
本当はこの記事を書きたくない。
と言うのも、もう皆さんご存知だろうが、僕はC言語の専門でも何でも無い。
それどころか、むしろC言語を嫌ってる。
嫌ってる、って言って悪けりゃクソだと思ってる。
もっと酷いか(笑)。
とは言っても、「もっと楽してC言語のコードを書けりゃエエのに」と思ってGLibの使い方を検索してきた。
ところが、(英語文書を含めて)これのチュートリアルさえ見つからないんだ。
そこで、「分かってる範囲だけでもいいから使い方をメモしておけば誰かの役に立つかも」と思ったわけだ。もっとC言語「自体」に「僕より詳しい」人が(かつGLibを使った事がない人)、これをキッカケにしてGLibの「もっとマシな、詳しいチュートリアル」でも書いてくれればいいなぁ、と言う期待を込めてるわけだ。
言い換えれば他力本願なわけだが(笑)。
モダンなプログラミングだと外部ライブラリだろうが何だろうが「使った方が勝ち」と言う価値観がある。
ところが、C言語による「教育」だとこの「外部ライブラリ」の使い方を教えない。とにかく、何でもかんでも自作させようとする、「極端なDIY志向」が教育現場を支配してるようだ。
ところが、この方針はそもそも、UNIX系プログラミングの思想と実は相容れないんだ。「使えるモノは使ってしまえ」と言うUNIX系哲学と違って、どうやらCを使った教育現場はMS-DOS系の発想にいまだ支配されてるようだ。
そして「外部ライブラリ」使用は殆ど「奥義」とか「秘技」みたいになっている。本来の姿と逆なんだよ。
そもそも、Cを使った教育だと「ソフトウェアをマトモに書けるようになるまで」時間がかかりすぎるんだ。DIY前提の教育だと「データ構造とアルゴリズム」で自作ライブラリっぽいツールを作る「ような」事ばっか教わるが、それを学習しても思い通りにソフトウェアを作れるまでまだ超えなきゃならないハードルが「ありまくる」んだ。
果たして「データ構造とアルゴリズム」は先に学ぶべきモノなんだろうか?それより先にGLib辺りを使った「ソフトウェアの作り方」を学んだほうが応用が効いていいんじゃないだろうか。GLibが「どうやって動いてるのか」を後で「データ構造とアルゴリズム」で学べばいいんじゃないだろうか。その方が「深く」物事を学べるんじゃないだろうか。GLibはオープンソースなんで、ソースコードは閲覧可能だ。これほど「データ構造とアルゴリズム」に適した教材はないんじゃないだろうか。
とか色々考えるわけよ。
いずれにせよ、色々問題があると思うK&Rが何故「良書」と持ち上げられたのか。かの本は、曲がりなりにも「現実で使われてる」UNIXの代表的ユーティリティの簡易版を「書き方の例」として提示してたから、なんだ。
 | プログラミング言語C 第2版 ANSI規格準拠 B.W.カーニハン 共立出版 |
MS-DOSユーザーにはピンと来なかっただろうが、この本は「UNIXユーティリティのいくつかのソースコードを読むためのヒント」を例題として出している。結果、目の前で動いてる「UNIXユーティリティ」を教材として解読していこう、ってパースペクティヴがあったからこそ(UNIXユーザーに対しては)「名著」だったんだよな。
「実際に目の前で動いてる」モノを解読する為に勉強、ってのが一番具体性があるわけだ。先にGLibを使っていて、「その動きを知るために」後に「データ構造とアルゴリズム」と言うカリキュラムを組んだ方が、抽象的な「データ構造とアルゴリズム」論よりよっぽどマシな筈だ。何故ならソフトウェアを作った時はじめて「データ構造とアルゴリズムの重要性」を知るが、ソフトウェアを作る前に「データ構造とアルゴリズム」を学んでもそれは単なる無味乾燥な「机上の空論」に過ぎない。
また、一応建前としてはGLibはクロスプラットフォームなライブラリ、だと書かれている。要はLinuxやMac OS Xのような「UNIX系OS」だろうと、Windowsだろうと使える筈だ。
加えると、C言語の仕様、つまり国際標準のC17だろうとデファクトスタンダードやJISが採用しているC99だろうと、はたまた昔のANSI C/C90でも問題なく使える「らしい」。
と言う事は、煩わしい仕様に対しての差異を、GLibに従う限り隠蔽/吸収してくれる、と言う事だ。
このネタを暫く続けるかどうかは知らんが(笑)、取り敢えず今回はGLibが提供するデータオブジェクトの一つであるGStringを扱う。これにより「数値しか扱えない」ハズのC言語は「文字列オブジェクト」を入手する。
その話をする前に、GLibを使う為の下準備を始める。
Linuxディストロによっては、例えばFedoraなんかだと、特に設定をせずにGLibがそのまま使える模様だが、Debian系OSだとそうはいかないようだ。
また、GLibは「クロスプラットフォーム」だと宣伝してるんで、Windowsでも使える筈なんだけど、生憎、僕はWindowsを使ってないんで、その方法は知らない。
よって、ここではDebian系OSであるXubuntuでやった「設定」の話をする。
まず、.bashrcとか.bashprofile、あるいは(僕が使ってるzshの).zshrcと言う「シェル(端末)用設定ファイル」に次の一行を付け足す。
export PKG_CONFIG_PATH="/usr/lib/pkgconfig"
これはCコンパイラで外部ライブラリを採用する際に纏わる色々な面倒を緩和してくれる呪文だ。環境変数PKG_CONFIG_PATHは便利ツールpkg-configがどのディレクトリにあるファイル(pcファイルと言う)の設定に従ってライブラリを検索するのか指定する。ここでは/usr/lib/pkgconfigに設定ファイルであるpcファイルがある、と言う事にしている。
と言う事は、/usr/lib/pkgconfigにpcファイルが無いとならない。その中身はこんなんだ。
prefix=/usr
exec_prefix=${prefix}
libdir=${exec_prefix}/lib
includedir=${prefix}/include
glib_genmarshal=glib-genmarshal
gobject_query=gobject-query
glib_mkenums=glib-mkenums
Name: GLib
Description: C Utility Library
Version: 2.72.4
Libs: -L${libdir} -lglib-2.0
Cflags: -I${includedir}/glib-2.0 -I${libdir}/glib-2.0/include
これで「GLibがインストールされている場所」を確定させている。
sudoを使って/usr/lib/pkgconfigで適当なテキストエディタを開いて、上の内容をコピペしてglib-2.0.pcと名付けて保存しよう。
なお、Version:は貴方が使ってるGLibのヴァージョン番号を書いておけばいい。GLibの最新安定版は2.76だが、保守的なDebian系ディストロだと現時点では若干古い2.72.4を提供している模様だ。
さて、これで準備は整った。まず、GLibを使うと「世界で一番有名なプログラム」はこう書く(ファイル名をhello.cとする)。

あるいは次のように書いても良い。

まずヘッダだが、Ubuntu系ディストロだと基本的にはglib-2.0/glib.h「だけ」を#includeする。
入力はともかくとして、このヘッダを#includeするだけで、stdio.h、stdlib.h、string.h等の殆どのCの標準ライブラリ関係の#includeは済むようだ。
よって重複しそうな余計なヘッダは#includeしない。
次に、GLibの基本出力関数はg_printだ。
これは平たく言うとC標準関数のprintfをラッピングしている。そして、printfの返り値はintだったが、g_printはvoidだ。つまり、g_printはプロシージャだ、って事になる。
マニュアルによると、printfデバッグの変わりにg_printデバッグを行う、と言う事は推奨されていない。代わりにg_messageなぞを使え、と書いている。
しかし、いずれにせよ、GLibを使う際には出力にC言語標準関数のprintfやputsを使う代わりにg_printを使おう。
さて、上の1つ目のコードを見よう。まずはg_string_newだ。これはGLibが提供する文字列オブジェクト、GStringのコンストラクタだ。
「コンストラクタ」と言うのは難しく聞こえるかもしれないが、実はLispのconsも「コンストラクタ」の略称だ。日本語では「構築子」と訳されたりする。コンストラクタは特定のデータオブジェクトを「生成」する。
何度も書いてるが、C言語には「文字列」がない。言い換えると「文字列オブジェクト」がない。
C言語には「数値」と「メモリ」しかない。一定条件で「連続する数値」は「文字列」と「解釈」される。その「条件」とは、単純に言うと、メモリを適当な場所からサーチしていった時、どっかがゼロだった場合、そこまでを「文字列」と解釈する。
しかし上の「仕組み」では「文字列オブジェクト」だと主張はできない。所詮「解釈」でしかないから、だ。よって気の利いた教科書では「文字列」とは呼ばずに代わりに「文字配列」と呼んだりするわけだ。
一方、GLibが提供するGStringは「文字列オブジェクト」だ。少なくともそれを意図してる。
単純に言うと、C言語には数値しかない。よってもっとマシな高級言語に於ける「データ型」が存在しない。しかし、データ型、つまり「オブジェクト」を辛うじて作り出せる機能はある。それが型を生成するtypedefと構造体structのコンビネーションだ。
そう、GStringはtypedefとstructのコンビネーションで作られたオブジェクトだ。ここで初めて(外部ライブラリの力を借りてやっと)C言語で「文字列オブジェクト」を入手する。そして、g_string_newと言う「構築子(実態は関数だが)」はC言語の「文字配列」をGStringと言う「文字列オブジェクト」に変換しつつ生成する。
GLibを使う際には、素のC言語で言う「文字配列」やchar*をそのまま使わないようにしよう。と言うより、まずは「C言語に文字列オブジェクトを導入する」為だけ、にGLibを使う価値が生じる、とでも言おうか。
どっちにしても、「文字列がない」C言語に「文字列」を導入出来るのがGLibの旨味だ。
よってこれにまずは慣れよう。GStringには素のC言語のstring.hでは得られないメリットがたくさんある。それは後述しよう。
一方、デメリットもないわけではない。単純に出力関数g_printにそのままGStringを渡しても印字してくれない。本当ならg_print側に解決策を持ってて欲しいトコなんだけど、GLibはそこまで親切じゃないんだ。
GStringは先にも書いた通り、構造体で定義されたデータにtypedefでGStringと言う「型」を与えて文字列オブジェクトにしている。定義は以下のようなモノだ。
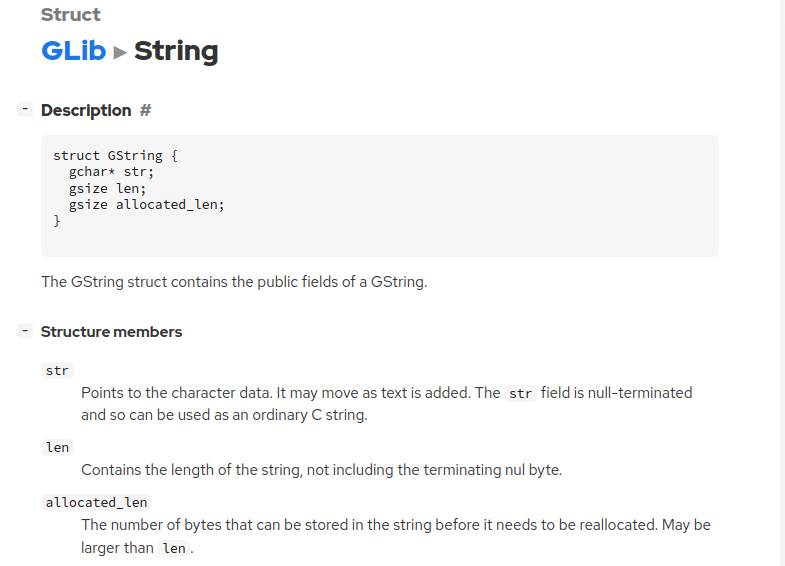
構造体はいくつかの基礎データの合成データ(Compound Data)だ。そしてGStringは含んでるデータ(メンバーとかフィールドとかスロット等と呼ぶ)が3つある。重要なのはそのうち2つで、1つ目はgchar*と言う「動的文字配列」情報str、2つ目はstrの長さであるlen、だ。C言語での文字配列はstrにあたる。
構造体から特定のメンバーあるいはフィールド値またはスロット値を取り出すにはアロー演算子(->)を使う。g_printへ渡すのはgchar*であるstrなので、
g_print("%s", g_string_new("hello, world\n")->str);
で出力可、となる。
上の2つ目のコードではGString型、と言う文字列オブジェクトの変数を宣言して、そこにg_string_newで文字配列を変換した結果を代入する方式で書いている。
GString* hello = g_string_new("hello, world\n")
ここでは、宣言がGString型へのポインタ変数hello、となっている。
で、C言語にあまり明るくない人は、
「何故にGString*なの?単純にGStringだけだとダメなの?」
と不思議がるだろう。
ここでも、C言語はメモリをまとめて扱えないと言う話を思い出そう。
構造体もメモリのとある領域を使って定義される。基本的にはインデックス(添字)代わりにメンバー/フィールド/スロット名でアクセス出来る「特殊な配列」ってのが構造体の正体だ。
ある領域、って事は塊なんだけど、C言語はその塊のまま変数に受け渡しは出来ない。代わりに例によってその領域の先頭アドレスしか取ってこれないわけだ。
となると、受け取る変数側にはその先頭アドレスが受け渡される事になり、結果、その変数はポインタ変数じゃないと役に立たないわけだ。それがGString*として宣言する理由だ。
この理由を考えたくない人は、C言語で合成データ(Compound Data)を変数に代入したい場合、変数側は「必ず」ポインタ変数になる、って覚えておいてもいいだろう。と言うのも上に書いた通り、合成データはどっちにせよ、ある大きさのメモリ領域を使って定義されるんで、メモリをまとめて扱えないC言語だと、その領域の先頭アドレスを使って指定するしかねぇからだ。
従って機械的に、代入対象の変数はポインタ変数にならざるを得ない。
変数helloをこうやって定義しておくと、g_printで出力するにはhello->strとすれば1番目の出力コードと同じ効果となる。
また、C言語の場合、合成データを扱う変数を作成すると、必ず使った後にその領域を解放しないといけない。Lispに始まって、Python、Ruby、Javaはガベージコレクタによりメモリを自動解放してくれるが、生憎C言語はそこでも親切な言語じゃない。よって手作業で解放しないといけない。
GStringとして使われた領域を解放するにはg_string_freeを使う。g_string_freeは二引数関数で、第一引数には解放したいGString*型の変数名、そして第二引数にはTRUEを与える。
第二引数にFALSEを与えるのは推奨されてないようなんで、取り敢えずTRUEを与えておけば良い。なお、GLibでの真偽値はgbooleanとして定義されている。
取り敢えずhello.cをコンパイルしてみよう。Debian系Ubuntuなんかではgccを使えば次のようなコマンドラインでコンパイル出来る。
gcc -o hello hello.c $(pkg-config --cflags --libs glib-2.0)
最初に設定したpkg-configでライブラリとしてglib-2.0を指定してコンパイルする。なお、pkg-configに関する部分はコマンドの最期に置いた方が良いようだ。
このコマンドラインによって、実行形式helloが生成される。
helloを実行したらhello, world!と端末に表示される筈だ。
さて、GStringはg_printにそのまま渡せない、と書いた。このままだと、コーディングが面倒くさいだけでGStringの旨味は分からない。
よってここからはメリットの話を書いていく。特に大きいのが「文字列の連結」だ。
その話を読む前に、取り敢えずこのページをザーッと覗いてきて欲しい。
覗いてきた?
なんか文字列をコピーしたり、あるいは連結するのが至極メンド臭い、って感じるんじゃなかろうか。
いや、面倒くさいってのは分かったけど、ピンと来ない人に説明しよう。
C言語では単純に次のような事が出来ないんだ。
;;; Racket> (define str1 "DRAGON")
> (define str2 "QUEST")
> (string-append str1 str2)
"DRAGONQUEST"
># Python>>> str1 = 'DRAGON'
>>> str2 = 'QUEST'
>>> str1 + str2
'DRAGONQUEST'# Rubyirb(main):001:0> str1 = "DRAGON"
=> "DRAGON"
irb(main):002:0> str2 = "QUEST"
=> "QUEST"
irb(main):003:0> str1 + str2
=> "DRAGONQUEST"
// JavaScriptjs> str1 = "DRAGON";
"DRAGON"
js> str2 = "QUEST";
"QUEST"
js> str1 + str2;
"DRAGONQUEST"
モダンなプログラミング言語だとどれもハナクソで「文字列の連結」が出来る。
一方、件のサイトのコードを良く見てみよう。

DRAGONは6文字だ。ヌル文字を含めても7文字の「文字配列」だ。
しかし、str1と言う文字配列の変数は12文字分だ。DRAGONより遥かに多い「文字数の想定」になってる。
単純にこれはDRAGON以降にstr2をはめ込む為だ。そのため「だけ」に余分な領域を確保してる・・・いや、これって"DRAGON"って文字列と"QUEST"って文字列を「結合した」って言えるんだろうか?
しかもこのプログラムを成立させる為には、貴方が結合後の文字数を前もって数えてないとならない。C言語は文字数を数えることさえ、しねぇんだ(苦笑)。
だから言ったろ、C言語は「メモリの使い方を覚えられる素晴らしい言語」じゃなくって、一々プログラムする側がメモリの面倒を全部見なアカン言語だ、って事だ。殆ど老人介護のノリなんだよ(苦笑)。
一方、GLibを使えばこのようにプログラムする事が可能だ。

GStringの場合は、「長さ」データを持ってるんで、何もコッチ側が「長さ」を気にせんで良い(メモリを解放する手間はかかるが・・・苦笑)。コッチのプログラムは結果、LispやPython等の動作に近い。
関数g_string_appendは次のように定義されている。

関数g_string_appendは二引数関数で第一引数はGString*型のデータ、第二引数はgchar*型の動的文字配列だ。直接GString*型同士を結合は出来ないが(残念!)第二引数ではGString*型のデータオブジェクトからstrを引っこ抜いて来れば良い。
結果書式はこうなるわけだ。
g_string_append(str1, str2->str)
これにより、str1は破壊的変更され、2つの文字列が結合するモノ、となる。
元になる文字列データを破壊的変更したくない場合は、別に破壊的変更用のGStringを用意しておけばいい。

あるいは、件のページの次の例に倣ってもいいだろう。

C言語標準関数のsprintfにあたるGLibの関数がg_string_printfだ。

g_string_printfは可変長引数を取る関数だ。第一引数は結合先の文字列、第二引数は「どういう書式か」を指定するフォーマット文字列になる。第三引数以降は結合文字列の材料となる文字配列を指定していく。
結果、次のようになる。
g_string_printf(str0, "%s%s%d\n", str1->str, str2->str, i)
実行結果は次のようになる。

このように、GLibのGStringは「文字配列同士の結合後の長さ」を全く気にせず、比較的、モダンなプログラミング言語の文字列のように扱える。それにより、string.hで用意された貧弱な関数を粛々と置き換えて使う事が可能だ。
取り敢えず、GLibに慣れるにはまずはGStringから始めよう。とにかく文字列リテラルをg_string_newで包もう。そして文字配列の情報を取り出したい時はアロー演算子を使ってstrを取り出す。変数にGStringのデータを代入したい時には、変数をGString*とポインタ変数として宣言する。変数を使い終わったあとはg_string_freeでその変数を解放する。
そのプロセスさえ覚えておけばGLibの最初の使い方としてはO.K.で、使ってるうちに構造体使用の「様式」やポインタ使用の「様式」に慣れていく筈だ。
この記事の最期に、GString同士の「同値」の問題にちょっとだけ触れる。
次のようなコードを考えてみよう。

文字列リテラル"DRAGONQUEST"を利用して文字配列dqを定義する。
変数dqを使ってGString*型のデータ、str1、str2の2つを作る。
さて、この2つのデータが等価かどうかを==で調べる。果たしてTRUEが表示されるかFALSEが表示されるか?
答えはFALSEなんだ。

同じ文字列じゃない?って思うだろうけど、実は「文字列の中身が等価かどうか」は==では調べられない。
確かにstr1もstr2も全く同じ文字列リテラル"DRAGONQUEST"から生成されたGStringだ。だからこの2つは等価だ、って思うかもしんない。
しかし、g_string_newは「新しくGStringオブジェクトを生成する」。と言う事はstr1もstr2も「違うメモリ領域」が使われている。
そして==は原則数値比較用の演算子で、そしてstr1とstr2には「本当は何が代入されてるか」考えてみよう。str1もstr2も「GString型」へのポインタだ。つまり、実質的には「アドレス番号」が入ってるんだ。
何故上のコードがFALSEを返すのか、と言うと、str1とstr2が保有してる「アドレス」が違うからなんだ。
事実、次のようなコードを書くとハッキリと分かると思う。

g_printは日本語のようなUTF-8文字には対応してないが、glib-2.0/glib/gprintf.hに含まれるg_printfは文字化けせずに日本語を出力してくれる。
さて、g_printf + 書式指定子%pでアドレスを見る事が出来るんだが・・・。

紛らわしいが、「近い場所にはいる」がstr1とstr2は「同じ場所にはない」。言い換えると「同じオブジェクトではない」んだ。明らかにg_string_newは新しいオブジェクトを生成してる。
アドレスをコピーしたい場合は次のようにすれば良い。

str2にstr1を代入すれば、str1が持ってたアドレスはstr2にコピーされる。

一見2つのオブジェクトに見えても、それらオブジェクト自体が「同値」(つまり「同じアドレスに存在する同じ物体」)なのか、はたまた、「オブジェクトの中身」が同じなのか、は意味が違う。
オブジェクト同士が「同値」かどうかを調べるには単にアドレスを比較すればいい。これが、LispのeqやSchemeのeq?がやってる事で、これをポインタ比較と呼ぶ。ポインタ変数が指してるアドレス「だけ」を比較してるだけだ。中身までは見ない。
しかし、当面関心があるのは「違うオブジェクトでも中身が同じかどうか」だ。文字列の比較とは「中身の比較」であって、オブジェクトがメモリのどこに置かれてるのか、には差し当たって興味はないわけだ。ポインタ比較ではないので、結果==は使えない。
結論から言うと、「同じ文字列を表してるか否か」はg_string_equalを用いて比較する。

これならGString*型であるデータ、str1とstr2が「メモリのどこに置かれてようと」印字するブツが「同じ」ならTRUE、「違う」ならFALSEを返す。

オブジェクトが違う場所にある(つまり同一じゃない)場合でも、「文字列」として中身が同じなら、TRUEを返してくれるのがg_string_equalだ。
とまぁ、繰り返すが、GLibに慣れるのなら、まずはGStringから始めるのがいいと思う。














