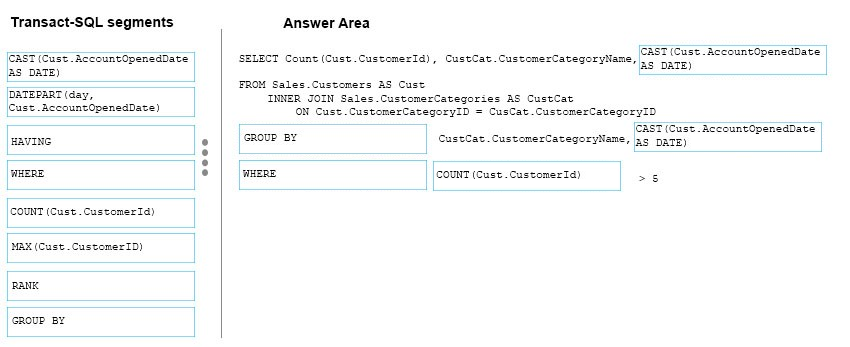
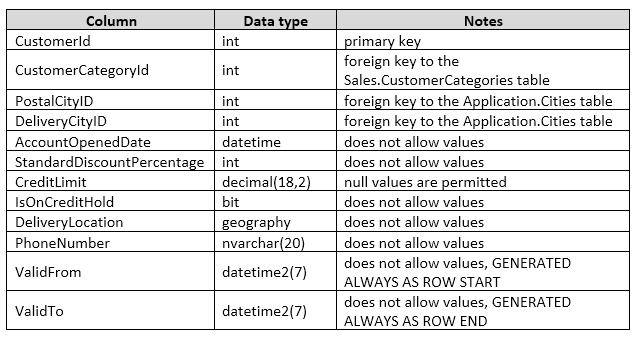
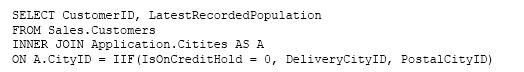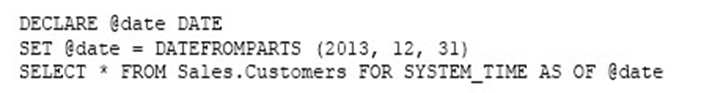LMで成功したHelloWorldのnetligy-helloworld-LargeMedia/masterはそのままのこしてある。だって、LMが成功してるからね。cfhopmkghedecay
Netlifyにはnetligy-helloworld-LargeMedia/hello02にデプロイするよう設定済み。
それから、ここ、大事。
いったん、全て設定完了して(こちらから設定見れます。)ここからがすごい!!!
gitでpushするたびに勝手にデプロイしてくれます!
では、いまから続きのお勉強します。
【続き】
先日は『LINK』まで勉強しました。https://www.gatsbyjs.org/tutorial/part-one/#linking-between-pages
おぉ、SURGEが出てきてますが、ここではNetlifyを使ってます。またSurge使えたらいいですけどね。
Netlifyだったら、上記のように勝手にデプロイしてくれます!
【Large Mediaがんばてみましょう】
前回のおさらい
さぁ、いまから1時間ほど集中してやります!
netlify login
Authorize Application
Netlify CLI is asking for permission to access Netlify on your behalf.
This app will be able to create and manage sites in your Netlify teams. You can revoke access at any time.
netlify lm:info
アップデートしてって書いてあるので、そうします。
Update available 2.19.3 → 2.20.1
npm i -g netlify-cli to update
.lfsconfig fileをチェックします。ここにイメージファイルが入ります。
[lfs]
url = https://xxxx-xxxxxx-xxxxxxx.netlify.com/.netlify/large-media
さーて、新しいイメージを入れていみようか。
1.新しいイメージファイルを用意してローカルに表示されるようにする。
起動
gatsby develop
2.Git LFSを確認
git lfs track
Listing tracked patterns
peekingcat.jpg (.gitattributes)
Listing excluded patterns
ふむ、前回のpeekingcat.jpgがちゃんと入ってる。よしよし。
では、新たにbeerneko.jpgをいれよう。
3.新しいファイルをトラックする。
git lfs track "beerneko.jpg"
git lfs track
Listing tracked patterns
peekingcat.jpg (.gitattributes) upgrade to the latest version.
beerneko.jpg (.gitattributes) upgrade to the latest version.
Listing excluded patterns
よし、入った。
ここで、NetlifyのLMサイトを確認
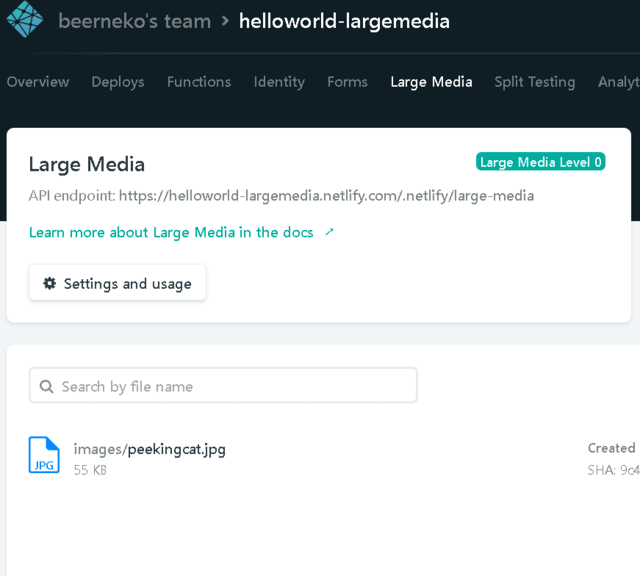
peekingcat.jpgだけです。
4.commitしてpushする。
$ git add .
npm\node_modules\netlify-cli\bin\run
ng\npm\node_modules\update\bin\update.js
$ git status
Your branch is up to date with 'origin/hello02'.
olyfilling JavaScript standard library!
Changes to be committed:
(use "git restore --staged <file>..." to unstage) n Collective or Patreon:
modified: .gitattributes
modified: src/pages/index.js
new file: static/images/beerneko.jpg
$ git commit -m "The second uploding beerneko.jpg img file"
[hello02 0c042d4] The second uploding beerneko.jpg img file
3 files changed, 5 insertions(+)
create mode 100644 static/images/beerneko.jpg
$ git push
Uploading LFS objects: 100% (1/1), 9.1 KB | 0 B/s, done
さぁ、も一回LMサイトのチェック
➞入ってない…
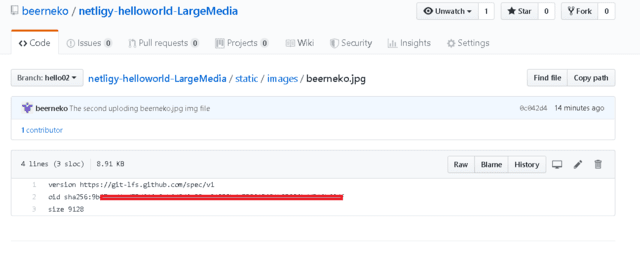
ぉぅ????Githubにはちゃんとある。。。
➞入ったぉー!!!!
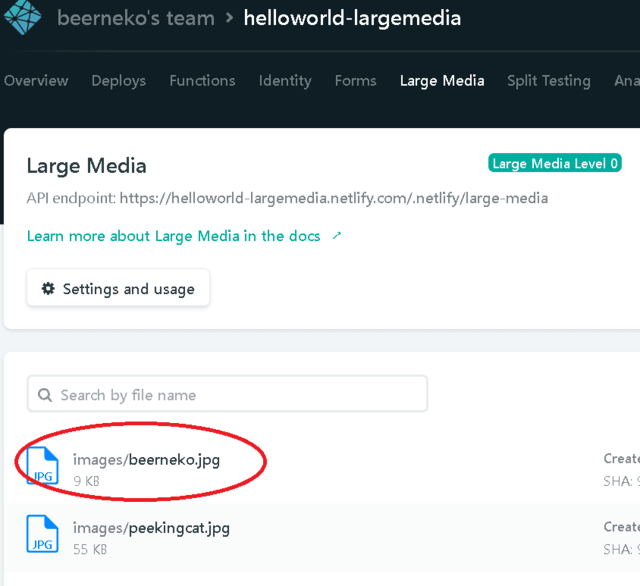
5.デプロイされてるか、チェック!
https://helloworld-largemedia.netlify.com/
うぅ、うれしい!!!
こんなに簡単だとは。
最初はどのタイミングでデプロイしてくれるのかさえ分からなかったから、セッションとかタイミングとかがっつり悪いものをつかんでやってたんでしょうね。
だから、今日の発見、『gitでpushするたびに勝手にデプロイしてくれます!』は私にとって意外と大切なんでした。もう、時間差があってもあたふたせずに、でんとまっていられる!!!
結局20分ぐらいでできた!
次は、フォームだぁ!!!PHPでやり取りできないって、あったけど。ちょっとだけ不安。
https://docs.netlify.com/forms/setup/#html-forms
よし、掃除機かけよう。
本日は今日解禁の「ターミネータ」見に行こう。
アメリカの映画館のビールってドラフトがあっておいしいのよね!!!ふっふ。