








【INDEXを選ぶ問題】
1.
Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables: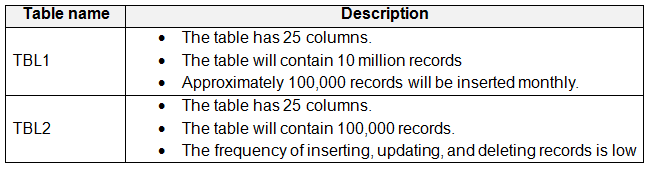
You frequently run the following queries: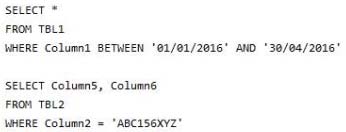
There are no foreign key relationships between TBL1 and TBL2.
You need to minimize the amount of time required for the two queries to return records from the tables.
What should you do?
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1.Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
Correct Answer: B
2.
Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables: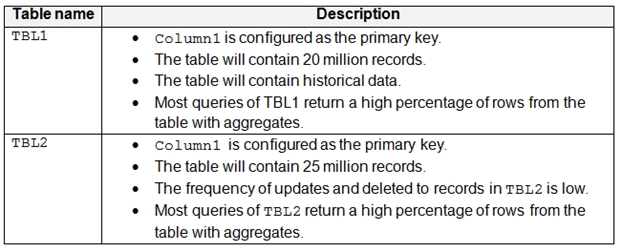
There are no foreign key relationships between TBL1 and TBL2.
You need to minimize the amount of time required for queries that use data from TBL1 and TBL2 to return data.
What should you do?
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1.Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
Correct Answer: B
References:
http://www.sqlservergeeks.com/sql-server-indexing-for-aggregates-in-sql-server/
3.
Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables:
Users frequently run the following query:
Users report that the query takes a long time to return results.
You need to minimize the amount of time requires for the query to return data.
What should you do?
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1.Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
Correct Answer: H
4.
Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables: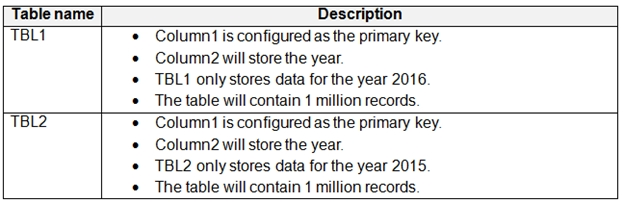
Users frequently run the following query. The users report that the query takes a long time to return results.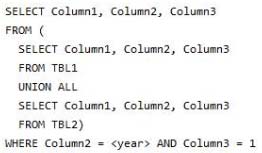
You need to minimize the amount of time required for the query to return data.
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1.Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
Correct Answer: D
A partitioned view is a view defined by a UNION ALL of member tables structured in the same way, but stored separately as multiple tables in either the same instance of SQL Server or in a group of autonomous instances of SQL Server servers, called federated database servers.
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-view-transact-sql?view=sql-server-2017#partitioned-views
5.
You have a database named DB1. The database does not use a memory-optimized filegroup. The database contains a table named Table1. The table must support the following workloads:
You need to add the most efficient index to support the new OLTP workload, while not deteriorating the existing Reporting query performance.
What should you do?
A. Create a clustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hash index on the table.
Correct Answer: C
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
References:
https://technet.microsoft.com/en-us/library/cc280372(v=sql.105).aspx
6.
Information and details provided in a question apply only to that question.
You have a Microsoft SQL Server database named DB1 that contains the following tables:
There are no foreign key relationships between TBL1 and TBL2.
You need to create a query that includes data from both tables and minimizes the amount of time required for the query to return data.
What should you do?
A. Create clustered indexes on TBL1 and TBL2.
B. Create a clustered index on TBL1. Create a nonclustered index on TBL2 and add the most frequently queried column as included columns.
C. Create a nonclustered index on TBL2 only.
D. Create UNIQUE constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
E. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Create a nonclustered index on TBL2.
F. Drop existing indexes on TBL1 and then create a clustered columnstore index. Create a nonclustered columnstore index on TBL1.Make no changes to TBL2.
G. Create CHECK constraints on both TBL1 and TBL2. Create a partitioned view that combines columns from TBL1 and TBL2.
H. Create an indexed view that combines columns from TBL1 and TBL2.
Correct Answer: G
A partitioned view is a view defined by a UNION ALL of member tables structured in the same way, but stored separately as multiple tables in either the same instance of SQL Server or in a group of autonomous instances of SQL Server servers, called federated database servers.
Conditions for Creating Partitioned Views Include:
The select list -
✑ All columns in the member tables should be selected in the column list of the view definition.
✑ The columns in the same ordinal position of each select list should be of the same type, including collations. It is not sufficient for the columns to be implicitly convertible types, as is generally the case for UNION.
Also, at least one column (for example ) must appear in all the select lists in the same ordinal position. This should be defined in a way that the member tables T1, ..., Tn have CHECK constraints C1, ..., Cn defined on , respectively.
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-view-transact-sql