なんだか、ずっと時間がなくってちゃんとまとめてなかったですが、やっとTBC Nuggets全部見終わってノート書きます。
実際の過去問をやってから、もう一度見たので必要箇所がとってもよく分かった。
次に見るときにはテスト受かってから見たいな。テスト関係なくてもとっても役に立ちそうな内容がいっぱいありました。
【ステートメントによるパフォーマンスのあげ方】
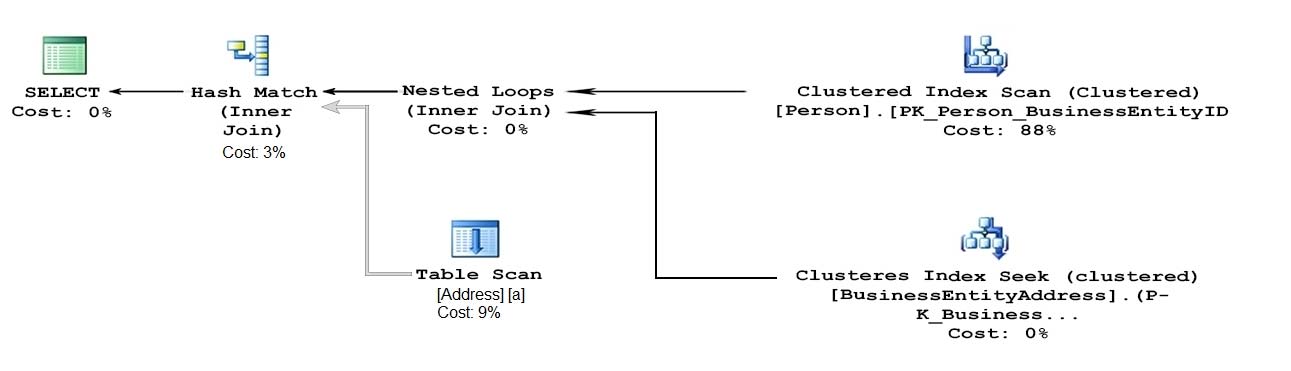
- seek is the best. second is scan, and hash. Seekが一番よい。次にScan、そしてなんもないHash。
- If there is an index, it'll be scan without where clause. Then if you want to use seek to make it faster, you need to add where clause. IndexがあればScanできる。そしてそこに『WHERE』があって、結果がしぼりやすかったらもっとパフォーマンスがあがってSeekになる。
- Use order by clustered index to make it low cost because it's already asc sort. 『ORDER BY』を使うんだったら、CLUSTERED INDEXでソートしたほうがよい。
- Altough there are correct index set, but it's still high cost becuase of aggregate (Group By). Then you want to create vew with schemabiding and the same aggregation statement alghtough you don't need to use it. also you need to create unique clustered index with View's group by column items.正しいインデックスセットはありますが、集計(グループ化)のためにコストが高くなります。 次に、schemabidingを使用してvewを作成し、同じ集計ステートメントを使用する必要はありません。 また、ビューの列ごとのグループ項目を使用して一意のクラスター化インデックスを作成する必要があります。
- Do not forget to use it's "AS" name in View. アリアス名をViewで使おう。
[モニタリングパフォーマンス]
- Perfomance monitor
- Sql server profiler
Trace in real time トレースがリアルタイムでできる。
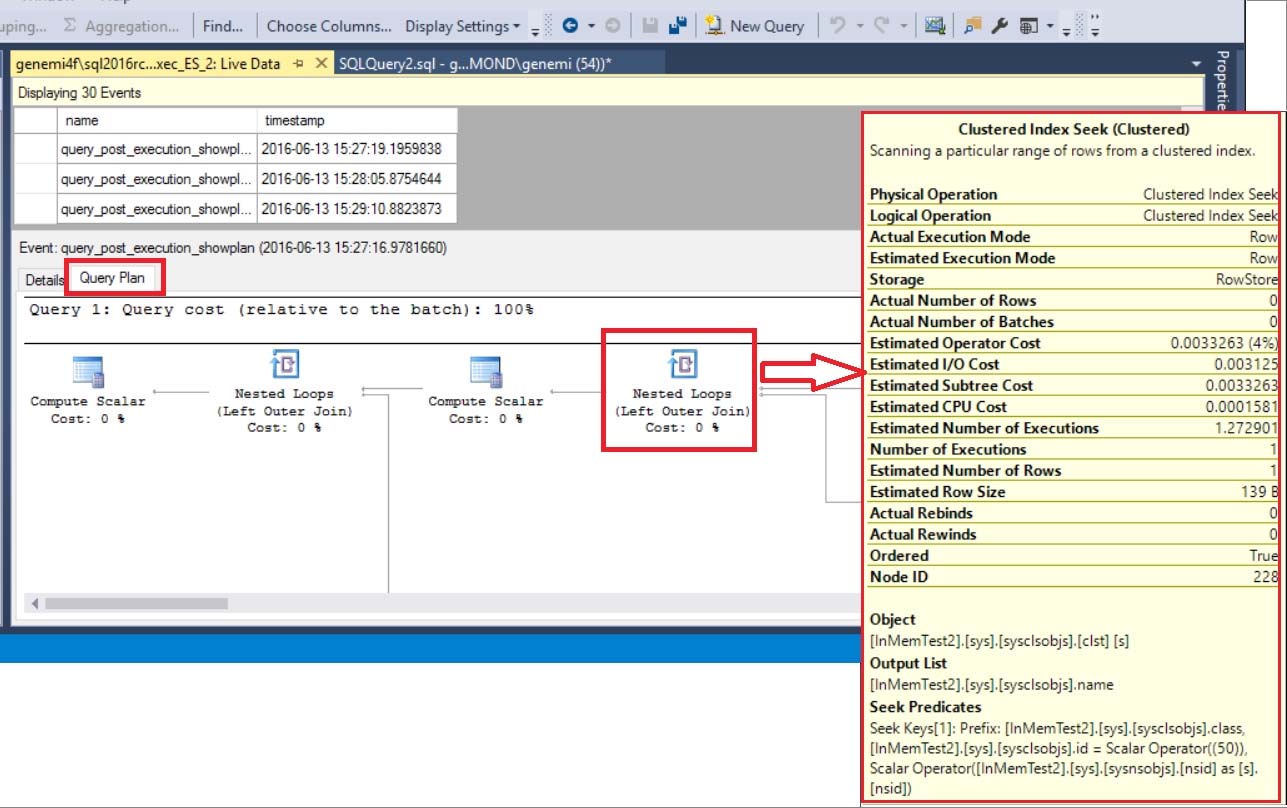
- Extended Event
chose session. セッションが選べる。
chose event イベントが選べる。
[INDEXデザイン]
- set statictic id on/offとset statistic time on/offでロジカルリードなどの詳細なメッセージがみれる。
"read 6"->"read 2"---improved
- 一番くらべたいものをNonClustered Indexにする。これはいくつもパターンが作れます。もちろん、nonkeyコラムです。
- Includeには"Select"にあるものをパターン化して一緒にいれてやる。
[Designing Views]
- Indexed Views
There is aggrigation/Join. 集計やJOINがふくまれている。
Need WITH SCHIMABINDING.
Need to create UNIQUE CLUSTERED INDEX with View's select statement. UNIQUE CLUSTERED INDEXが必要で、そこにはDesigning ViewのSelect ステートメントに含まれているものがINDEXされなければならない。
This will improve performance.
とても良い方法で、まずIndexed ViewとUnique Clustered Indexをつくる。そして、その上でNonClustered Indexを足してやるとさらにパフォーマンスが良くなる。
- Partitioned views
Use Union All
Available to do Cross-database
とても良い方法で、まずはテーブルを作る(Checkを含む)そしてPartitioned viewをUnion Allをつかって作る。そのうえで、こんな感じで値をいっぺんにいれる。
- Updateable views
Target base table only upodatable.
Need WHITH CHECK OPTION for filtering (ex. Where a = 2)
- Create a view joining both tables and showing all conlumns with WHERE and WITH CHECK OPTION statemsnt.
- Add the INSTEAD OF UPDATE statement to the view.
- Allow the application to query and update records directly for the table-values functon.
[Designing Constraints]
- table constraints
you can name whatever you want, so that it makes easy to be maintain. Otherwise column constraints name will be named by machine.
Constraints is such as "Primary Key/Forienkey" and you can set more than 2.
- colulmn constraints
check, default, not null etc.
===============
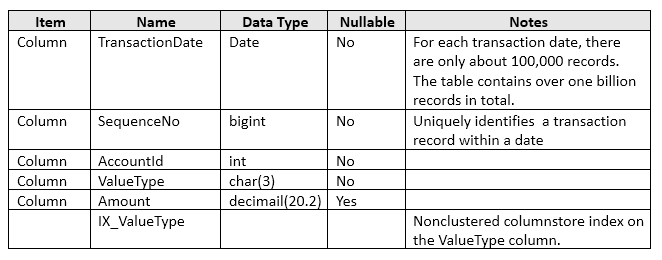
[columnstore]
http://etlpoint.com/key-differences-between-an-oltp-system-and-a-data-warehouse/
Columnstore indexes are the standard for storing and querying large data warehousing fact tables
Columnstoreは、大規模なdataware house (OLAPのこと)のFACTテーブルを格納およびクエリするための標準です
- dataware house (OLAPのこと)
Data warehouses are designed to accommodate ad hoc queries and data analysis. data warehouses are not usually in third normal form (3NF)
- OLTP
in third normal form (3NF), a type of data normalization common in OLTP environments.
- clustered columnstore index
Physical Storage for the entire tale and is the only index (Delta store)
- non-clustered columnstore index
Readd-only. Good for Anlysis qureries while the same time performing read-only operations.
[Stored Procedure]
- input/output
- error hundling
- return by conditions
- READONLY Typeを宣言するときに必要
- scope_identity() プロシージャのなかで作成された値をつかむ
- type Typeを作って、テンポラリーに値をいれ、それをプロシージャの中でつかう
- begin transact (try/catch(rollback)), commit transact
[TRIGGERS]
- good for auditing
- Instead of Insert
。たとえば、updatable viewがあって、SupplireIDの代わりにViewのなかにある直接SuplireNameをinsertするようなことがあるとしましょう。実際にUpdatableViewでつかわれているItemテーブルにはSupplireIDが必要です。なので、このupdatable viewのInsertが呼ばれた時点で、このInstead Triggerが先によばれ、Triggerの中でSupplireIDをSelectで見つけItemテーブルにSupplireIDとか、必要なコラムの値をInsertさせます。するとそのあとに実行されるupdatable viewのInsertでは、きちんとSupplireIDがそろった状態のItemテーブルでInsertすることができます。
- When Updatable View is included more than one join and needs to be insert, you can use Instead of Insert for set all needs-update-column of Updatatalbe View.
[Lock]
- Impricit transaction ON/OFF
Set Impricit Transaction ON -> @@TRANCOUNT = 1 (Lock状態で、selectではぐるぐるまわっている。) -> COMMIT TRANSACTION (manually) -> @@TRANCOUT = 0 (transaction commited)
- XACT_STATE <> 0 はオープントランザクションといういみ。
- FK relationship means that you can NOT delete or update.
-SET XACT_ABORT はタイムアウトがおきると、すべてのトランザクションを回避する。
[Isoration Level]
uncommited read -> Dirty read (Without Commit, it's shown at Select result)
Commited Read -> Default. Dirty read won't show up. まっしろけっけ。
Repeatable Read -> Can prevent Dirty read, but Phantom read.
Sirializable Read -> most pesimistic read. no dirty read, no Phontom read.
ALL_SNAPSHOT_ISORATION -> Isoration for transaction, read
READ_COMMITED_SNAPSHOT -> Isoration for statement
[Memory-Optimized Table]
1. Alter database with Filtergroup and MEMORY_OPTIMIZED_DATA, also you need to set the file locaiton and file name to filegroup
2. For create table, you need to add WITH (MEMORY_OPTIMIZED=ON) and WITH (MOMORY_OPTIMIZED=ON, DURABILITY=SCHIMA_ONLY)
3. Durability default is shcima and data is persistant after shutting down or restart. shima_only is no data persistant(temp, ETL style operation, non persistant).
[Natively-compiled stored procedure]
- Need SHCIMABINDING
- BEGIN ATOMIC WITH (TRANSACTION ISORATION LEVEL, LANGUAGE)
DURIBILITYはオン
BEGIN ATOMICのおかげで、BIGIN COMMIT がいらない。
Memory-Optimized table とくみあわせてつかう。30%ぐらい早くなる。
- Cannot use subquery.
- Cannot use NOCOUNT ON
[Implicit Transaction]
When ON, the system is in implicit transaction mode. This means that if @@TRANCOUNT = 0, any of the following Transact-SQL statements begins a new transaction. It is equivalent to an unseen BEGIN TRANSACTION being executed first:
When OFF, each of the preceding T-SQL statements is bounded by an unseen BEGIN TRANSACTION and an unseen COMMIT TRANSACTION statement. When OFF, we say the transaction mode is autocommit. If your T-SQL code visibly issues a BEGIN TRANSACTION, we say the transaction mode is explicit.
ONの場合、システムは「暗黙的」トランザクションモードになります。 つまり、@@ TRANCOUNT = 0の場合、次のTransact-SQLステートメントのいずれかが新しいトランザクションを開始します。 これは、最初に実行される目に見えないBEGIN TRANSACTIONと同等です。
OFFの場合、先行する各T-SQLステートメントは、表示されないBEGIN TRANSACTIONおよび表示されないCOMMIT TRANSACTIONステートメントによって制限されます。 OFFの場合、トランザクションモードは「自動コミット」です。 T-SQLコードが目に見えてBEGIN TRANSACTIONを発行する場合、トランザクションモードは明示的であると言います。←よってBEGIN TRANSACTION/COMMIT TRANSACTIONはない!
休憩中に武田真治さんのしくじり先生を見ました。とっても心に響きましたね。人と比べることや、比べられることにかき回され、いい人ほど完璧に期待を裏切らないようにしようと頑張りすぎちゃう。
武田さんの言う通りできない自分を認めて、自分の人生を生きなきゃね。