
プロシージャの正確な定義、ってのは難しい。
ぶっちゃけ、言語に依ってプロシージャと呼んだり関数と呼んだりしてる。
例えば同じLisp系言語でも、仕様上、ANSI Common Lispでは「処理のまとまり」を関数と定義し、Schemeでは同じ「括り」をプロシージャ(手続き)と呼んでいる。
言い換えると、仕様書によって定義名が違う。
つまり、仕様書内で定義される「用語」が関数だったりプロシージャだったりするわけだ。
とは言っても、ここでは、コンピュータ・サイエンス的な「一般論」を書いておこう。
プログラミング言語としては、「関数」「プロシージャ」の両方を持ってる言語が存在する。
ALGOL系の代表格、Pascalと言う言語はそれら「関数」と「プロシージャ」を両方持ってる言語だ。
Pascalでの「3乗」を計算するプロシージャの例:
procedure cube;begin n := m * m * m end;
Pascalでの「3乗」を計算する関数の例:
function cube(m: integer): integer;begin cube := m * m * m end;
両者とも形式的には良く似てる。単純には予約語「procedure」で書き始めるとプロシージャ、「function」で書き始めると関数になるように見える。
しかし、この2つには大きな違いが一つある。
- 「関数」には返り値がある。
- 一方、「プロシージャ」には返り値がない。
ちと、Pascalの文法は今日だと異質に見えるんだけど、Pascalにはreturn文と言うのが存在しない。Pascalでは「定義した関数名に計算結果を代入する」表記で「返り値を返す」事を表す。
一般的に見られる表記:
return 計算結果
Pascalでの表記:
関数名 := 計算結果
今日だとPascalのポピュラリティはそれほどないが、変数の型を後方から修飾する、なんつーのはRustでも見られる書き方だ。
だから意外と、RustはC言語っぽい構文に見えつつ、この辺の「ルール」はPascal由来に見える(※1)。
ちなみに、結論から言うとRustではプロシージャなんぞ忘れた方がイイ。
一方、上のPascalの関数はRustでは次のような対応となる。
Pascalでの関数の例:
function cube(m: integer): integer;begin cube := m * m * m end;
Rustでの関数の例:
fn cube(m: i32 ) -> i32 {
m * m * m }
この2つの言語は見た目違うんだけど、要素的には全く同じなのが分かるだろうか。PascalでintegerはRustでi32だし、関数の返り値の型はPascalでは: integerなトコがRustでは -> i32になっている。
先ほど書いた通り、Pascalの書式上、定義した関数名に計算結果を代入すると、それが計算結果を返した事になる。
一方、RustもPascalのように明示的なreturnを持たない言語だが、行末にセミコロン(;)を置かなければ、その「計算式(この場合はm * m * m)」が返り値として返る事となる。
Pascalでのbegin〜endはRustでは{...}だ(※2)。
実は結構RustはPascalっぽい。
さて、Pascalを見ると関数もプロシージャも「記述形式は似てる」と言う事が分かるだろう。
ここでちと思いついたヤツがいるんだよな。「どうせ似たような機能なんだから纏めても良くね?」と。
それで出て来たのが、初めてってワケじゃないけど、有名なのがC言語だ。
C言語は「関数とプロシージャ」を統合した。結果、以降登場したプログラミング言語では「関数しかない」と言うのが多く、あるいは先にも書いたように、仕様書で「関数」あるいは「プロシージャ」を定義する、ってように変わってきたわけ。
C言語でプロシージャに当たるのは「void型の関数」と呼ばれるモノだ。こいつは返り値を持たないので、事実上プロシージャ、って事になる。
C言語での「3乗」を計算するプロシージャの例:
void cube(void) {
m = m * m * m;
}
C言語での「3乗」を計算する関数の例:
int cube(int m) {
return m * m * m;
}
まぁ、このブログ界隈ではC言語使いはそんないないんで、上のC言語のコードはあまりピンとこないかもしんない。
ただし、主に「C言語登場後」、関数とプロシージャの境界線は曖昧になった、と言いたかっただけ、だ。
そして構文的には「その通り」なんだけど、逆に「返り値」とか「関数の役目」ってのがPascalに比べると、特にプログラミング初学者にとっては曖昧になっていくんだ。
Rust知ってる人はいいし、C言語知ってる人もいいんだけど、いまだ関数とプロシージャって曖昧だろ?
ここで、PythonとRacketで同じ関数/プロシージャを書いてみる(※3)。そうすれば「プロシージャ」がどんな役割を担ってるのかが分かると思う。
Pythonでの「3乗」を計算するプロシージャの例:
def cube():
global m
m = m * m * m
Racketでの「3乗」を計算するプロシージャの例:
(define (cube)
(set! m (* m m m)))
Pythonでの「3乗」を計算する関数の例:
def cube(m):
return m * m * m
Racketでの「3乗」を計算する関数の例:
(define (cube m)
(* m m m))
形式的にはこの通り、となる。
ところで、実際に上のコードをPython/Racketに打ち込んでみると、関数はともかくとしてプロシージャは上手く動かなくてエラーになってるんじゃないか。
Pythonでのエラー:
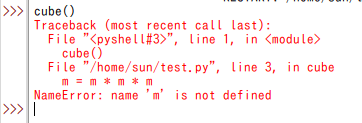
Racketでのエラー:

すわ、プログラミング間違えただろ?って思うかもしれないけど、ごめん、ワザとだ(笑)。
と言うより、モダンな言語でプロシージャが一体何を意味するのか明確にする為だ。
関数版と違って、そもそもプロシージャ版は引数がない。引数を付けてもいいけど、引数を使って計算しても返り値がない。返り値があっちゃえばそりゃそのまんま関数になってしまうし、返り値がないプロシージャだとそもそもプロシージャから値を受け渡す方法がない、って事なんだ。
どういう事か。要は、前提として大域変数があって、それを破壊的変更するのがここでのプロシージャの役目となるんだ。
Pythonでのプロシージャ:
m = 10 # 大域変数
def cube():
global m
m = m * m * m # 大域変数を書き換える
Racketでのプロシージャ:
(define m 10) ; 大域変数
(define (cube)
(set! m (* m m m))) ; 大域変数を書き換える
つまり、プロシージャは計算目的に存在するんじゃないんだ。プロシージャの存在目的は副作用なんだ。
副作用は計算じゃない。副作用には代入等の破壊的変更、入出力(※4)、ファイルの入出力、なんかがある。
- 関数は「計算」の為に存在する
- プロシージャは「副作用」の為に存在する
この、大域変数を破壊的変更する為だけにプロシージャ、ってのも何となく大げさに思うかもしんない。
いや、これには一つ理由があって、元々、例えば古のBASICなんかだとスコープ、ってのが無かったんだよ。
つまり、どっかの関数(※5)内で変数xを定義しても、どこからでも丸見えなんだ。ヌーディストビーチ状態だ(笑)。
古のプログラミング言語だと、関数A内で変数xを定義しても、プロシージャBからその変数xは丸見えになる・・・・・・結果、関数A内の変数xはプロシージャBから変更が可能だ・・・すんげぇ怖えだろ(笑)?いや、マジで大昔はそうだったんだって。
今だと関数A内にある変数xはプロシージャBからは「見えない」。これがレキシカルスコープで、そのお陰で、プロシージャがやれる事は
- ファイルを含む入出力
- 大域変数の破壊的変更
くらいしかなくなったんだ。
スコープの登場がプロシージャの「出来る事」を制限した。
んで、だ。
どんなカタチであれ、入出力に関してはプログラミング言語処理系が用意してくれてるわけなんだけど。
とすると、事実上、大方プロシージャが「やれる事」っつーのは大域変数の破壊的変更だと考えてまぁいい。
でもさ。例えば、だぜ?
1 + 2を計算して表示するプログラムを書け、って言われて、PythonやRacketでこう書こう、なんつーヤツはいない、って願いたいわけだが。
Pythonでのプロシージャの悪しき例:
m = 0 # 大域変数
def foo():
global m
m = 1 + 2 # 大域変数を書き換える
foo() # foo を実行
print(m)
Racketでのプロシージャの悪しき例:
(define m 0) ; 大域変数
(define (foo)
(set! m (+ 1 2))) ; 大域変数を書き換える
(foo) ; foo を実行
(printf "~a~%" m)
こりゃ「出来るこたぁ出来る」けど、さすがにこれはアレだろ、って思って欲しい。こんな事するなら関数として1 + 2を return した方がなぼかマシ、って結論になるだろう。
ところがだ。C言語なんかだとこういうプログラムを書かざるを得ない場合がある。代表的なトコが配列だ。
LispもPythonも代表的なコンパウンドデータ(※6)であるリストを返す事が可能なんだけど、C言語の配列は関数の返り値としては返せない(※7)。
したがって、例えば
二次方程式の解の公式をプログラムせよ
なんて問題があったとしたら、PythonやRacketじゃ以下のように書けば済むんだけど(※8)、
Pythonでの例:
def quadratic_formula(a, b, c):
from math import sqrt
return [(-b + sqrt(b ** 2 - 4 * a * c)) / 2 * a,
(-b - sqrt(b ** 2 - 4 * a * c)) / 2 * a]
Racketでの例:
(define (quadratic-formula a b c)
`(,(/ (+ (- b) (sqrt (- (* b b) (* 4 a c)))) (* 2 a))
,(/ (- (- b) (sqrt (- (* b b) (* 4 a c)))) (* 2 a))))
一方、単純にはC言語だと大域変数として配列を用意して、プロシージャがそれを破壊的変更せざるを得ない(※9)。

こういう配列の破壊的変更を伴うプロシージャ的な発想のコードばっか書いてると、いつぞや星田さんが紹介してた本のようなコードをPythonで書く、っつー愚を犯すわけだよな(※10)。
モダンな言語ではプロシージャは危険なんだ。
PythonでもRacketでもプロシージャは書ける(※11)。しかし、現代的な環境ではプロシージャに「頼らない」方が正しい。使わんに越した事がない、んだ。
そしてRust。Rustに於ける大域変数は、定数だ。つまり変更不可が基本だ。参照は許すが変更はさせない。
と言う事は、事実上、Rustではプロシージャを使うプログラミングが行えない、って事になる。
Rustは厳しい。Lispより厳しいんだ(笑)。
しかし、モダンなプログラミング手法だとRustの方針は正しいし、嫌でも引数と返り値を重要視したプログラミング法に習熟せざるを得ない。
繰り返すが、RustはC言語的にプログラミングをするどころか、むしろC言語的にプログラミングする事を厭うように設計されている。
と言うわけでプロシージャの事が分かっただろうか。
モダンな言語環境だと排する対象にまでなってきてる、ってのが2023年現在の動向、って事になってる。
R.I.P. Procedure!
※1: 違うけど(笑)。
以前チラッと書いたが、コンピュータサイエンス的には「変数の型宣言」は後方から修飾するのが正しい。つまり、C言語は実は間違ってるんだけど、この間違いのまま、アッチコッチの言語の「形式」として普及しちまった。
言い換えると、Rustは初めて、C言語系の「構文」の間違いをC言語的な見た目のクセに「正した」言語、となる。
エラい。
※2: Pascalのbegin〜endと言うのはブロックを表す。非常に長いがALGOL系だとこれが正しいブロック表記だ。
なんで波括弧({})を使わなかったんだろう?と現代の我々だと思うが、実は1960年代〜1970年代だと、ミニコン等のキーボードでは波括弧({})が存在しなかった。無いものは当然思いつきもしない(笑)。
一方、AT&Tに転がってた中古ミニコンのキーボードにはどういうわけか波括弧があった。
そこでC言語の設計者達は、begin〜endと打つのがメンドいんで代わりに波括弧を使ったというわけ。
ところが、さっきも書いた通り、実は1970年代、つまりC言語が生まれた時代の殆どのミニコンでは波括弧が無かった。言い換えると、C言語の設計者はAT&Tに転がってたミニコンだけで動けばイイ、と言う前提でC言語を開発したんだ。他の人に使ってもらう事を全く考えてなかった、と言うのがC言語の特徴で、その場凌ぎで自分たちだけで使えりゃエエや、ってプログラミング言語が広まってアチコチで使われるようになった、ってのは皮肉な事だ。
いずれにせよ、C言語の色々とマズい設計はすべてこの極私的動機に由来する。
※3: 実際はPythonでは、3乗を計算するのなら
m ** 3
と書けば済む話なだけ、なんでわざわざ関数なんかを作る必要はない。
ここではあくまでPascalでのコードを雛形とした話の展開になってるだけ、だ。
※4: こう聞いて、「出力はともかくとして入力って副作用なの?」って不思議に思う人もいるだろう。
Lispのread、Pythonのinput共に「入力を返り値として返す」からだ(前者はS式、後者は「文字列」だとしても、だ)。
ただ、LispのreadもPythonのinputも「そう設計されてる」だけで、本来、入力は「入力された値を何らかのカタチとして返す」わけじゃない。
事実、例えばC言語のscanfも入力関数だが、返り値は「入力された文字数」であって「入力された文字列」じゃない。エラーチェックの為に「数値を返す」なんだけど、入力されたブツに関してはバッファ代わりの「配列」から取ってこないとならないんだ。
言い換えるとC言語のscanfは「数値を返す」事が主作用であって、「入力を受け取って」「配列を書き換える」のは副作用だ、と言う事。しかもダブルで副作用してる。
こういうカンジで、実はハードウェアレベルでの「入出力」ってのはそもそもコンピュータ上では「計算」でも何でもなく、最終的にそれを「関数」にするかしないか、と言うのはプログラミング言語設計者次第で、しかも「何が主作用の関数になるか」も設計者次第だ、って事になるわけ。
なお、純粋関数型言語Haskellだとこの「副作用」さえ「ホンモノの」関数にしようとして四苦八苦してる(笑)。
※5: ここでアッサリと「関数」って書いたけど、往年ではサブルーチン、等と呼んだ。
※6: 合成データ。数値や文字等の単純な「一個」のデータを複数組み合わせたモノを指す。
一般に、リストやハッシュテーブル等はすべて「合成データ」と言って良い。
※7: 厳密に言うとやろうと思えばやれるけど、そのためには特殊な「動的配列」を用いないとならない。
いや、それは構文上「特殊」なだけで、結局C言語に於ける「配列」と言うのは高級言語での「配列」ではなく、単にコンピュータ内部に鎮座してるメモリーそのもの、なんだ。
そして、「動的配列」とは、そのメモリから使用域をぶんどってくるように指定する「行動」の事を事実上指す。つまり、C言語処理系が「自動でメモリ領域を確保してくれない」と言う、冷たい現実を指してるだけ、だ(笑)。
そしてそうしないと「配列を関数の返り値」に出来ない、んだ。
※8: 実際はこの例はちと恣意的で、RacketなんかのLispでは、「リストにして返す」より「多値として返す」方が自然だろう。
また、Pythonの場合は、複数の値を同時に return すれば自然とタプルとなってる。
※9: こういう事を鑑みると、ハードウェアに近い低レイヤーでは「スタックに関する操作」を関数、と呼び、「ヒープに関する操作」をプロシージャ、と呼ぶ、でエエんちゃうかな、とか思ってるが間違ってるかもしんない。
そしてプログラミング言語の抽象度が高くなれば高くなるほど、この「単純な操作」同士が入り組みすぎてて、どっちかに分類出来ない、ってカンジになってるんじゃなかろうか。
はてさて。
※10: プロシージャのもう一つの代表格が、ここで見せたアタマの悪いプログラム、つまり、中に出力関数(printf)を要したvoid型の関数だ。
しかし言っちゃえば、このテのプログラム自体が「書くのが無駄」だと思ってる(笑)。
※11: なお、Pythonではプロシージャは「Noneを返す関数」と表現される。
一方、Schemeの仕様上は、一般的な意味でのプロシージャの「返り値」は未規定となっていて、Racketでは#<void>が返る、って事になってるが、これは事実上、やっぱり「何も返さない」に等しい(と言うか、そういう風に「設計」されてる)。















