グルメ漫画「美味しんぼ」の初期エピソードにこういう話がある。
スクランブルエッグ、トンカツ、ハンバーグ、カレーの4品しか食べられない男がいる。
彼の食事はこの4種類を交代に食べるだけで、そんな貧相な食生活だけの結婚生活に耐えられない、と泣きついてきた東西新聞を寿退社した元社員(女性)を山岡・栗田コンビを中心とした同僚が助ける、と言う話だ。


いや、いくら何でもこんな話があるかよ、と(笑)。いくら漫画でもこんな設定アリかい、とか呆れたモンだったが、実はこの男、作者の雁屋哲の知人で実在の人物がモデルとなってる、って話を聞いた時にはひっくり返ってた。
「そんなヤツおるんかい!」と。
事実は漫画より奇なり、だ。
まぁ、なるほどなぁ、とは思った。
犬や猫に特定のメーカーの特定の餌だけを与えて育てる、となると、その他のモノは食わなくなったりする、ってのは良く知られた事だと思う。カリカリ餌とか缶詰とか。
人間と違って犬や猫は一生同じものだけ食べてたりするわけだよな。そしてそのブツ以外を餌だとはめったに認識しない。
考えてみると、人間って「色んなモノを食う」経験によってそれらを食べ物として認識するわけじゃん?仮に、美味しんぼのこのエピソードのように、4種類しか食べなかったら、犬猫並に「この世では4種類しか食べ物として認識せん」人間が育っても不思議じゃないわけだ。
人間の・・・っつーか犬猫もそうなんだろうけど、「生育過程」ってのは「認識」を育てるには重要なんだな、って話だ。
さて、最近はコーディングスタイルの話を書いてるんだけど。
もちろんコーディングに於いて「読みづらく」より「読みやすく」書くのは重要だ。当たり前だよな。
一方、「読みやすさ」とは何か、と言う定義は結構難しい。極論これは慣れの問題だからだ。上の美味しんぼの話じゃねーけど、慣れなければどんな書式だろうと読みづらくなるのは当たり前だ。慣れなければどんな食い物でも食い物として認識しない。
プログラミングに限った話じゃないけど、例えば英語を学習するとして、日本語に「慣れてる」我々としては英語はどう考えても「難読の」言語だ。
この難読をどう克服するのか、と考えてみた時、実は「読む」より「書く」練習をした方が早い。自分が「英語を書く書式」に慣れるからこそ、他人が書いた「英文と言う書式」に慣れるわけだ。
まぁ、この辺も本来ならもとこんぐさんの領域なんだけど。
いずれにせよ、「難読だ!」と判断する前に「練習」で「書きまくる」ってのが必然となる。「読む」前に「作る」事に慣れないと、本来の意味で「それ」が難読なのかどうかなんか分からん、って話だ。
当たり前だよな。
今回は、スクランブルエッグ、トンカツ、ハンバーグ、カレーの4品しか食べた事のない人に、5品目を提供しよう、って話だ。
さて、一般論として、だ。プログラミング言語には文(Statement)と式(Expression)と言うものが存在する。これまた厳密な定義ってのがねぇ、ってのが困ったモンだが(※1)、一般的な認識で言うと、文は「構文」(Syntax)に関連してて返り値を持たない。一方、式は広い意味での「計算」を司り、値を持つ、あるいは返す、って考えていいと思う。例外はたくさんあるみたいだけどな。
ここで「構文」ってのもまたもや難しいが、機能的には「繰り返し」とか「条件分岐」等を「構文」って捉えていいだろう。
今回は「条件分岐」の話で、一般的には、上に見た通り、条件分岐は文、に当たる。
例えば、Pythonの入門書なんかでは代表的な条件分岐文として次のような例が挙げられている。
if food == 'pizza': # 判定条件は「式」print('good') # 式elif food == 'peas': # 判定条件は「式」print('bad') # 式else:print('ok') # 式
「判定」自体は「式」だし、分岐した先で「何をするか」も通常、式が司る。
一方、その「外側」ではプログラミング言語の「機能」としてif文がある、ってわけだ。
つまり、一般的に「条件分岐が文」の場合、大枠に条件分岐が来て、そして内側のアレコレには式が入る、ってカタチになる。
ただし、これは「ポピュラーなプログラミング言語に於いて大体はそうだ」って話なだけで、「全てのプログラミング言語に於いてそうじゃなければならない」と言うような話じゃないんだ。
多分その辺を大方の人は勘違いしてる。
単にこれは「とあるプログラミング言語での」実装上の都合だ、って事だ。
一方、Lisp系プログラミング言語には文、ってのが無い(※2)。つまり、Lisp系言語に於いては条件分岐も式、と言うわけだ。
上でのPythonのようなコードは、例えばSchemeだと、
(cond ((eq? food 'pizza)
(display 'good))
((eq? food 'peas)
(display 'bad))
(else
(display 'ok)))
と書いて「一般的な言語」の構造で書く事が出来る。
しかしながら、「条件分岐が式である以上」、値が返ってくる。つまり、「何度も同じdisplay」を書かなくても、displayの引数として条件分岐式を使っても構わない、って事になるわけだ。
(display
(cond ((eq? food 'pizza) 'good)
((eq? food 'peas) 'bad)
(else 'ok)))
大枠にあった「条件分岐用構文」と内枠にあった「式」の表裏がひっくり返ったようなカタチになる。
結果、「何度もdisplayを書かなくて良い」と言う事になるわけだ。
正直言うと、Lisp系言語の入門書籍でも圧倒的に前者のカタチでコードを提示してる例が多い(※3)。
そして告白するけど、僕もLispをやりだした当初は前者のスタイルでしか「書けなかった」んだ。書籍に書いてたスタイルは前者のスタイルだったからそれを「盲信」してた。
ところが、僕の蒙昧を晴らしてくれた人がいた(※4)。それでビックリしたんだよな。「こんな書き方が可能なのか!」と。
僕が当初Lispに痺れたのは、バカみたいだけど、「必要があれば」条件分岐をどこに入れても構わん、ってトコだったんだ。つまり「構文的な制限が無い」。
理屈さえ合ってれば「動いてくれる」と言うLispのパワーを垣間見た瞬間だった。「プログラミング言語Xに特有な構文が」理屈を邪魔する事が無かったわけだ。
繰り返すけど、Lispに触れた最初の段階で「C言語脳じゃない人に会った」事は滅茶苦茶ラッキーだったんだよ。そして「やっていいこと」が増える事が快感だった。
上の「美味しんぼ」の例で言うと、初めてラーメンを喰ったんだわ。そして「美味ぇ!」と感動した。

C言語脳だったらとかく制限してくるし、フツー、プログラミング言語って「計算ロジックと関係ないトコで」邪魔してくるからな(笑)。
さて、と言う事は、「とある言語に初めて触れる際」には、いわゆる条件分岐みたいな「構文」が、文なのか式なのかチェックするのは非常に重要だ、って事になる。
そして、条件分岐が式だった場合、「記法の自由度」が滅茶苦茶上昇するんだ。これは覚えておいた方がいいだろう。
例えばRustの条件分岐は式だ。従って次のような記述を許容する。
println!("{}",
if food == "pizza" {
"good"
} else if food == "peas" {
"bad"
} else {
"ok"
})
まぁ、人に依っては「(式スタイルでも文スタイルでも)どっちでもエエんちゃうの?」って言うかもしんない。
でも個人的に言うと、後者のスタイルを支持する。その根本的な理由は後述するけど、取り敢えずタイピング量を減らしたいの法則、ってのを言っておく。
Lispハッカー、ポール・グレアムは次のように言っている。
高レベル言語を作る主要な理由はソースコードを小さくすることだ。
つまり、原則としては、ある高レベル言語にある機能があって、それがソースコードを小さく出来るのなら使うべき、なんだ。
「条件式」が必ず外側にあって、println!を何度か書かなければならない、よりprintlin!を打つ数を減らした方がソースコードは小さくなる。
結果、それは実のことを言うと「可読性を上げてる」んだよ。一つの関数が小さくなれば全体的なプログラムのソースコードは「おっかなく見えない」。
ポール・グレアムが書いてる通りだ。プログラムの「たった一行がおっかなく見えない」方を取るのか、全体的に見た時に「おっかなく見えない」方を取るのか。
個人的には、仮に一行が難解に見えても「1関数が不必要にデカい」事の方が「よりおっかない」んだよ。1関数が不必要にデカいと「ソースコード全体の流れ」もよりつかみにくくなる。
仮に1関数がデカくても一行がおっかなくない方がいい、って人は多分僕とは趣味が合わないと思う(笑)。この辺を突き詰めると、やっぱ「可読性」は個人の資質が大きいんだろうな、って話だ。乳派なのか尻派なのか、ってのは永遠に分かり合えないからな(笑)。繰り返すが、俺は尻派だ(爆
いずれにせよ、一行が分かりやすい、ってのと関数が小さくてソースコード全体の流れが分かりやすい、ってのは残念ながらある程度のトレードオフの関係がある、と言える。
さて、次のような問題を考えてみよう。
初項a0、公比r、項数nの等比数列の和の公式、をプログラミングせよ。ただし、r = 1の場合は等比数列の和はとなる。


この問題は、単純に言うと公比rが1かそうじゃないか、の場合分けで、条件分岐が文、であるPythonのようなプログラミング言語だと、この問題の解は通常こう書くだろう。
def geometric_sum(a0, r, n):
if r == 1:
return a0 * n
else:
return a0 * (r ** n - 1) / (r - 1)
ところが、Lisp的に考えると、そもそも「return a0 * 」って部分は全く共通なんで同じことを二回書くのはダサい、って考えるわけだ。
すなわち、括り出せるんなら括りだしてしまいたい。
Lispのような条件分岐が式の言語なら当然次のように書いちゃう。
(define (geometric-sum a0 r n)
(* a0 (if (= r 1)
n(/ (- (expt r n) 1) (- r 1)))))
当然、Lispのように条件分岐が式であるRustでもこのように書くべきだ。
fn geometric_sum(a0: i32, r: f32, n: i32) -> f32 {
a0 as f32 *
if r == 1.0 {
n as f32
} else {
(r.powi(n) - 1.0) / (r - 1.0)
}
}
Rustでは型変換が煩いが(※5)構造はLispのコードと同じだ。
つまり、Rustも「タイピング量を減らしたいの法則」を素直に適用出来るプログラミング言語、と言える。
一方、Pythonでも同構造でプログラムを書けなくはない。
と言うか、Pythonは条件分岐文以外に条件式、と言う機能をまた別に持ってる、ってわけだ。
Pythonの条件式は次のような書式となる。
結果1 if 条件1 else 結果2 if 条件2 else ... else 結果n
これを利用すれば、「等比数列の和」はPythonでは次のように記述出来る。
def geometric_sum(a0, r, n):
return a0 * (n if r == 1 else
(r ** n - 1) / (r - 1))
Lisp等の関数型言語や、Rustの観点から言うとPythonのように「同じ機能を文と式で2つ持ってる」ってのは何とも無駄に思えるんだけど、Pythonの場合は「折衷案」が中心として設計されているんで致し方ない。
さて、上の「等比数列の和」の例を見てみると、果たして、「条件分岐式」と言う発想はC言語脳が言う通り難読なんだろうか?
「違う」と思って欲しいトコなんだけど、ちと例を挙げてみる。
この記事で扱った例を再度見てみよう。

断言してもいいけど、C言語エキスパートはこんなコードは書かない。しかしC言語脳なら書く。それでC言語脳は教育現場で「汚いコードを書く」事を学生に教授しまくるわけだ。いい迷惑だ(笑)。
それはさておき、こんなprintf塗れのコードを書くくらいだったらPythonではこう書ける、って例を出した。

うん、確かに「うわぁ・・・」って思うだろ(笑)。
俺も思う(笑)。
ただし、「難読か」と言われると、「意味が分かる」って以上難読ではないんだ。
じゃあ、何故に「うわぁ・・・」って思うのか、っつーとだ。まぁ、元々のC言語のプログラムの「書き方がマズい」ってのが一つ。それとPythonはC言語で言うswitchもRacketで言うcaseも持ってない。
Pythonは最近(3.10で)パターンマッチ文は出来たけど、それはやっぱ「文」であり「式」ではない。
っちゅー事はprintを何度も書きたくなければ条件式で書かざるを得ないし、と言うこたぁ、判定でわざわざ x == 何とか、と検査せなあかん。
つまり、その辺の構文の脆弱性、言い換えるとまたもや何度も同じ事を書かなアカン、ってぇんで「うわぁ・・・」ってなるわけだよな。
繰り返す。printを何度も書きたくなく、それを避けたのに今度は x == 何とか が出て来たわけ。あちらを立てればこちらが立たずだったわけだな。
そしてもう一つ重要な事を書こう。何故にC言語脳が「三項演算子」的な記述を避けるのか。
実の事を言うと、上のPythonプログラムのような構造をC言語で書く事も出来るんだ。
ただし、だ。
見た目はこうなる。

Pythonでは「うわぁ・・・」だったけどC言語だったら「うわぁ、うわぁ・・・」だ(笑)。確かに「何じゃこりゃ?」だろう(笑)。Lispじゃないのにカッコ塗れだ(笑)。
そう、確かにC言語だと難読になるんだよ。
この難読の理由は2つある。
1つ目はC言語の三項演算子は
条件 ? 結果1 : 結果2
と言う書き方なんだけど、'?'とか':'と言う記号が使われてて「視覚ノイズ」にしか見えない事。
2つ目は「三項演算子」と言う名前の通り、上の「書き方」を見ても分かるけど、項を原則3つしか書けないわけだ(条件と結果1と結果2の3つ)。
つまり、複数の条件と複数の結果を書く際には結果2を「入れ子」にせなアカン、って事になる。
この「入れ子」が邪魔なんだ。
要は、printfを何度も書きたくない、って動機だった筈なのに、()と?と:を書きまくるハメになって、結果記述コストが増えている。省略記法の筈が省略記法になってないんだわ。
これがC言語の三項演算子の限界で、見た目の悪さに繋がり、三項演算子がC言語脳に嫌われる理由だ。
ここで重要な事を言っておく。仮に"?"とか":"と言う記法を受け入れたにせよ、3項しか取れない、って機能がそもそもショボい。
そう、実は何かが難読化する一番の原因ってのはその使ってるプログラミング言語のとある機能がショボい、って事に由来するんだ。
逆に言うと、ある機能が高機能だったら難読か難読じゃないかは慣れの問題になる。
Lisp/Rustなら条件分岐は式なので、それら言語に習熟してれば「難読だ」なんて感想は出てこない。出て来たとしたら単に練習不足、って話になる。
Pythonの条件式はLisp/Rustの条件分岐よりショボい。よってLisp/Rustで書いたコードよか「読みづらく」なるわけだ。
そしてC言語の三項演算子はこの中で機能が一番ショボいし書式が視覚ノイズ塗れだ。だからこれら言語の中では一番「難読」になる。
逆に見てみると、C言語である機能が「難読」だからと言って、それよりも高機能のプログラミング言語では必ずしもそれに似た機能が「難読」にはならん、って事だ。
当たり前だよな。
C言語の三項演算子はやっぱ名前が表す通り、原則「項は3つまで」しか想定してない、って事なんだよ。
実際C言語では、上の方にある「等比数列の和」程度だったら、Rustに比べても簡潔にソースコードを記述出来る。
#include <math.h>
double geometric_sum(int a0, double r, int n) {
return a0 * (r == 1 ? n : (pow(r, n) - 1) / (r - 1));
}
実際、Rustよりシンプルに書ける、ってのはC言語が弱い性的静的型付け言語だから、っちゅう別の理由なんだけど、いずれにせよ、分岐が2つ程度だったらコード自体はシンプルになるから、これは設計者の想定通りの正しい使い方だ、って事になる。
ところが分岐が2つより大きくなると途端にC言語の三項演算子は難読化する。要は機能がショボい、っつーかC言語の三項演算子は限定的な使い方しか想定してなかった、と言う設計上の失敗、って見た方がいいんだ。
そしてC言語脳はコーディングスタイルが滅茶苦茶だ(上のswitch文とprintf塗れのコードを見ろ)。と言う事はいつ三項演算子を使うべきでいつ使わないようにすべきか、って指針も無いんだろう。
だから下手に使われてコードが(ただでさえ滅茶苦茶なのに余計)滅茶苦茶になるくらいだったら禁止した方がいい、って話になる。
良くあるよな。良識がある人ばっかだったらわざわざ何かを禁止するように明文化した法律を作らなくていい筈なんだけど、バカが多ければ明文化した何かを禁止するような法律を作らざるを得ない、と。
そういう事だ(笑)。
この、Lisp/Rustの条件分岐式やPythonの条件式を使うコツ、ってのは条件分岐を書いた際に「何が共通項目で"括り出せる"のか」をいっつも自問する事だ。
ある意味「パズルを解く」のに凄く似てる。どうやってプログラム本体大枠自体の「節」を減らせるか、ってのはアタマの体操だ。
何度か言ってるけど、脳生理学的にはプログラミングは大して脳の「論理」領域は使わんらしい。代わりに「パズルを解いてる時に興奮する部分」が励起する、との事。
要は、プログラマはパズルを解くのが好きならしく、このテの話が嫌いな人は基本的にはいない筈だ。
逆に言うと、こういう「何が共通項目で括り出せるのか」と言う話でコーフンせんヤツはプログラミングに実は向いてない、って事だろう。
上では等比数列の和、と言う数学公式をサンプルとして「共通項目を括りだす」と言う例を見てみた。
他の例として、BMI(ボディマス指数)を見てみよう。
定義自体はWikipediaを参照して欲しいが、良くあるプログラミング初心者向けの課題なんかで、条件分岐文の例題に挙げられる事も多い。
プログラム初心者が書くようなコードは、Pythonだと次のようになるだろう。

C言語脳は特に、無自覚に上のようなスタイルで書くし、それをプログラミング初心者に強要する。ハッキリ言うけどそれは間違っているんだ(C言語脳がこうせなアカン理由は後述する)。
Pythonなら取り敢えず文字列をreturnしとけばいい。出力は後でどーにでもなる。
ついでにメッセージを辞書型を利用して分離すると次のようになるだろう。

しかしこれでも「条件分岐文採用」なのでフツーだ。returnを何回も書いてるし、辞書(msg)の値へのアクセスも何回も書いている。
一方、条件式を使えば「小さなソースコード」になる。

頻出事項は辞書msgの値へのアクセスだ。全部そうなんで纏めて括り出せる。
結果、「与えるキー」が条件式により計算されればいいんで、条件式をキー代わりに直接与えればいいわけだ。
当然、このテの条件分岐式のオリジンであるLispでも同様の記述が可能だ。Racketならこうなる。

もちろん、Rustでもその構造のまま記述出来るが、一方、条件分岐と関係ない辺りで記述はかなりメンド臭い。
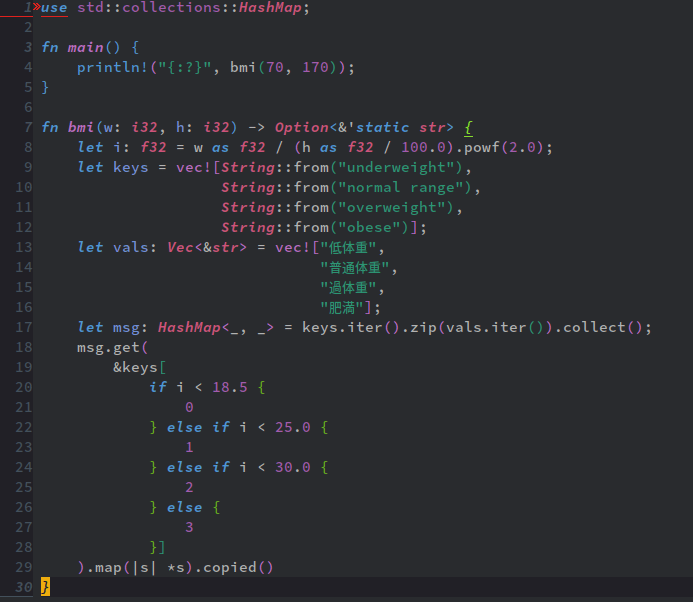
Rustのハッシュマップの使用はJavaのそれと同等くらいに面倒臭い。それはRustの「強い性的静的型付け言語」、と言う性質に拠る。結果、型変換(キャスト)が洒落にならんくらい煩わしい。
ハッシュマップの類は、キーが存在しない時に失敗を意味する値(例えば偽値等)を返すように設計されている例が多いが(※6)、これは想定した「値」の型と一致してる保証がない。例えば上の例だとキーと結び付けられた値は文字列を想定してるが、「見つからなかった場合」文字列が返るわけではないんで、型が一致しない。従って、メンド臭いハメに陥ってる。
このように、ぶっちゃけ、Rustの(と言うより性的静的型付け言語の)ハッシュマップは、動的型付け言語のそれに比べると扱いが面倒臭いんだけど、これが次の論のヒントとなる。
今まで条件分岐を大枠に置かずに、returnする「式」の共通部分を括りだして条件分岐式を内側に置く方法論に付いて書いてきた。
問題は、だ。そうそうそう上手く「共通部分」が存在するような「式」が頻出するのか、って話だ。ここに疑いを持つ人は当然多いだろう。
でも心配は要らない。実は7〜8割の確率で「共通部分が存在する」式にならざるを得ない。つまり大枠に条件分岐を置くより内側に条件分岐を置けるようなパターンの方が実際は多いんだよ。
どうしてだろ?
それは上に書いたような静的型付け言語の特性に拠るんだ。
例えばLispもPythonも動的型付け言語だ。そして「条件分岐を内側に置けない」ようなパターンの関数だと次のようなモノが考えられる。
Python:
def foo(x):
if x == 0:
return True
elif x == 1:
return 2
elif x == 2:
return 3, 4
elif x == 3:
return [1, 2, 3, 4]
elif x == 4:
return 'Hello, World!'
else:
return {'pussy': 'おめこ'}
Racket:
(define (foo x)
(cond ((= x 0) #t)
((= x 1) 2)
((= x 2) (values 3 4))
((= x 3) '(1 2 3 4))
((= x 4) "Hello, World!")
(else (hasheq 'pussy 'おめこ))))
これは明らかに「条件分岐」を外側に置かなアカンパターンだ。数値によって返すデータ型が違う。データ型が違うっちゅう事は括りだす為の共通パターンがない。
しかし、これはPythonやLisp等の動的型付け言語だから書ける関数であって、実は静的型付け言語ではこんな関数は書けないんだ。何故なら静的型付け言語では関数の返り値の型が一致してないとならない。つまり、条件分岐で多彩な型を直接返す事が出来ないんだよ(※7)。
静的型付け言語って言われると、ついつい「変数を使う際に型も合わせて宣言せなアカン言語」とか初心者に言いかねないんだけど、実は一番重要なのが関数の返り値の型なんだ。ここで型が一致せんとエラーになり、動的型付け言語に慣れてるとちょくちょく間違える。マジで。俺も良く間違える(爆
しかし、静的型付け言語で、同じ型を必ず返さなアカン、って事は返り値を計算する為に使ってる式も同じ形式である確率が極めて高いって事になるんだよ。すなわち、括り出せる共通項が自然と存在してる率が高いって事になる。
言い換えると、静的型付け言語の方が条件分岐「文」じゃなくって条件分岐「式」とむしろ相性がいいって事なんだ。それなのに、長い間そこに到達してなかったわけだよな。
RustはC言語系構文の言語だけど、そこがやっと正された、って言っていいと思う。
ハッシュマップは使いづらいが(笑)。
余談だけど、どうしてプログラミング初心者用のC言語の本なんかで、データ型を返す関数を作らせずにvoidでprintfばっかさせるのか、てぇのは、C言語脳教育者がしょーもない、って理由もあるんだけど、もう一つの理由が、「マトモな関数を書かせると」この関数の返り値の型、と言う壁が立ちはだかって、初心者にはめっちゃ難しくなる、からだ。voidで返り値が無ければprintfさせれば結果はすぐ見れるだろ?そして型の整合性に気を使う必要がない。返り値が無いから。
結果、「悪いコーディングスタイル」は初心者向けにとってはある種必然性を持ってる、って事になるわけだけど、ハッキリ言っちゃって、単に初心者にC言語、ってのが向かない、ってだけの話なんだわ(笑)。
閑話休題。
注意事項。特にPythonの条件式に付いて。
LispやRustのような完全な条件分岐式を持ってる場合は構わないんだけど、Pythonの条件式は基本複文を持てない。従って、複文が必要な操作をする場合はフツーの条件分岐文を使った方が良い、って事になる。
ただし、だ。複文が必要なケースってのはこういうパターンになる。
if 条件:あれをしてこれをしてreturn 何とやらelse:...
このパターンの場合、「あれをして」「これをして」と言うのは破壊的変更を含む副作用になるんだよ。
プロシージャの項目でも書いたけど、モダンなプログラミング手法だとそもそも副作用には頼らない。副作用に頼るプログラミングは避けよう。慣れてくればPythonの条件式でも十分使える筈だ。
特に破壊的変更はいつぞや書いたけど最適化の為の手法だ。ただし、最初から最適化を目論んでプログラムを組むのは間違ってるんだ。
最後に条件分岐を扱った例として、ちとトリビアルな例を挙げてみよう。
あるデータがあったとして、条件によって操作を変えたい、とする。
例えば今ここに2と3を含んだリストがあるとしよう。関数fooはそのリストを中に持ってるんだけど、引数が1だった時、それをリストの先頭に結合する。そうじゃない時は何もしないで、元々持ってたリストをそのまま返す、と。
そういう関数fooを書け、って問題だ。
多分条件分岐文しかなく、関数がファーストクラスオブジェクトじゃない言語しか使った事が無い人ならこういう風に書くだろう。
def foo(x):
ls = [2, 3]
if x == 1:
return [x] + ls
else:
return ls
でも、関数がファーストクラスオブジェクトな言語では無名関数が使える率が高いんで、この関数は実はこう書けてしまうんだ。
Python:
def foo(x):
return (lambda y: [x] + y if x == 1 else y)([2, 3])
Racket:
(define (foo x)
((lambda (y)
(if (= x 1)
(cons x y)
y)) '(2 3)))
Rust(※8):
fn foo(x: i32) -> Vec<i32> {
|mut y: Vec<i32>| -> Vec<i32> {
if x == 1 {
y.insert(0, x);
y
} else {
y
}
}(vec![2, 3])
}
これが「操作側」を条件によって「切り替える」手法となる。
関数がファーストクラスオブジェクトで条件分岐「式」があるなら、こういう事が可能となるわけだ。
この例だと無名関数を用いたが、別にフツーの関数でも「切り替え」する事が出来る。
Python:
def foo(x):
return (bar if x else baz)(2, 3)
def bar(x, y):
return x + y
def baz(x, y):
return x - y
Racket(※9):
(define (foo x)
((if x
bar
baz) 2 3))
(define (bar x y)
(+ x y))
(define (baz x y)
(- x y))
Rust:
fn foo(x: bool) -> i32 {
(if x {
bar
} else {
baz
})(2, 3)
}
fn bar(x: i32, y: i32) -> i32 {
x + y
}
fn baz(x: i32, y: i32) -> i32 {
x - y
}
全部、言語に従った真偽値を関数fooの引数に与える。引数が真なら5、偽だったら−1になる筈だ。
このように、条件分岐が「式」で、関数がファーストクラスオブジェクトなら「操作」側を条件によって振り分けられる。
そしてPythonだったらreturnされてるモノは fun(arg) の形式、Racketなら返り値が (fun arg)、Rustも返り値は fun(arg) の形式になってる、って事をキチンと確認しよう。条件式が入ってても「関数を使う際の書式」になってるんだ。
もうちょっと大げさな例だと、ついでにデータ側の方でさえ条件で分けられる。
Python:
def foo(x):
return (bar if x else baz)(2 if x else 9,
3 if x else 7)
Racket:
(define (foo x)
(apply (if x
bar
baz)
(if x
'(2 3)
'(9 7))))
Rust:
fn foo(x: bool) -> i32 {
(if x {
bar
} else {
baz
})(if x {
2
} else {
9
},
if x {
3
} else {
7
})
}
どれも関数fooの引数に真を与えると5になり、偽を与えると2になる筈だ。
このように共通部分が関数部分、引数部分、と2つあってもそれぞれ条件式で纏められる。バラバラに括り出せるんだ。
この例だと、どの条件式も同じ条件で切り替わるが、別々の条件で切り替える事も当然可能なんで、例えば3パターン x 3パターンなら9種の異なった計算結果が得られるだろう。バカ正直に条件分岐文で9種場合分けするよかよほど効率的だ。
しかしいくら何でもこれは・・・って思う人もいるかもしんない(※10)。いや、そう思う人が多いだろ(笑)。PythonのコードなんてもはやPythonに見えない(笑)。
おかしいな、Pythonは「どんな人が書いても同じようなコードの見た目になる」ように設計してる筈なのに(笑)。
いや、実際、「やり方は一つでいい」と言うPython哲学の割にはこう言った抜け道があるんだよ(笑)。と言うより、高級言語の宿命だ。機能がたくさんある、って事は自然と書き方が変わる事はあり得るわけ。
しかし、これらは「トリビアルな」例と書いた。つまり「書ける」と言う事を知って欲しかったわけで「使う」事を実は意図した例じゃあないんだ。
じゃあなんで紹介したのか。この形式で書く必要はない(もちろん練習自体はして欲しい)んだけど、考え方を押さえて欲しかったから、だ。
実はこの時点で、「条件分岐が何か」と言うよりも「関数がファーストクラスオブジェクトとはどういう事か」の話になっている。そして上のように「条件分岐で関数を切り替える」事が出来る、と言う「考え方」の延長線上にデータ主導/駆動形プログラミング、って手法が存在するんだ(※11)。
上の例だと切り替える関数の数はたった2つだった。しかし、3つ、4つ・・・って増えて行った際に「条件分岐を3つも4つも書くのが嫌だ」となるだろう。いや、なるべき、なんだよ。
そうすると、そこに到達した時点で、結論としては「条件分岐を消した方がマシだ」って事になる。そう、ハッシュテーブルの採用だ。ハッシュテーブルの値に関数を設定しておけば条件分岐を使わずに済む。最終的に条件分岐は消え去るんだ。
しかし、そこの発想に至る為「だけ」に、簡単でも条件分岐で関数を切り替える練習はしておいた方がいい、って話だ。だから結果はトリビアルだとしても紹介しといたわけ。
と言うわけで、今回の話はこれでおしまい。
ラーメンだけご馳走するつもりが、寿司や天ぷらまで食わしてしまったようになってるが、いずれにせよ「難読だ」と言う前に色々と自分で「形式弄って」書いてみるべきだと思う。練習を通じて「難読」はそれほど難読じゃない、って気づく結果になる事が意外と多い、ってのが分かるんじゃないか。
食わず嫌いは損するだけだ。

※1: コンピュータサイエンスの用語ってそんなんばっかだ(笑)。
つまり、「定義がハッキリしない」用語ばっか、って事で言うと定義によりコンピュータサイエンスはやっぱ「サイエンス」、つまり科学じゃないんだ(笑)。
言ったろ?実際は「理論塗れ」の科学じゃなくって社会科学とかそっちの方に実際は近い。
※2: ところが、Lisp系言語のSchemeだと式でも「値を返さない」事があり、じゃあ、これは一般文脈的には「文」に相当するのでは?と言う話が出てくるので訳が分からない。しかしANSI Common Lispではどんなブツでも「値を返す」わけで、結局、言語の仕様書での「定義次第」と言う事になって、一般論を語るのはやっぱ難しくなる。
また、通常、「出力関数」ってのは関数なんだけど、PascalやBASICの場合は出力は「文」となってて、また、Pythonも2.x時代、printは文だった。
※3: ANSI Common Lispのユーザーは圧倒的に前者のカタチで書くだろう。
一方、このテの「構文上のトリック」を好んで行うのはSchemerに多い気がする。
一般的に、構文的に「短く書けるなら書きたい」とパズル的に挑戦するのがSchemerで、一方、CLerは「そんな事せんでもマクロで・・・」とやっちゃう気がする(笑)。
同じLispに絡んでいても、CLerとSchemerはかなりプログラミングに対する態度が違うんだ。
※4: 「紫藤のページ」の紫藤貴文さん、だ。
マジで感謝してもしきれない。
※5: 実のトコ、Rustは機能的に見るとLispより関数型言語OCaml(あるいはMicrosoft F#)の方に近い。「厳密な型の適用」はC言語なんかより遥かに厳しい。小うるさく頑固な婆さんみてぇだ(笑)。
そう、Rustは「強い」性的静的型付け言語だ。
そういう意味でも同じ「強い静的型付け」言語であるPascalにもやっぱ似てる。
※6: ANSI Common Lispでの偽値は空リスト、つまりNILだ。
しかし、ハッシュテーブル上のキーに結び付けられた値が空リストじゃない、と言う保証がないわけで、そういうキーで返されたNILと「キーが見つからなかった」と言う意味でのNILの見分けが全く付かない。
そういう理由で、ANSI Common Lispのハッシュテーブル検索関数gethashは二値を返す多値関数となってて、二番目の返り値は見つかった場合はT、見つからなかった場合はNILを返すようになっている。
結果、仮に、あるキーがNILと結び付けられてた場合、返り値はNILとTの2つで、「キーと結び付けられてるNILがある」と二番目の返り値Tにより判断する事が出来る。
※7: もちろん抜け道はある。単純に言うと、多彩な型を含む新しい型を定義してそれを返すようにすればいい、と言う方策だ。しかしそのためにコーディングはクソメンド臭くなる。
Rustのハッシュテーブルから返る値を関数の返り値として使おう、と思っても素直にそれが出来ないのもこれが理由、となる。
なお例を挙げると、以前星田さんがOCamlで悩んでたヴァリアント型ってのがこの「抜け道」だ。
より正確に言うと、「OCamlにあるヴァリアント型ってLispでは何に当たるの?」って事だったわけだが、性的静的型付け言語であるOCamlだから色々と「帳尻を合わせる為に」ヴァリアント型が必要だっただけで、動的型付け言語であるLispにはそもそもヴァリアント型、なんちゅうものは必要がない、ってのが結論だった。
※8: 厳密にはこれは、PythonやRacketと同等のコードではない。Rustではベクタを破壊的変更してるから、だ。
これはあくまで無名関数と条件分岐の組み合わせの例示として捉えて欲しい。
※9: この例だと、実はRacketでは関数barとbazは作らないでいい。Lispでは+と-はそのまま関数で関数名だから、だ。
なお、ANSI Common Lispだとこのままでは上手く行かず、次のように書かなければならない。
(defun foo(x)
(funcall (if x
#'bar
#'baz) 2 3)
これはANSI Common Lispが関数用の名前空間を別に持ってる為、だ(Lisp-2と呼ぶ)。そのお陰で返り値リストの第0要素を関数名にしてもそのままだと関数としては認識されない。だからfuncallが必要になる(尤も、そのお陰でRacketよりフツーの関数呼び出しに見える)
一般に、殆どの言語だと変数も関数も同じ名前空間を使う。それをLisp-1と言う。LispじゃなくてもLisp-1と言い、C言語、Python、Racket、Rust、全てLisp-1だ。
ANSI Common Lispが殆ど唯一と言って良いLisp-2な言語となる(他にそんなんあるかどうかは知らん)。
※10: ただし、Racketの例はLisperなら「こう書ける」と言う事を皆知っている。他の言語じゃ「うげ」と思うようなやり方でもLisperなら「条件分岐が式で、関数がファーストクラスオブジェクトならこう書けるよね」と皆納得する。彼らが「そういう風に書くのを好む」かどうかは別問題として、だ。
Lisper「だけ」は「関数がファーストクラスオブジェクト」だと言う事を熟知してるんだ。それは長い間、Lisp「だけ」が「関数がファーストクラスオブジェクトの言語」だったが故、だ。そういう歴史的理由に裏打ちされている。
もう一つの理由は、殆どの人にとってLispは元々「カッコだらけの難読の言語」だからだ。
つまり、Lispの基本フォーマットは「難読」かもしれないけど、Lispの場合は、「何らかの構文上のトリック」を持ち込んでもその「難読」性は上昇しない、んだ。つまり、Lispの難読性は定数なんだ。何かやったから、っつって飛躍的に難読性が上がるわけでもない。
PythonやRustなんかで面食らうのは、「慣れ親しんだ書き方」の見え方と大きく違うから、だろう。Lispだと何やったって所詮カッコ塗れなんで「誤差の範疇に収まる」(笑)。
そんなわけで、どんな飛び道具的な書き方をしようとLispでは大した問題にならないわけだ。
※11: このページの最後でC言語に於ける「データ主導/駆動型プログラミング」の手法が説明されている。「関数ポインタの配列を使って高速化」がそれ、だ。
C言語では「高速化手法の一つ」として解説されているが、他のハッシュテーブル持ちの高級言語では必ずしもそうではない。後者の場合は「メインテナンス性の向上」が目的、となる。
しかしながら、両者の理論的バックグラウンドは実は全く同じだ。