








1.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the following table: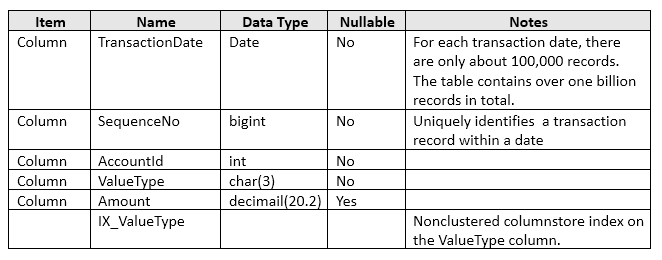
Users report that the following query takes a long time to complete.
You need to create an index that:
- improves the query performance
- does not impact the existing index
- minimizes storage size of the table (inclusive of index pages).
What should you do?
A. Create aclustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hashindex on the table.
Correct Answer: C
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
2.
You have a database named DB1. There is no memory-optimized filegroup in the database.
You run the following query:
The following image displays the execution plan the query optimizer generates for this query: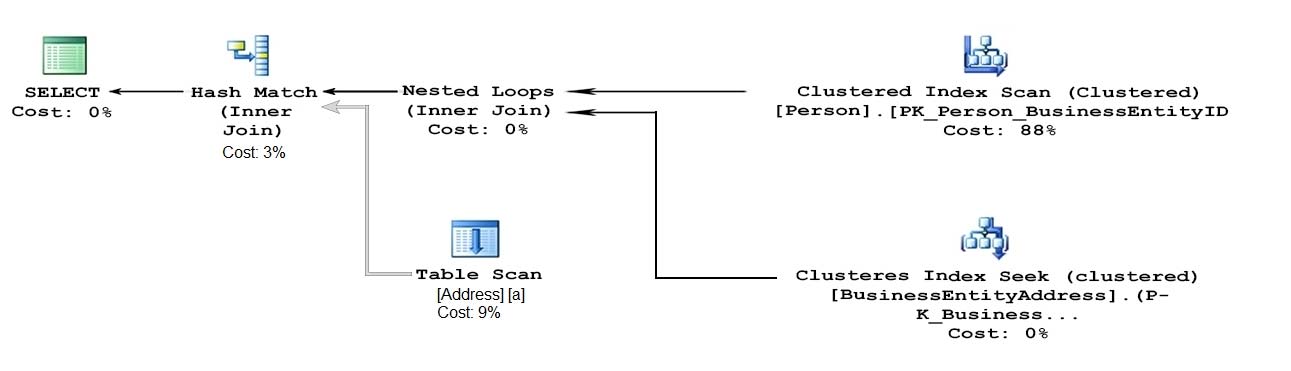
Users frequently run the same query with different values for the local variable @lastName. The table named Person is persisted on disk.
You need to create an index on the Person.Person table that meets the following requirements:
1. All users must be able to benefit from the index.
2. FirstName must be added to the index as an included column.
What should you do?
A. Create a clustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hash index on the table.
Correct Answer: B
By including nonkey columns, you can create nonclustered indexes that cover more queries. This is because the nonkeycolumns have the following benefits:
They can be data types not allowed as index key columns.
They are not considered by the Database Engine when calculating the number of index key columns or index key size.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/create-indexes-with-included-columns?view=sql-server-2017
3.
You have a reporting database that includes a non-partitioned fact table named Fact_Sales. The table is persisted on disk.
Users report that their queries take a long time to complete. The system administrator reports that the table takes too much space in the database. You observe that there are no indexes defined on the table, and many columns have repeating values.
You need to create the most efficient index on the table, minimize disk storage and improve reporting query performance.
What should you do?
A. Create a clustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hash index on the table.
Correct Answer: D
The columnstore index is the standard for storing and querying largedata warehousing fact tables. It uses column-based data storage and query processing to achieve up to 10x query performance gains in your data warehouse over traditional row-oriented storage, and up to 10x data compression over the uncompressed data size.
A clustered columnstore index is the physical storage for the entire table.
4.
You have a database named DB1. The database does not have a memory optimized filegroup.
You create a table by running the following Transact-SQL statement:
The table is currently used for OLTP workloads. The analytics user group needs to perform real-time operational analytics that scan most of the records in the table to aggregate on a number of columns.
You need to add the most efficient index to support the analytics workload without changing the OLTP application.
What should you do?
A. Create a clustered indexon the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hash index on the table.
Correct Answer: E
A nonclustered columnstore index enables real-time operational analytics in which the OLTP workload uses the underlying clustered index, while analytics run concurrently on the columnstore index.
Columnstore indexes can achieve up to 100xbetter performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes. These recommendations will help your queries achieve the very fast query performance that columnstore indexes are designed to provide.
References:
https://msdn.microsoft.com/en-us/library/gg492088.aspx
5.
You have a database named DB1. There is no memory-optimized filegroup in the database.
You have a table and a stored procedure that were created by running the following Transact-SQL statements:
The Employee table is persisted on disk. You add 2,000 records to the Employee table.
You need to create an index that meets the following requirements:
✑ Optimizes the performance of the stored procedure.
✑ Covers all the columns required from the Employee table.
✑ Uses FirstName and LastName as included columns.
✑ Minimizes index storage size and index key size.
What should you do?
A. Create a clustered index on the table.
B. Create a nonclustered index on the table.
C. Create a nonclustered filtered index on the table.
D. Create a clustered columnstore index on the table.
E. Create a nonclustered columnstore index on the table.
F. Create a hash index on the table.
Correct Answer: B
6.
You run the following Transact-SQL following statement:
Customer records may be inserted individually or in bulk from an application.
You observe that the application attempts to insert duplicate records.
You must ensure that duplicate records are not inserted and bulk insert operations continue without notifications.
Which Transact-SQL statement should you run?
A. CREATE UNIQUE NONCLUSTERED INDEX IX_Customer_Code ON Customer (Code) WITH (ONLINE = OFF)
B. CREATE UNIQUE INDEX IX_CUSTOMER_Code O Customer (Code) WITH (IGNORE_DUP_KEY = ON)
C. CREATE UNIQUE INDEX IX Customer Code ON Customer (Code) WITH (IGNORE DUP KEY =OFF)
D. CREATE UNIQUE NONCLUSTERED INDEX IX_Customer_Code ON Customer (Code)
E. CREATE UNIQUE NONCLUSTERED INDEX IX_Customer_Code ON Customer (Code) WITH (ONLINE = ON)
Correct Answer: B
IGNORE_DUP_KEY = { ON | OFF } specifies the error response when an insert operation attempts to insert duplicate key values into a unique index. The
IGNORE_DUP_KEY option applies only to insert operations after the index is created or rebuilt. The option has no effect when executing CREATE INDEX, ALTER
INDEX, or UPDATE. The default is OFF.
Incorrect Answers:
ONLINE = { ON | OFF } specifies whether underlying tables and associated indexes are available for queries and data modification during the index operation. The default is OFF.
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-index-transact-sql?view=sql-server-2017
7.
You are developing a database reporting solution for a table that contains 900 million rows and is 103 GB.
The table is updated thousands of times a day, but data is not deleted.
The SELECT statements vary in the number of columns used and the amount of rows retrieved.
You need to reduce the amount of time it takes to retrieve data from the table. The must prevent data duplication.
Which indexing strategy should you use?
A. a nonclustered index for each column in the table
B. a clustered columnstore index for the table
C. a hash index for the table
D. a clustered index for the table and nonclustered indexes for nonkey columns
Correct Answer: B
Columnstore indexes are the standard for storing and querying large data warehousing fact tables. It uses column-based data storage and query processing to achieve up to 10x query performance gains in your data warehouse over traditional row-oriented storage.
A clustered columnstore index is the physical storage for the entire table.
Generally, you should define the clustered index key with as few columns as possible.
A nonclustered index contains the index key values and row locators that point to the storage location of the table data. You can create multiple nonclustered indexes on a table or indexed view. Generally, nonclustered indexes should be designed to improve the performance of frequently used queries that are not covered by the clustered index.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-server-2017


※コメント投稿者のブログIDはブログ作成者のみに通知されます