








ActivePerl で書いてみたエラトステネスの篩。
と、ネットで調べてみるともっと短いスクリプトを発見。
grep で、倍数を消してる?さっぱり分からんけど、間違ってはなさそう。悔しいので速度比較をしてみた。
Erat_1 がネットから拾ってきたスクリプト。Erat_2 が私の書いた奴
表示部分はメインではないので省略。(join が早いのは分かってますが、まぁ、それは置いといて)
おぉ、俺の書いた方が 10倍ぐらい早い。push や、shift の配列操作、剰余の計算が重い感じですかねぇ?
って、剰余求めたらエラトステネスの篩じゃない気がする。割り算使っちゃ駄目でしょ。←気づくのが遅い。
そして、100000000 まで求めようとするとネットで調べた方はメモリーを 3G 程使ってまだ足らないと、落ちてしまいました(>_<)
私が書いた方は動いて、99999989 がその中で最大の素数と出ました。メモリの使い方も違いがあるのですねぇ。
正規表現のエラトステネスのふるいを発見。メモリーは使わないですが...鬼のように遅い! (Erat_3)
と、2万までの素数を30秒で何回求められるか試したら、
配列 & 剰余 : 32.57秒で1714回 / 1秒間に 52.62回
私の書いたの: 32.37秒で 4572回 / 1秒間に141.24回
正規表現 : 35.60秒で 1回 / 1秒間に 0.03回
# perl
use strict;
use warnings;
# エラトステネスの篩 (Sieve of Eratosthenes)
my $MAX = 10000000;
my @Prime = ();
for (my $i = 2 ; $i <= sqrt($MAX) ; $i++){
# マークが付いていたら (=素数でなかったら) 次へ
if (defined($Prime[$i])){next;}
# 素数の倍数にマークを付ける
for (my $j = 2 ; $MAX >= ($i * $j) ; ++$j ){
$Prime[$i * $j] = 1;
}
}
# マークされていない素数を表示する
for (my $i = 2 ; $i <= $MAX ; ++$i){
if(!defined($Prime[$i]) ){
print "$i,";
}
}
use strict;
use warnings;
# エラトステネスの篩 (Sieve of Eratosthenes)
my $MAX = 10000000;
my @Prime = ();
for (my $i = 2 ; $i <= sqrt($MAX) ; $i++){
# マークが付いていたら (=素数でなかったら) 次へ
if (defined($Prime[$i])){next;}
# 素数の倍数にマークを付ける
for (my $j = 2 ; $MAX >= ($i * $j) ; ++$j ){
$Prime[$i * $j] = 1;
}
}
# マークされていない素数を表示する
for (my $i = 2 ; $i <= $MAX ; ++$i){
if(!defined($Prime[$i]) ){
print "$i,";
}
}
と、ネットで調べてみるともっと短いスクリプトを発見。
grep で、倍数を消してる?さっぱり分からんけど、間違ってはなさそう。悔しいので速度比較をしてみた。
Erat_1 がネットから拾ってきたスクリプト。Erat_2 が私の書いた奴
# perl
use strict;
use warnings;
use Benchmark qw/timethese cmpthese/;
# エラトステネスの篩 (Sieve of Eratosthenes)
my $MAX = 10000000;
my $results = timethese( 1,{
Erat_1 =>
sub {
my $x = $MAX;
my @numbers = (2 .. $x);
my @prime_numbers;
while(1){
if($numbers[0] > sqrt $x){
push @prime_numbers, @numbers;
last;
}
my $number = shift @numbers;
push @prime_numbers, $number;
@numbers = grep { $_ % $number != 0 } @numbers;
}
},
Erat_2 =>
sub {
my $x = $MAX;
my @Prime = ();
for (my $i = 2 ; $i <= sqrt($x) ; $i++){
# マークが付いていたら (=素数でなかったら) 次へ
if (defined($Prime[$i])){next;}
# 素数の倍数にマークを付ける
for (my $j = 2 ; $x >= ($i * $j) ; ++$j ){
$Prime[$i * $j] = 1;
}
}
},
});
cmpthese $results;
use strict;
use warnings;
use Benchmark qw/timethese cmpthese/;
# エラトステネスの篩 (Sieve of Eratosthenes)
my $MAX = 10000000;
my $results = timethese( 1,{
Erat_1 =>
sub {
my $x = $MAX;
my @numbers = (2 .. $x);
my @prime_numbers;
while(1){
if($numbers[0] > sqrt $x){
push @prime_numbers, @numbers;
last;
}
my $number = shift @numbers;
push @prime_numbers, $number;
@numbers = grep { $_ % $number != 0 } @numbers;
}
},
Erat_2 =>
sub {
my $x = $MAX;
my @Prime = ();
for (my $i = 2 ; $i <= sqrt($x) ; $i++){
# マークが付いていたら (=素数でなかったら) 次へ
if (defined($Prime[$i])){next;}
# 素数の倍数にマークを付ける
for (my $j = 2 ; $x >= ($i * $j) ; ++$j ){
$Prime[$i * $j] = 1;
}
}
},
});
cmpthese $results;
表示部分はメインではないので省略。(join が早いのは分かってますが、まぁ、それは置いといて)
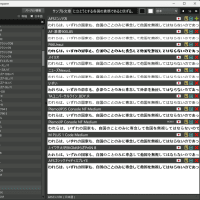
Benchmark: timing 1 iterations of Erat_1, Erat_2...
Erat_1: 57 wallclock secs (56.39 usr + 0.08 sys = 56.47 CPU) @ 0.02/s (n=1)
(warning: too few iterations for a reliable count)
Erat_2: 5 wallclock secs ( 5.82 usr + 0.11 sys = 5.93 CPU) @ 0.17/s (n=1)
(warning: too few iterations for a reliable count)
s/iter Erat_1 Erat_2
Erat_1 56.5 -- -90%
Erat_2 5.93 853% --
Erat_1: 57 wallclock secs (56.39 usr + 0.08 sys = 56.47 CPU) @ 0.02/s (n=1)
(warning: too few iterations for a reliable count)
Erat_2: 5 wallclock secs ( 5.82 usr + 0.11 sys = 5.93 CPU) @ 0.17/s (n=1)
(warning: too few iterations for a reliable count)
s/iter Erat_1 Erat_2
Erat_1 56.5 -- -90%
Erat_2 5.93 853% --
おぉ、俺の書いた方が 10倍ぐらい早い。push や、shift の配列操作、剰余の計算が重い感じですかねぇ?
って、剰余求めたらエラトステネスの篩じゃない気がする。割り算使っちゃ駄目でしょ。←気づくのが遅い。
そして、100000000 まで求めようとするとネットで調べた方はメモリーを 3G 程使ってまだ足らないと、落ちてしまいました(>_<)
私が書いた方は動いて、99999989 がその中で最大の素数と出ました。メモリの使い方も違いがあるのですねぇ。
正規表現のエラトステネスのふるいを発見。メモリーは使わないですが...鬼のように遅い! (Erat_3)
my $MAX = 20000;
my $results = timethese( -30,{
Erat_1 =>
sub {
...snip...
},
Erat_2 =>
sub {
...snip...
},
Erat_3 =>
sub {
grep { (1 x $_) !~ /^(11+)\1+$/ } (2..$MAX);
},
});
cmpthese $results;
my $results = timethese( -30,{
Erat_1 =>
sub {
...snip...
},
Erat_2 =>
sub {
...snip...
},
Erat_3 =>
sub {
grep { (1 x $_) !~ /^(11+)\1+$/ } (2..$MAX);
},
});
cmpthese $results;
と、2万までの素数を30秒で何回求められるか試したら、
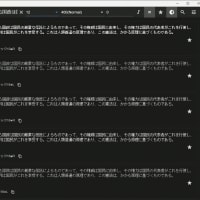
Benchmark: running Erat_1, Erat_2, Erat_3 for at least 30 CPU seconds...
Erat_1: 33 wallclock secs (32.56 usr + 0.02 sys = 32.57 CPU) @ 52.62/s (n=1714)
Erat_2: 33 wallclock secs (32.37 usr + 0.00 sys = 32.37 CPU) @ 141.24/s (n=4572)
Erat_3: 36 wallclock secs (35.60 usr + 0.00 sys = 35.60 CPU) @ 0.03/s (n=1)
(warning: too few iterations for a reliable count)
Rate Erat_3 Erat_1 Erat_2
Erat_3 2.81e-002/s -- -100% -100%
Erat_1 52.6/s 187228% -- -63%
Erat_2 141/s 502721% 168% --
Erat_1: 33 wallclock secs (32.56 usr + 0.02 sys = 32.57 CPU) @ 52.62/s (n=1714)
Erat_2: 33 wallclock secs (32.37 usr + 0.00 sys = 32.37 CPU) @ 141.24/s (n=4572)
Erat_3: 36 wallclock secs (35.60 usr + 0.00 sys = 35.60 CPU) @ 0.03/s (n=1)
(warning: too few iterations for a reliable count)
Rate Erat_3 Erat_1 Erat_2
Erat_3 2.81e-002/s -- -100% -100%
Erat_1 52.6/s 187228% -- -63%
Erat_2 141/s 502721% 168% --
配列 & 剰余 : 32.57秒で1714回 / 1秒間に 52.62回
私の書いたの: 32.37秒で 4572回 / 1秒間に141.24回
正規表現 : 35.60秒で 1回 / 1秒間に 0.03回


※コメント投稿者のブログIDはブログ作成者のみに通知されます