
いやぁ、星田さんが楽しそうだ(笑)。
一つ一つ問題解決していくのは面白いよね。
その辺がプログラミングを学ぶ楽しさです。
さて、星田さんは有料の英辞郎って英和辞書を使ってるようなんだけど。
生憎僕は持ってないんで、今回はフリーの英和辞書を使ってみます。
残念ながら発音記号は含んでないんですが、星田さんの示してる仕様を見る限り、今回は単語が重要で、僕のダウンロードした辞書も単語と意味の二つしか含んでないんで、一応形式的には対応出来るでしょう。
import csv
with open("hatuon.csv", "r") as f:[print(line) for line in csv.reader(f)]
上記のコードを実行すると次のようになります。

「発音記号」と「意味」の差はあるにせよ、取り敢えず同形式のデータは得られたと思う。
ちなみに、星田さんの環境でencoding="utf-8"が必要でこっちじゃそうじゃない理由ってのは星田さんは恐らくWindowsを使ってて、僕の方の環境はLinuxだから、ですね・・・昔は違ったんだけど、今どきのLinuxは基本、全部UTF-8で統一してるんで、あまり文字コード変換の煩わしさが生じない。
反面、Windowsは、内部的にはUTF-8で処理してんだけど、表面的にはSHIFT-JISが用いられていて、変換の煩雑さがあるんですよね。それで文字コード関係だと割に意図しないトラブルに遭遇する。
CSVだと基本テキストファイルと同じなんで、メモ帳ででも開いてセーブしなおせば良いかもしれません。今のWindowsのメモ帳はUTF-8基準なんで、テキストファイルをUTF-8で開いたり保存したりする場合、結構頼れます。
一方、同じWindowsデフォルト搭載のWordpadだと、相変わらずSHIFT-JISで日本語の環境だと何でも保存してたんじゃないかなぁ・・・うろ覚えだけど。
さて、星田さんが次のようなコードを書いている。
import csv
with open("hatuon.csv", "r") as f:
reader = csv.reader(f)
for boinline in reader:
boinword = boinline[0]
boinboin = []
boinboin = "".join(["a" if i == "a" else
"e" if i == "e" else
"o" if i == "o" else
"u" if i == "u" else
""
for i in boinword])
print(boinboin)
出力はこうなる。

おお、上手く行ってますね。
リスト内包表記の試用も上手く行ってます。
いよいよ星田さんも関数型プログラミングの世界に入ってきた。
Welcome to the World of Functional Programming!
ただ、ちょっと手続き型が混ざってるんですよね(笑)。
実はここが要らない。
boinboin = []
これ、実は全く使われてないんです。っつーかその次のリスト内包表記で書き換えられる為だけに存在してる。実質何もしてない。
いずれにせよ、ついついポカでこれを書いちゃう、ってのは、星田さんは関数型プログラミングの入り口に立ってるんだけど、今は関数型プログラミングと手続き型/オブジェクト指向プログラミングの境界線の上にいる、って事を意味してる。
さて、ここでも「僕だったらこう書く」ってのをちょっと解説していきます。
まず、星田さんは
with open("hatuon.csv", "r") as f:
reader = csv.reader(f)
for boinline in reader:
こう書いてますよね。
ここで、readerと言う変数を用いてcsv.reader(f)を「代入」するのはどうなのか、って考えてみます。何故ならすぐ下にfor文があるから。
この時点で「あ、リスト内包表記が使えそうだ」って思う。
そうするとこの時点で既に次のように書ける筈。
with open("hatuon.csv", "r") as f:
[ for boinline in csv.reader(f)]
まず変数readerを消しちゃって直接csv.reader(f)を使っちゃう。
このままでは不完全なんですが、取り敢えずここまで書いちゃいます。
んで原版の次の行はこうなってる。
boinword = boinline[0]
そうね、実はここでもboinlineのアタマを取ってくるだけ、なんで代入は必要ない。
従って、ここまでの部分は
with open("hatuon.csv", "r") as f:
[boinline[0] for boinline in csv.reader(f)]
と一行で書けちゃう。
マジで?って疑うのなら、一旦printを組み込んで動作を見てみれば良いです。
with open("hatuon.csv", "r") as f:
[print(boinline[0]) for boinline in csv.reader(f)]

と、確かに単語の部分だけ抽出出来ます。
ということはまずは押さえるべきは加工対象のデータはboinline[0]である、と言う事。
さて、あとはここのprintを外して、星田さんが考えたようなリスト内包表記の適用を考えるだけ、なんだけど。
これはこのブログで既にお馴染みになった「フィルタリング」の問題です。
フィルタリングの基本的な書き方は
[i for i in データ if 条件式]
となってる。
んで、そこには条件式の設定をどうすれば良いのか、って問題がありますね。
まず、ちょっと基本的なトコを確認しますが。
星田さんが以前こういう事をブログで書いてたんですよね。
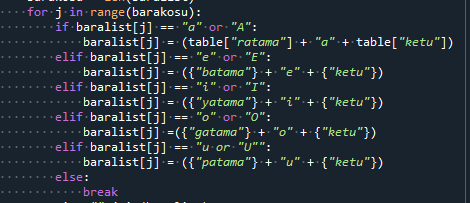
なんか条件分岐がうまく働かない。色々とやってみて == "a" or "A" の書き方が問題だった模様。そりゃそうだw もう面倒なので小文字だけにする
まぁ、僕が「辞書型使えばエエんじゃね?」とか言って軽くスルーしましたが(笑)。
ええとね、実の事言うと「こう書きたい」って気持ちは良く分かる。
if baralist[j] == 'a' or 'A':
ところが通常、プログラミング言語だとこう書かないとならないのね。
if baralist[j] == 'a' or baralist[j] == 'A':
そう、orが結ぶのは式同士、なんです。
これちょっと説明が厄介なんだけど、最初の書き方だと
「baralist[j]が'a'である」か(baralist[j]に関係なく)'A'の場合」
って意味になっちゃうのです。
で、通常、データ型がヒエラルキーを形成してる言語だと、FalseとかNoneは単一な存在なんだけど、その他のオブジェクトは全部真になっちゃうんですよ。
>>> not "A"
False
>>>
"A"にnotを適用するとFalseが返ってくる。って事は"A"は問答無用でTrueなんです。
実際次のようなコードを書いてみる。
if "A":
print("hoge")
else:
print("fuga")
このコードだと永久にelse:以降は実行されません。何故なら"A"は常にTrueだから。
従って、
if baralist[j] == 'a' or 'A':
と書いちゃうと、baralist[j] == 'a' がいくらFalseを返しても"A"がTrueなんで、そっちが働いちゃって条件節は全体としてはTrueを返しちゃうんです。
それが「条件分岐がうまく働かない」理由です。決してFalseにならないから。
そうすると、フィルタリングを行う一つ目の方法は、boinline[0]から取り出した文字boinwordに対して(lower()で小文字化前提で)
[boinword for boinword in boinline[0]if boinword.lower() == "a"
or boinword.lower() == "e"
or boinword.lower() == "i"
or boinword.lower() == "o"
or boinword.lower() == "u"]
とする事。
全体的には
with open("hatuon.csv", "r") as f:
[[boinword for boinword in boinline[0]
if boinword.lower() == "a"
or boinword.lower() == "e"
or boinword.lower() == "i"
or boinword.lower() == "o"
or boinword.lower() == "u"]
for boinline in csv.reader(f)]
となる。リスト内包表記のリスト内包表記だ(笑)。
まあ、こりゃやり過ぎだろ、ってのもあると思うんだけど、取り敢えずはこれで動く。
例によってprintを入れてテストしてみる。
with open("hatuon.csv", "r") as f:
print([[boinword for boinword in boinline[0]
if boinword.lower() == "a"
or boinword.lower() == "e"
or boinword.lower() == "i"
or boinword.lower() == "o"
or boinword.lower() == "u"]for boinline in csv.reader(f)])
そうすると、

なんかすげぇ状況になってるけど(笑)、基本的に要求仕様を満たしてます。
取り敢えず、基本的なフィルタリング構文を適用すれば
条件式で「何もしない」って書き方を知らない
と言う事も問題じゃなくなる。
でも「リスト内包表記のリスト内包表記」になってるとこは、取り敢えずは後回しにしといて。
さすがにこの部分、
if boinboin.lower() == "a"
or boinboin.lower() == "e"
or boinboin.lower() == "i"
or boinboin.lower() == "o"
or boinboin.lower() == "u"
っつーのはみっともなくねぇか?って話がある。理屈はともかく冗長だよな、と。
ここで星田さんが良い事言ってる。
さっきの内包表記、「aeiou」のリストを予め作っておいて、それを入れ子のForで回すってのが出来るのでは!?
BINGO!
ただし、「Forで回す」必要はないのだ。単純に条件式の問題だ。
実はPythonでは次のように書けます。
with open("hatuon.csv", "r") as f:
[[boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]]for boinline in csv.reader(f)]
そう、
if boinword.lower() in ["a", "e", "i", "o", "u"]]
と、inとリストを組み合わせて条件判定に持ち込めば、難なくフィルタリングの条件設定が可能。
またprintと組み合わせて実行結果を見てみます。
with open("hatuon.csv", "r") as f:
print([[boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]]for boinline in csv.reader(f)])

とまぁ、全く同じ結果が返ってきます。当たり前だけど。
ただまぁ、関数型言語流儀だとこうなる、っつーわけだけど、さすがにワンライナーつってもこりゃやりすぎだろ、ってのはやっぱあるんですよね。
大体、縦に長くならんでも横に長くなればしゃーねぇやろ、とか。
だからこの辺は好みなんで、やっぱ「見づらい」となれば変数に束縛しなおすのも吉、だとは思います。
例えばこう書いたり、とかね。
with open("hatuon.csv", "r") as f:
boinboin = []
for boinline in csv.reader(f):
boinboin += [[boinword for boinword in boinline[0]if boinword.lower() in ["a", "e", "i", "o", "u"]]]
あるいはこう書く、とか。
with open("hatuon.csv", "r") as f:
boinboin = []
for boinline in csv.reader(f):
boinboin.append([boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]])
余談だけど、append等のメソッドはなるたけ使わない方が良い。
と言うのもPythonの組み込みデータ型に入ってるメソッドは結構な確率で破壊的変更目当てです。だからまずはメソッドを使わない操作方法を学ぶべき(と言う事さえもC言語経験者は教えてくれない)。
「使わないべき」なら何でそんな破壊的変更目当てのメソッドなんて用意してるんだろ、と不思議に思うでしょ?それはプログラムが完成してプロファイラでボトルネック(プログラムの全体のパフォーマンスを下げてる箇所)が見つかった時、非破壊的方法論が原因だった場合に置き換える為にあるんです。そう、後々の効率化/最適化用にある。
前提としては、関数型言語の考え方はデータを無闇に変更しない、です。
>>> lst = [1, 2, 3]
>>> lst + [4]
[1, 2, 3, 4]
>>> lst
[1, 2, 3]
>>>
変数lstのケツに[4]を足してもlstそのものは[1, 2, 3, 4]にはならない。だからこれが関数型プログラミング言語では望ましいスタイルです。
ただし、これを実現するためには lst + [4]と言うlstとは全く別のリストを保持する為の「メモリ上の場所」が必要だと言う事。つまり、暗黙に「リストをコピー」する為のメモリを消費してしまうんです。
一方、例えばappendと言うメソッドは「元データに直接」何かを付け足します。つまりメモリ上の別領域を使う必要がない。従って、メモリ効率はこっちの方が良いわけです。
ただし、メモリ領域を使ってたからと言ってそこが「プログラム全体に対して非効率性を生んでる」かどうかは分からない。結果、プログラムを書き上げてからプロファイラで問題箇所を探さないと何とも言いようがないのです。
計算機科学者のドナルド・クヌースは次のように言ってます。
- 早すぎる最適化は諸悪の根源
言い換えると
- 最初は遅くても良いからコードの綺麗さを重視しろ
そして、上の「変数の書き換え」はとにかくバグの元になりやすい。
つまり、プログラムを書いててアッチコッチの関数からそのデータにアクセスするような状態になって、いつの間にかどっかの関数が元データを勝手に書き換えやがって(しかも貴方がそう書いたのに全く覚えてない、なんつー事は良くあります)、それが原因で思わぬバグを引き起こす。
「あれ?何が原因でデータが変わってるんだ?」
と貴方は悩むんだけど、そもそもそんな「破壊的変更を伴う関数を書いた事すら忘れている」んで、当然バグの原因がどこなのかサッパリ分からん、思い出せんと。
そういう事が良くあるんで
- 最初は遅くても良いからコードの安全性を重視しろ
と言うのも含んでるんですね。
そして安全性を重視してデータの破壊的変更を避けたとしても、そこが本当にボトルネックになってるかどうか、ってのは神のみぞ知る、です。
要するに、同じくクヌースは次のように言っている。
「ほんとうの問題点は、プログラマたちが誤った場所と誤った時点での効率について苦労して、多くの時間を浪費してしまったということにあります。」
これは言い換えると、最初っから最適化されたようなコードを書こう、なんつーのはどのみち見当はずれの最適化を施してるに過ぎない、って事なの。まずそーゆーやり方だと殆どのケースで
「書いたプログラムの全体の効率化にはクソの役にも立たない」
って事を言ってんのね。
だから
- 最初から効率化しよう、なんつー事は考えんな。
- 従って、appendを含むPythonのデータ型の操作メソッドは使うな(破壊的動作じゃなければこの限りじゃない)。
- プログラムを書き終わったらプロファイラを走らせてボトルネックを探せ。
- あとはボトルネックとなってる部分を最適化するだけ、なんだけど、それは関数型プログラミング的に書いたからかどうか、ってのはどの道プログラムを書き始めた時点では分からん。
と言う事です。
だから、長い余談になったけど、C言語経験者が初心者向けにPython入門書を書く時、彼らはどうして非破壊的手段と破壊的手段が二つ用意されてるのか全く分かってないと思うの。そしてやっぱりC言語がそうだったからって理由だけでやたらappendとかextendとかinsertって言う破壊的メソッドを使って初心者に教えたがるわけ(何故ならC言語は破壊的手段を多用せざるを得ないプログラミング言語だから)。
でもそれって間違ってんだっての。もうこうなると、ホントC言語脳って公害としか思えないんだよ。ホンマ、彼らの言う事を聞くな、としか言えない。
んで元の話に戻る、っつーかプロファイラの話が出たついでに見てみようか。
Pythonのプロファイラの簡単な使い方はここに書かれてるんですが。
例えば先に書いた3つのプログラムをfooとbarとbazと言う3つの関数としてラッピングして、それぞれに次のようにcProfileを適用して比較してみる。
import cProfile
import csv
def foo():
with open("hatuon.csv", "r") as f:
[[boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]]
for boinline in csv.reader(f)]
def bar():
with open("hatuon.csv", "r") as f:
boinboin = []
for boinline in csv.reader(f):
boinboin += [[boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]]]
def baz():
with open("hatuon.csv", "r") as f:
boinboin = []
for boinline in csv.reader(f):
boinboin.append([boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]])
[cProfile.run(i) for i in ['foo()', 'bar()', 'baz()']]
んでこれで計測してみると例えば次のようになるのね。
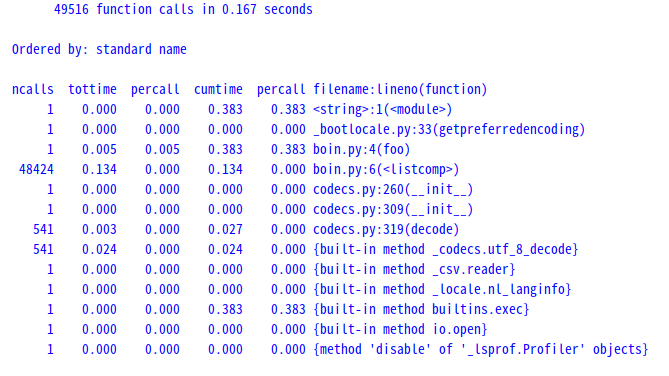

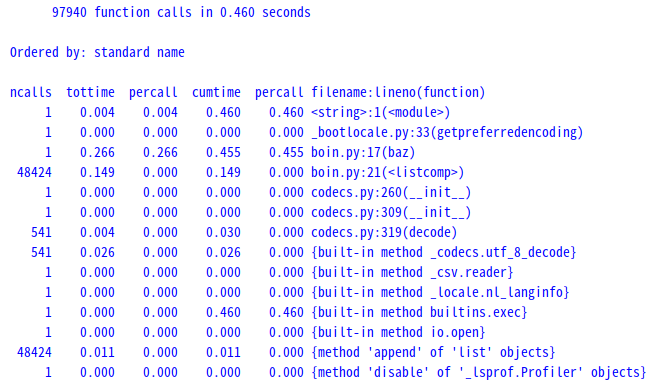
取り敢えず細かい自作関数はねぇんだけど、結果は上の通り。
リスト内包表記だけでネスト(入れ子、とも言う)してる関数fooは内部的な関数呼び出しは49516回でこちらの環境では0.167秒。やっぱ最適化されてるだけあって最高演算速度。
二番手は完全なリスト内包表記ではない、for絡みでappendを使った関数baz。内部的な関数の呼び出し回数は97940回でその数、fooの二倍程で、実行時間はこちらの環境では0.460秒。リスト内包表記「だけ」の関数fooより2.5倍〜3.0倍程度遅いのだ。
三番手はappendを使わずリストの加算を使った方法論の関数bar。fooと同様、関数呼び出しは49516回で実行時間はこちらの環境では0.481秒。実は二番手とその差は大した事がない。状況によっては二番手と三番手は入れ替わる事もあるだろう。結局、やっぱり「破壊的変更をしたからと言って劇的に速くなるわけではない」と言う事なんだ。
いずれにせよ、「Pythonでリスト内包表記は最適化されている」と言う意味が分かるでしょう。リスト内包表記はforやwhileより速い。
だからクヌースの言葉に(逆な意味で)従って、
「リスト内包表記はPythonに於いては一種最適化技法なんで、これを使うよりは読みやすさ優先で最初にforやwhileを使う」
ってのは全然アリだとは思う。
当然「関数型プログラミング」にこだわって初期状態からリスト内包表記を取り入れてもいいだろうし(なんせPythonの設計者は「短く記述可能な」リスト内包表記を使ってもらいたくって最適化してんだから)。
その辺は結局個人の好みになるかな。
ここでは一応関数型プログラミングにこだわっていく趣旨なんで、完全な、ネストしたリスト内包表記を肯定して話を進めていきます。
まず内側のリストを文字列に直さないといけない、って前提があるんで、星田さんが書いてる通りjoinを使って起こりうる母音列を生成する。
with open("hatuon.csv", "r") as f:
["".join([boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]])for boinline in csv.reader(f)]
そう、joinする対象はネストしたリスト内包表記の内側の方だ。
まとめてprintしてみたら状況が確認出来ます。

うん、母音だけ抽出した文字列のリストになってるわな。
さて、ちと整理してみよう。
リスト内包表記内の変数boinlineの要素は[単語、意味]と言う2要素のリストになっている。例えば["boin", "1. aeiouの事。2. おっぱい"]とかな。
今得た変数boinwordを連結した文字列はboinlineの単語から母音を抜き出したモノだ。例えば"oi"とかな。
つまり、今は["boin", "1. aeiouの事。2. おっぱい"]と"oi"と言う材料を使って["boin", "1. aeiouの事。2. おっぱい","oi" ]と言う3要素のリストを作りたい。
従って、その方法論は
["boin", "1. aeiouの事。2. おっぱい"] + ["oi"]
となる。
と言うことは、だ。
次のように書けば各要素に対して同様の効果が得られる事となる。
with open("hatuon.csv", "r") as f:
[boinline + ["".join([boinword for boinword.lower() in boinline[0]
if boinword in ["a", "e", "i", "o", "u"]])]for boinline in csv.reader(f)]
またprintを噛まして出力を確かめてみよう。
with open("hatuon.csv", "r") as f:
print([boinline + ["".join([boinword for boinword in boinline[0]
if boinword.lower() in ["a", "e", "i", "o", "u"]])]
for boinline in csv.reader(f)])

オッケーオッケー、上手く行ってる。
あとはファイルに書き出せば良いだけです。
openで書き込み用ファイルを開いてcsv.writerでwriterオブジェクトを作成する。
ここまでを読み込みと組み合わせると、
with open("hatuon.csv", "r") as f:
with open("newdic.csv", "w", newline="") as g:writer = csv.writer(g)
となります。
んで、先程まで作ってた部分は結局「文字列のリストのリスト」を返してるんで、一行は「文字列のリスト」が担う。
これをcsvファイルとして出力するにはwriterowsじゃなくってwriterowを使わないとならない。あ〜〜紛らわしい(笑)。
まぁ、いずれにせよ、今までの設計を活かすと、writerowを組み合わせて
with open("hatuon.csv", "r") as f:
with open("newdic.csv", "w", newline="") as g:
writer = csv.writer(g)
[writer.writerow(boinline +
["".join([boinword for boinword in boinline[0]
if boinword.lower()
in ["a", "e", "i", "o", "u"]])]) for boinline in csv.reader(f)]
で完成。
テストしてみるとnewdic.csvと言うCSVファイルが生成される。

はい、上手く行ってますね。
ここまでで分かる事。
それは、「ネストしたリスト内包表記」が許容出来るか否か、ってのは人によって随分と違う、と言う事。
ただし、プロファイラで見た通り、Pythonでダントツのパフォーマンスを示すのが圧倒的にリスト内包表記だ、ってのは事実なのよね。
でも「ネストしたリスト内包表記」とか、カッコが多すぎて見づらい、とかフツーの人はそう思うかも。多分。
Lispやってた人だとそういうのはヘーキなんですが(笑)。
まぁ、コーディング上、どっちを選んでも痛し痒し、ってのはやっぱあるんで、色々試しながらリスト内包表記と付き合っていってくれればいいな、とか思っています。
最後に全コードの最終型を載せておきます。
Pythonだと「異形のコード」に見えるけど、関数型プログラミングとしては「正しい」ので楽しんでください。
#!/usr/bin/env python3
import csv
import sys
if __name__ == '__main__':
fname, gname = sys.argv[1], sys.argv[2]
with open(fname, "r") as f:
with open(gname, "w", newline="") as g:
writer = csv.writer(g)
[writer.writerow(boinline +
["".join([boinword for boinword in boinline[0]
if boinword.lower()
in ["a", "e", "i", "o", "u"]])])for boinline in csv.reader(f)]









