








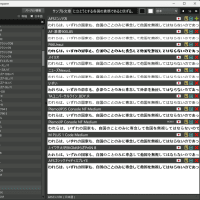
IMAP の日本語フォルダーをデコードするには IMAP 仕様の UTF-7 (RFC 2060 セクション 5.1.3) をデコードする必要がある。
by ruby
by PHP
by perl
by VBS
もっとわからん。
UTF-7 らしいことは分かったが、どうやってデコードすりゃいいんだ?
大体、VBS で文字コード変換なんてファイルに落とさないと駄目だし...
(;_;)
*utf7tosj.VBS (vector)
UTF-7 TO sjis のライブラリ。どうせなら、UTF-7 to UTF-8 が欲しかったかも。
Unicodeの概略を理解する
そうなんですか。「UTF7-IMAP = UTF-7 に『変形 Base64』をしたもの」と思ったら、「UTF-7 = UTF-16 を Base64 処理した物」だったんですね。
だから、「UTF7-IMAP = UTF-16 に『変形 Base64』処理をした物」だと。
UTF-32 = UCS2 を、最短で 1文字が 32bit に収まるよう変換した物。
UTF-16 = UCS2 を、最短で 1文字が 16bit に収まるよう変換した物。
UTF-8 = UCS2 を、最短で 1文字が 8bit に収まるよう変換した物。(漢字は 3bytes。アルファベットは 1byte)
なるほど、UCS2 が基準になってそれを UTF-x にしてるということですか。
じゃぁ、Base64.VBSにちょっと手を加えれば UTF7-IMAP ==> UTF-32 は出来るんですね。
じゃぁ、スクリプトは UTF-8 で書いて、
メール本文 EUC_JP --> SHIFT_JIS --> UTF-8
ディレクトリ名 UTF7-IMAP --> SHIFT_JIS --> UTF-8
となるのかな? やっぱり、SHIFT_JIS で書くのは避けたいからねぇ。
しかし、吉岡 照雄さんすごい
by ruby
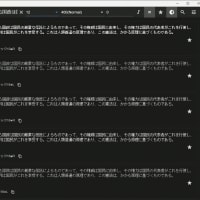
% ruby -r net/imap -e 'puts Net::IMAP.decode_utf7("&ZeVnLIqe-")'
文字コードは何になって出てくるんだ?by PHP
mb_convert_encoding($str, "SJIS-MS", "UTF7-IMAP");
MS 互換の Shift_JIS へ変換します。by perl
use Encode;
use Encode::IMAPUTF7;
$a = "&ZeVnLIqe-";
print encode('EUC-JP', decode('IMAP-UTF-7', $a));
こんな感じ。別途自分でEncode::IMAPUTF7 をインストールすること。use Encode::IMAPUTF7;
$a = "&ZeVnLIqe-";
print encode('EUC-JP', decode('IMAP-UTF-7', $a));
Encode::from_to($a, 'IMAP-UTF-7', 'EUC-JP');
print $a;
でも可。print $a;
by VBS
もっとわからん。
UTF-7 らしいことは分かったが、どうやってデコードすりゃいいんだ?
大体、VBS で文字コード変換なんてファイルに落とさないと駄目だし...
(;_;)
*utf7tosj.VBS (vector)
UTF-7 TO sjis のライブラリ。どうせなら、UTF-7 to UTF-8 が欲しかったかも。
Unicodeの概略を理解する
UTF-7とは
UTF-7は、UTF-16で表したUnicodeをBase64で変換して表す方式です。(あまり使われていない)
そうなんですか。「UTF7-IMAP = UTF-7 に『変形 Base64』をしたもの」と思ったら、「UTF-7 = UTF-16 を Base64 処理した物」だったんですね。
だから、「UTF7-IMAP = UTF-16 に『変形 Base64』処理をした物」だと。
UTF-32 = UCS2 を、最短で 1文字が 32bit に収まるよう変換した物。
UTF-16 = UCS2 を、最短で 1文字が 16bit に収まるよう変換した物。
UTF-8 = UCS2 を、最短で 1文字が 8bit に収まるよう変換した物。(漢字は 3bytes。アルファベットは 1byte)
なるほど、UCS2 が基準になってそれを UTF-x にしてるということですか。
じゃぁ、Base64.VBSにちょっと手を加えれば UTF7-IMAP ==> UTF-32 は出来るんですね。
じゃぁ、スクリプトは UTF-8 で書いて、
メール本文 EUC_JP --> SHIFT_JIS --> UTF-8
ディレクトリ名 UTF7-IMAP --> SHIFT_JIS --> UTF-8
となるのかな? やっぱり、SHIFT_JIS で書くのは避けたいからねぇ。
しかし、吉岡 照雄さんすごい


※コメント投稿者のブログIDはブログ作成者のみに通知されます