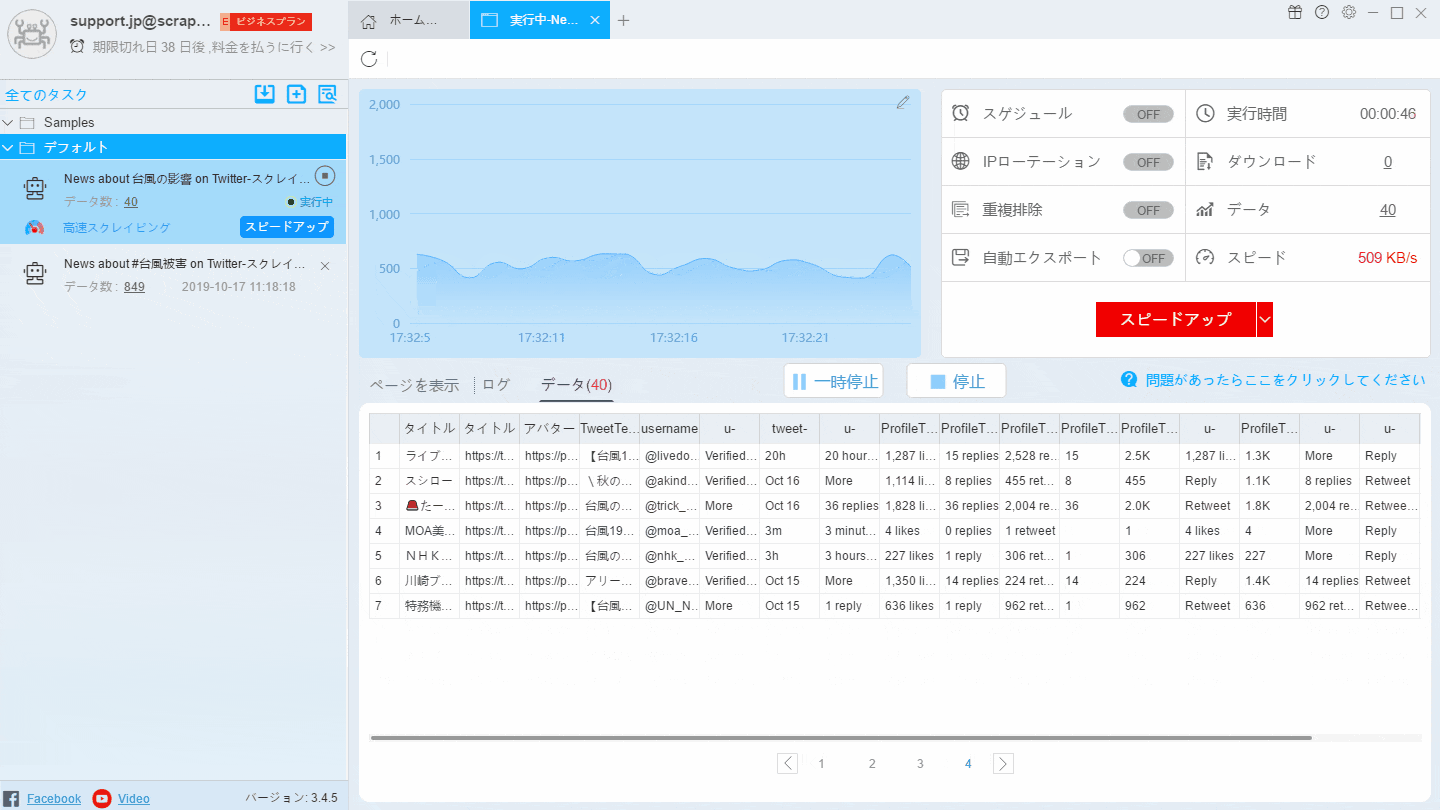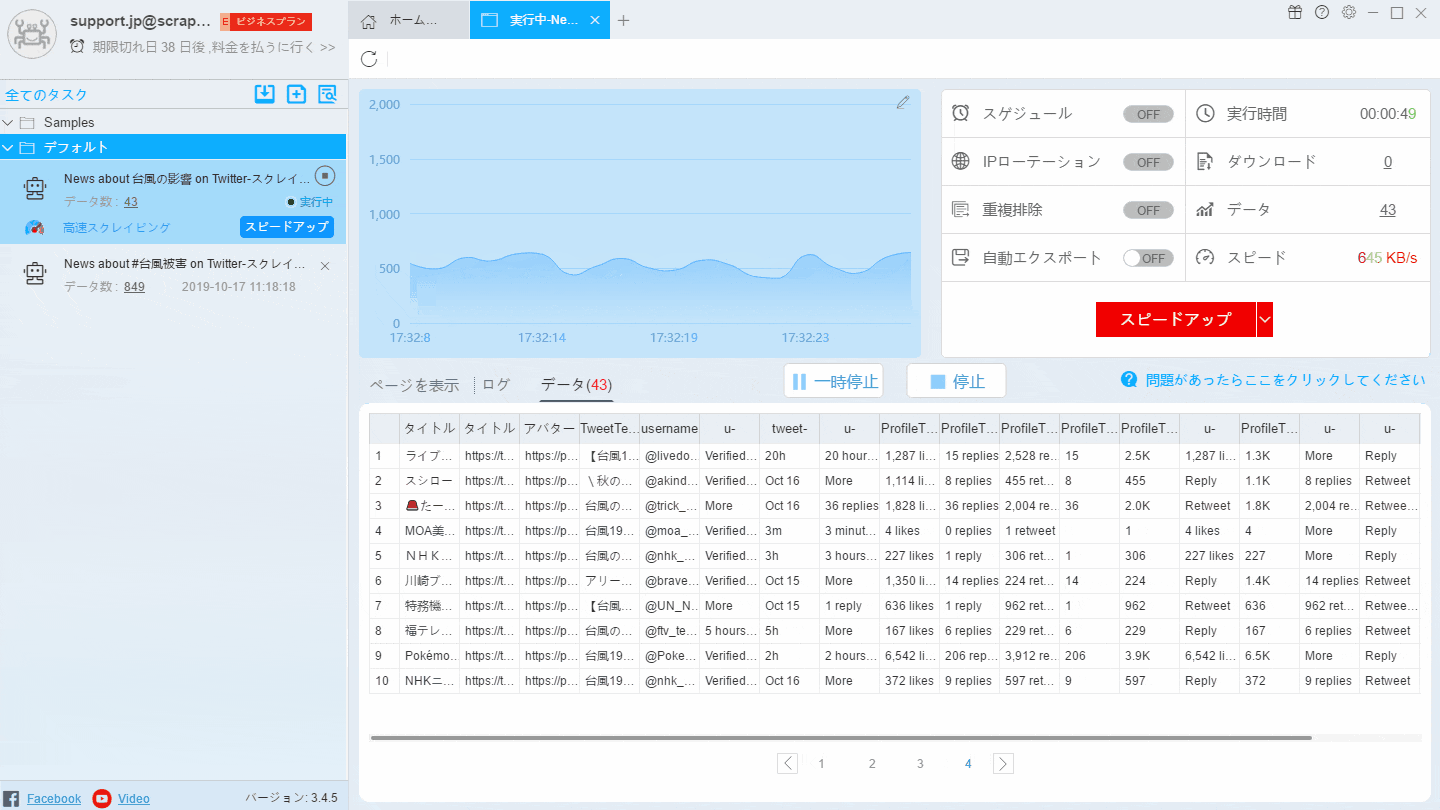
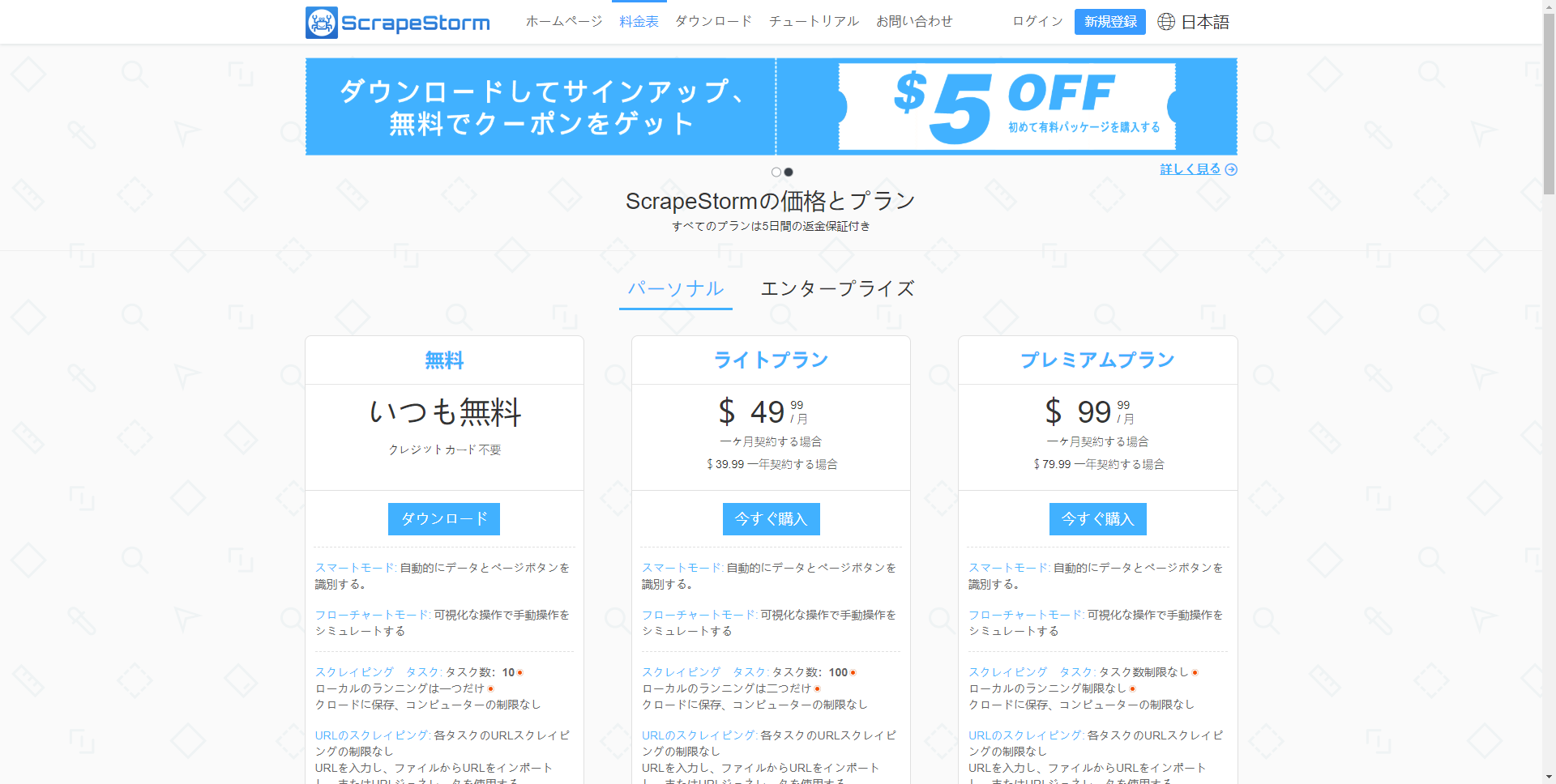
ScrapeStormは、人工知能を基づき、プログラミングしなくても、ほとんどすべてのWebサイトからデータを抽出できると言うWebスクレイピングツールです。
強い機能を持って、使いやすいです。URLを入力だけで、自動的に抽出するデータと次のページボタンを識別できます。複雑なルール設定が必要ないし、1-clickで99%のWebサイトのスクレイピング要求が満たします。
ScrapeStormは、Windows、Mac、およびLinuxに適応するソフトウェアです。Excel、HTML、Txt、CSVなどのさまざまなファイル形式で結果をダウンロードできます。 さらに、データベースやウェブサイトにデータをエクスポートできます。プラン:ソフトウェア自身はいつも無料です。有料プランには加速ブースト、スケジュール、画像のダウンロードなどの機能が提供し、効率がかなりパワーアップします。
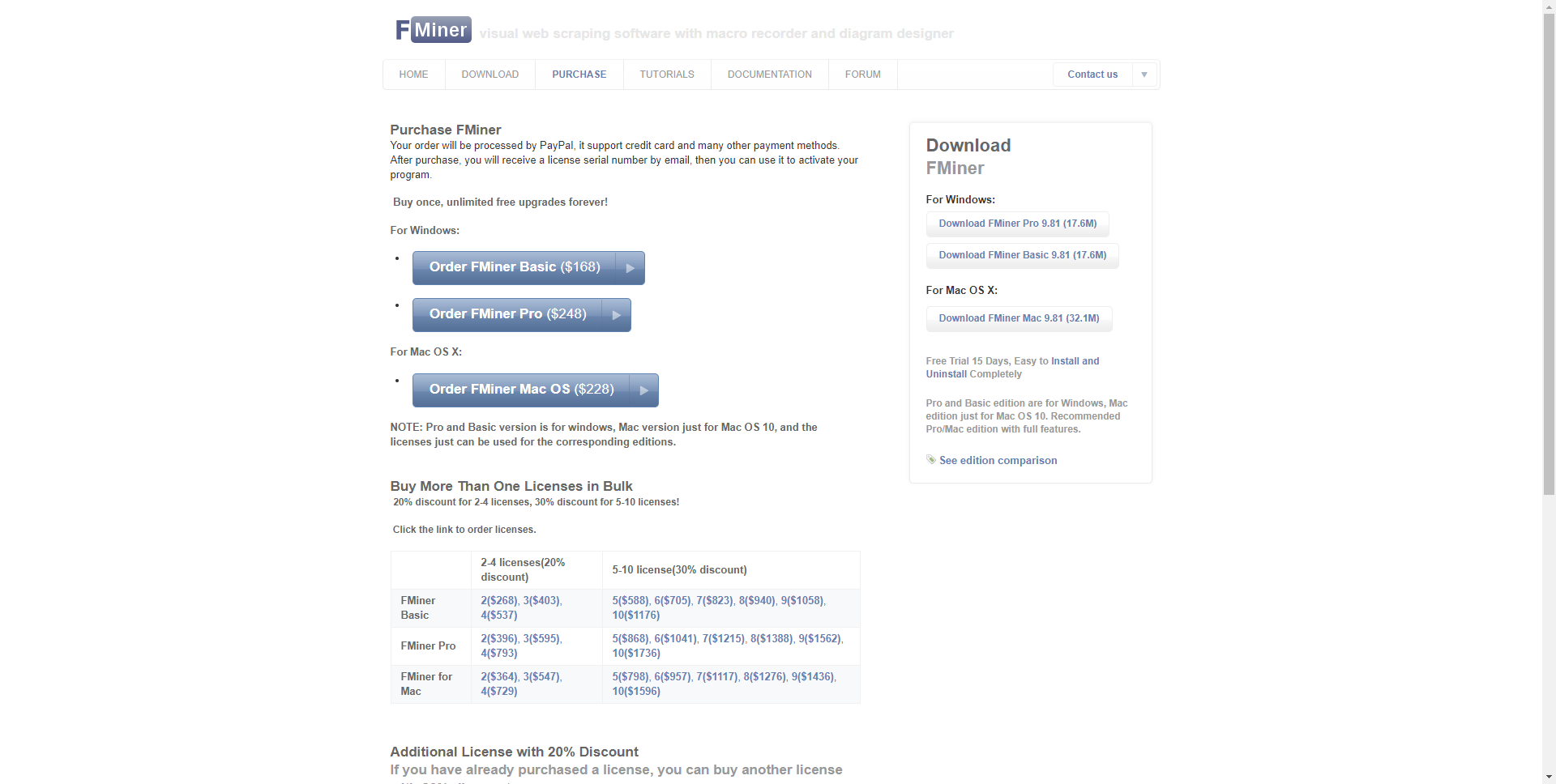
3.Fminer
FMinerは、WindowsおよびMac OS X向けのWebスクレイピング、Webデータ抽出、スクリーンスクレイピング、Webハーベスティング、Webクロール、およびWebマクロサポート用のソフトウェアです。定期的なWebスクラップタスク、またはフォーム入力、プロキシサーバーリスト、ajax処理、およびマルチレイヤーマルチテーブルクロールを必要とする非常に複雑なデータ抽出プロジェクトに直面している場合でも、Webスクラップツールです。
プラン:残念ですが、無料トライアルがありません。
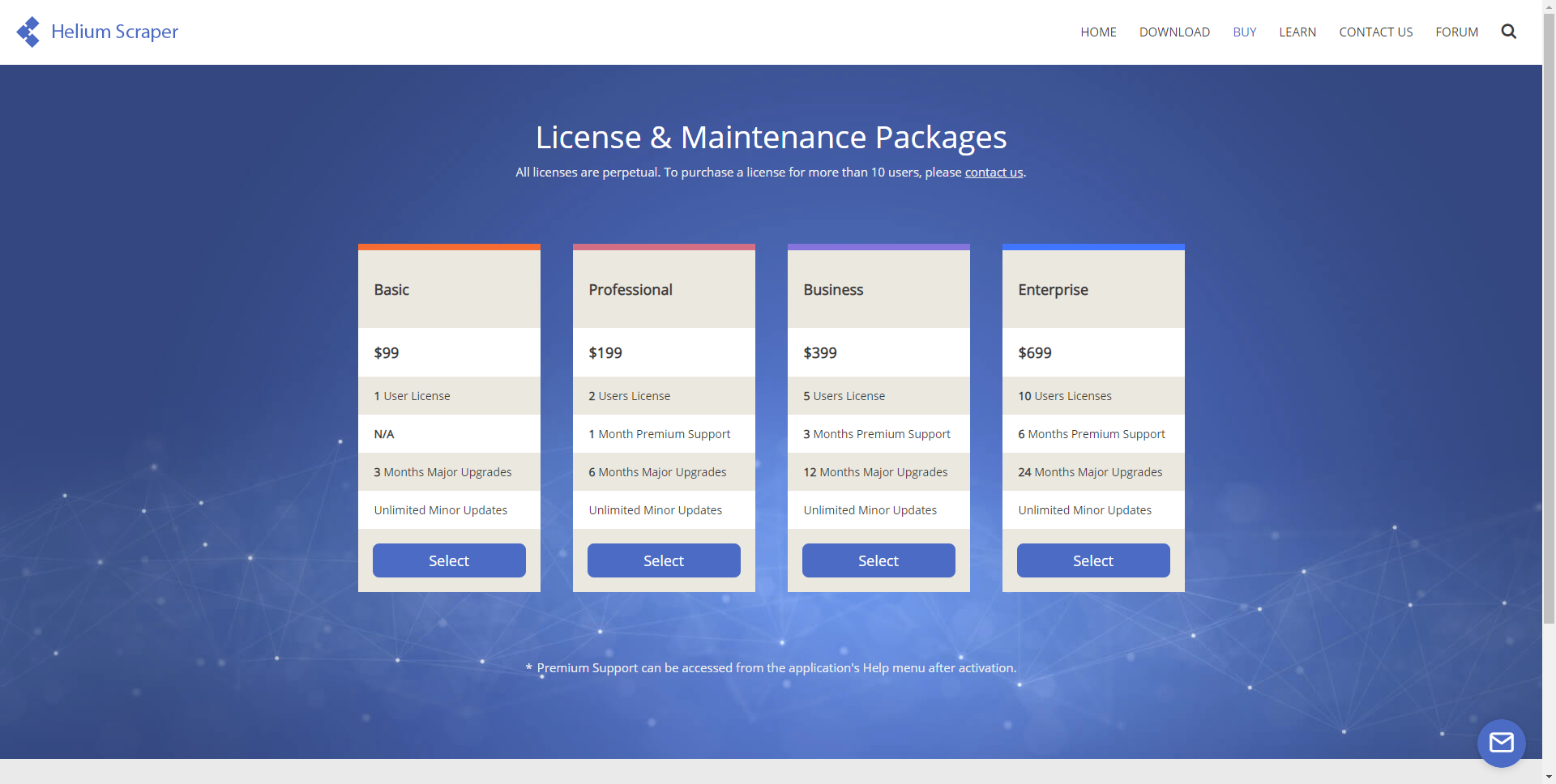
4.Helium Scraper
Windows向けのスクレイピングソフトウェアです。CefSharpを組み込みブラウザーとして使用し、多くの並列オフスクリーンブラウザーを実行でき、最小限の言語を使用できるWebスクレイパーと、すぐに使用できるウィザードを使用して抽出エージェントを構成します。
プラン:10日間の全機能無料トライアルを提供します。
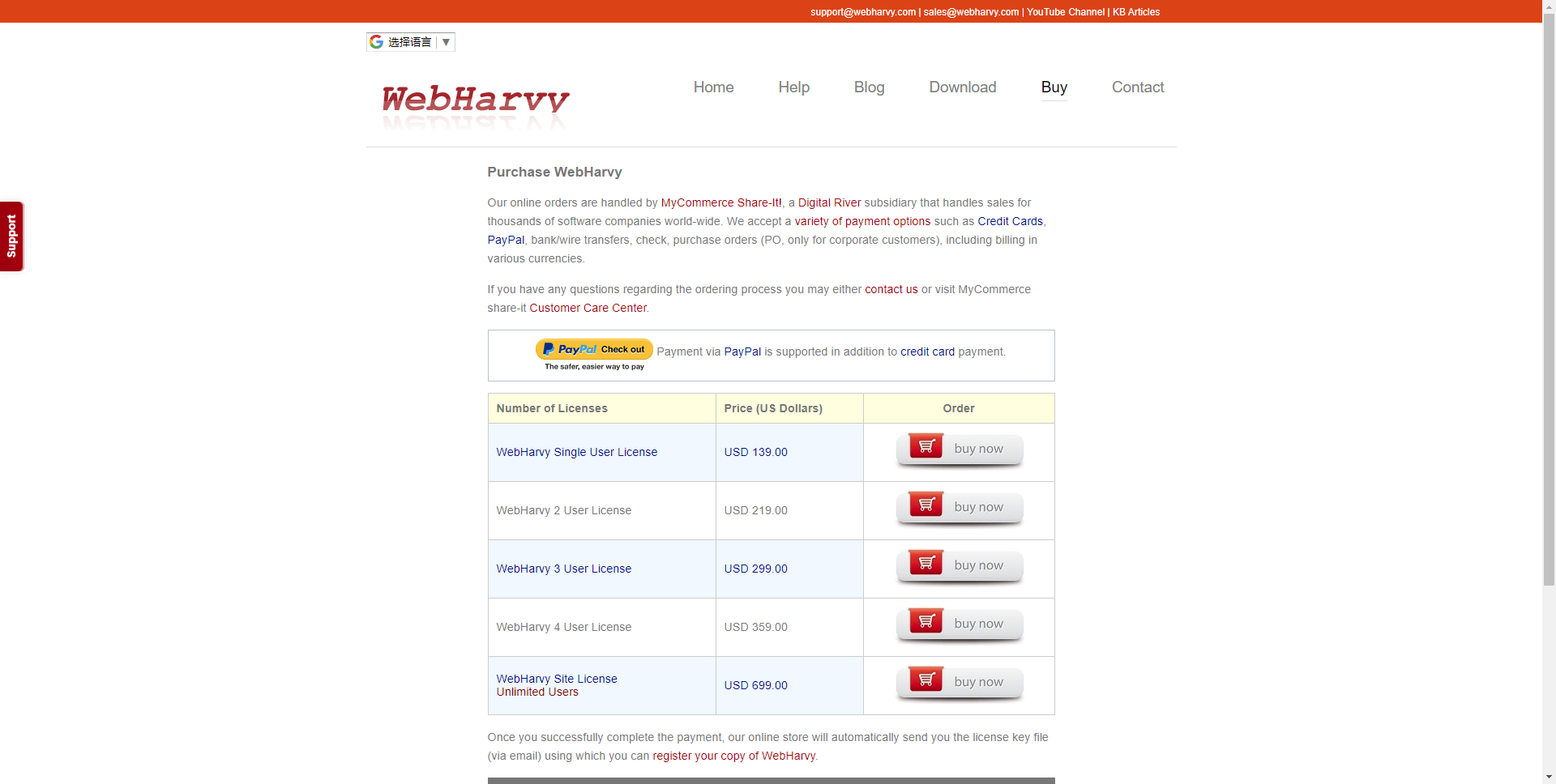
5.WebHarvy Web Scraper
WebHarvyは、Webページで発生するデータのパターンを自動的に識別します。 そのため、Webページからアイテムのリストを取得する必要がある場合、追加の構成を行う必要はありません。 データが繰り返されると、WebHarvyは自動的にデータをスクレイピングします。
プラン:残念ですが、無料トライアルがありません。
より多くの企業がデータ分析の重要さを了解していきますから、様々なスクレイピングツールが出できます。洞察力のあるビジネスマンがきっとこのスクレイピングツールの商機を外さないでしょう。今回は五つの有料なソフトウェア型スクレイピングツールを紹介しよう。
1.Mozenda
Mozendaは、ソフトウェア(SaaSおよびオンプレミスオプション)またはマネージドサービスの’形式で技術を提供します。これにより、人々は非構造化Webデータをキャプチャし、構造化形式に変換でき、企業が使いようになります。
Mozendaは以下のサービスを提供します:1)クラウドホストソフトウェア2)オンプレミスソフトウェア3)データサービス15年以上の経験を持つMozendaは、あらゆるWebサイトからのWebデータ抽出を自動化することを可能にします。
プラン:30日間の無料トライアルが提供します。
2.ScrapeStorm
ScrapeStormは、人工知能を基づき、プログラミングしなくても、ほとんどすべてのWebサイトからデータを抽出できると言うWebスクレイピングツールです。
強い機能を持って、使いやすいです。URLを入力だけで、自動的に抽出するデータと次のページボタンを識別できます。複雑なルール設定が必要ないし、1-clickで99%のWebサイトのスクレイピング要求が満たします。
ScrapeStormは、Windows、Mac、およびLinuxに適応するソフトウェアです。Excel、HTML、Txt、CSVなどのさまざまなファイル形式で結果をダウンロードできます。 さらに、データベースやウェブサイトにデータをエクスポートできます。プラン:ソフトウェア自身はいつも無料です。有料プランには加速ブースト、スケジュール、画像のダウンロードなどの機能が提供し、効率がかなりパワーアップします。
3.Fminer
FMinerは、WindowsおよびMac OS X向けのWebスクレイピング、Webデータ抽出、スクリーンスクレイピング、Webハーベスティング、Webクロール、およびWebマクロサポート用のソフトウェアです。定期的なWebスクラップタスク、またはフォーム入力、プロキシサーバーリスト、ajax処理、およびマルチレイヤーマルチテーブルクロールを必要とする非常に複雑なデータ抽出プロジェクトに直面している場合でも、Webスクラップツールです。
プラン:残念ですが、無料トライアルがありません。
4.Helium Scraper
Windows向けのスクレイピングソフトウェアです。CefSharpを組み込みブラウザーとして使用し、多くの並列オフスクリーンブラウザーを実行でき、最小限の言語を使用できるWebスクレイパーと、すぐに使用できるウィザードを使用して抽出エージェントを構成します。
プラン:10日間の全機能無料トライアルを提供します。
5.WebHarvy Web Scraper
WebHarvyは、Webページで発生するデータのパターンを自動的に識別します。 そのため、Webページからアイテムのリストを取得する必要がある場合、追加の構成を行う必要はありません。 データが繰り返されると、WebHarvyは自動的にデータをスクレイピングします。
プラン:残念ですが、無料トライアルがありません。



 alt
alt





 2.gif
2.gif