
Pythonにはデコレータと言うモノがある。
知ってる人は知ってるだろう。例えばPythonでのオブジェクト指向プログラミングでクラスメソッドを定義する@classmethodなんつーのがそれ、だ。冒頭に@を置いて書く記述が特徴的、と言えば特徴的だ。
そしてこの@を含んだ関数はユーザーが定義した関数をラップする。
Pythonではこの@を含んだ関数をライブラリとしていくつも提供している。ユーザーの方々はこういう@を含んだ関数を利用して下さい、と。
一方、Pythonは基本的に、ユーザーが「ラップされる側の」関数、あるいはメソッドを定義する事を許すが、「ラップする側の」関数を定義する、と言う事を許容してはいない。公式には、あくまで、デコレータとは「Pythonが提供するライブラリ」であって、ユーザーが定義するモノじゃないんだ。
なんでそんな事が分かるか、って?
簡単だ。実の事を言うと、Python公式ドキュメントを検索してもデコレータの存在を匂わせ、いくつものPython公式デコレータの「使い方」に対しての記述は見つかるが、デコレータの「作り方」に関して一切触れてない、からだ。特にPythonチュートリアルに何も書かれてない、ってのは致命的だろう。
つまり、Pythonは公式には、デコレータはあくまで「Pythonが提供するモノ」をユーザーが使うだけ、であって、「作るものではない」と考えてる、って事だ。「作ってくれ」と思ってるなら「作り方」を書く筈だが、それが成されてない、って事は「ユーザーがデコレータを作る」と言うのは「想定外だ」って事なんだ。
当たり前だろ?
しかし、ネット上では「Pythonのデコレータって何?」ってぇんで作り方を紹介してるサイトやブログが多くある、ってのも事実だ。ある意味「裏技」的にそれが広まってる。
ただし、個人的には、それらをいくつか見てみたが非常に分かりづらい解説だと思ってる。と言うか「関数がファーストクラスオブジェクト」「高階関数」が分かってない人が解説/あるいは理解する、ってのは難しい題材なんじゃないか。少なくとも「Pythonic」とか言ってる奴ら、つまり「PythonのLisp及び関数型言語機能」を疎んじてたり理解してない奴らが愛用するには難解な機能なんだ。連中がそれらを批判して取り除こうとしたら、ある意味愛用者が多いデコレータを否定する事に繋がってしまう。
また、Pythonのラムダ式を取り除くどころか、強化すべきだ、と言う観点さえ与えてしまいかねない。
そういう機能が「デコレータ」なんだよ。
ところで。
「デコレータって何?」と言う問いに関しては簡潔に答えよう。言っちゃえば、デコレータとは単なる高階関数だ。もっと詳しく言うと、
- Pythonで言うデコレータとは関数Aを受け取って関数Bを返す高階関数の事
だ。これがPythonでの「デコレータ」の定義だ。
いや、機能的に言うとそれ以外無いんだ。ついつい@何とか、と言うブツをデコレータって呼びたくなるが、機能的に言うとそっちはデコレータじゃない。デコレータはあくまで「関数Aを受け取って別の関数Bを返す」高階関数の事なんだ。
まずここを押さえないと、@何とかの定義方法は?とかその意味は?とか混乱するだろう。
いずれにせよ、高階関数を除けてデコレータを理解する事は不可能だ。そして高階関数を理解しているPythonicな奴らは極めて少ない。結果、公式ドキュメントで「デコレータの作り方」なんつートピックは扱えない、って事になる。
当然ながら、普段から高階関数を作って使ってない奴らがデコレータを書けるわけがないんだ。
まず、高階関数をちと復習しよう。
一般に、高階関数は「関数を引数に取る関数」か「関数を返り値とする関数」を指す。
当然、Pythonに於けるデコレータ、つまり「関数Aを引数に取り関数Bを返り値とする関数」と言う「合わせ技」も高階関数って事になるんだけど、取り敢えずザーッと基本の「関数を引数に取る関数」と「関数を返り値とする関数」を見てみよう。
代表的な「関数を引数に取る関数」として、このブログで度々取り上げるfunctools.reduceがある。
例えば、リストの特定の条件を満たした要素を削除する場合、Pythonでは通常リスト内包表記を用いてフィルタリングするが、functools.reduceを使ってremove_ifと言う関数を書いてみよう。
def remove_if(pred, lst):
from functools import reduce
return reduce(lambda y, x: y if pred(x) else [x] + y, reversed(lst), [])
この関数、remove_ifは高階関数functools.reduceを使って組み上げられてはいるが、このremove_if自体も「関数を引数として取る」高階関数で、predは関数を想定し、ここで削除したい条件を記す。
# リストの要素から奇数を削除する例>>> remove_if(lambda x: x % 2 != 0, [1, 2, 4, 1, 3, 4, 5])
[2, 4, 4]
また、functools.reduce自体の定義も見てみよう。

見た通り、引数に関数functionを取り、内部的にその関数functionを利用して値を計算している。
デコレータを書く前に「この程度の」高階関数を書ける技術は必須なんだ。
次に「関数を返す」高階関数の例を見てみよう。
毎度毎度お世話になるが、一番シンプルな例はポール・グレアムが掲げたアキュムレータになると思う。
def foo(n):
def bar(i):
nonlocal n
n += i
return n
return bar
関数foo内でローカル関数barを定義して、そのローカル関数barを返す。
他には、このブログで書いたオブジェクト指向の仕組み、なんかの記述法が「関数を返す関数」の例だ。
ここまでが基礎、だ。
ここからデコレータの例に入っていく。
ところで、Web上にある「デコレータ」の例示なんつーのはこんなんばっかだ。
def hello(func):
def inner():
print("Hello ")
func()
return inner
今までの「関数を引数に取る」例や「関数を返り値とする関数」の例を理解していればこの関数定義自体を理解する事は然程難しくないだろう。しかし例によってprint頼りだ。
定義自体は高階関数さえ分かっていれば理解するのは容易だが、かと言って全く役立つ例だとは思えない。
ちなみに、RacketなんかでのLispだと上の関数は次のように書ける。
(define (hello func)
(lambda ()
(displayln "Hello ")
(func)))
Pythonに比べるとシンプルだろう。なんせラムダ式を設定してそれを返せば済むんだ。
これはLispだけ、の話じゃなくって、マトモなラムダ式が使える言語だったら多かれ少なかれ同じだ(※1)。
// JavaScriptでの例(※2)function hello(func) {
return () => {
console.log("Hello ");
func();
};
}
# Rubyでの例(※3)def hello(func)
->{puts("Hello ")
func.call()} # ここはfunc.()と書いても良い
end
Pythonの場合、innerのようなローカル関数を定義してるのは、単にPythonのラムダ式は複文を取れないから、ある意味、苦肉の策としてローカル関数が定義されている。
まぁ、ここまではいいだろう。
問題は、だ。
ここで@が付いた例が出てくるんだけど、こんな例だと「何故にこんな記法が必要なのか」サッパリ分からんだろう。「便利だ便利だ」とは言っても「どこが?」になりかねない。
上のデコレータに対しての良くある例示はこんなカンジだ。
@hello
def name():
print("Alice")
ここでもprint塗れ、だ。
で、nameを実行するとこうなる。
>>> name()
Hello
Alice
「で?」ってのが感想にならないか(笑)。
そもそも、この程度の「効果」なら@何とか、なんざ使わんでもフツーに関数nameを書き、
def name():
print("Alice")
次のようにして実行すれば済む。
>>> hello(name)()
Hello
Alice
何も@を使わなくてもいいんだ。オブジェクト指向の「仕組み」やここでも見たが、hello(name)()と言う表記は異様だが、helloが引数に関数(この場合はname)を受け取って関数を返す以上、hello(name)は関数になる。結果、それは(nameが引数を求めないので)無引数関数なんで空のタプル()を与えれば「関数実行」になるわけだ。
実際、この例だとこれで問題なく実行出来るし、Lispに明るい人ならこの記述法の方を好むだろう。
こんな例だと、全く@を使った構文の何がメリットなのか分からないんだ。
もう一つ、デコレータの「良くある」説明が混乱に拍車をかけるだろう。
例えば、あるサイトでは次のような説明が書かれている。

こんな説明は混乱を招くだけ、だと思う。
繰り返すが、デコレータとは機能的な意味で言うと@を使った構文ではなく、「関数Aを引数で受け取り、関数Bを返す」高階関数の事だ。
従って、出来る事は高階関数が出来る事以上のモノではない。
ましてや「処理の追加や変更」が必ずしも行われるわけじゃないんだ。
例えば次のような例を考えてみよう。
def decorator(func):
def wrapper():
global _h
func()
_h = "fuga"
return wrapper
@decorator
def main():
global _h
_h = "hoge"
while True:
print(_h)
これは無限ループする例だが(終了にはCtrl-CかCtrl-Dする)、main関数はグローバル変数_hを"hoge"として定義している。
問題はデコレータ側でその_hを書き換えて"fuga"に変更可能なのか、と言う辺りだが当然ながら不可能、なんだ。何故ならmainは無限ループをするんで、永遠に_hを"fuga"に書き換えるチャンスは到来しない。
「いやでも、無限ループする関数なんざ書くからそうなんじゃない?」って思うかもしんない。ある意味その通りではあるんだけど、そこで書かれてる「すでにある関数」でそういうパターンのモノもあるんだよ。有名ドコだとGUIのmainloopとか、だよな。こいつの動作が気に入らなくって、デコレータで変更したい、っつっても不可能なんだ。
と言うか、高階関数であるデコレータはある関数をいわば「ラップ」する事は可能でも、関数が定義してる某を変更したりは出来ないんだ。
少なくとも、高階関数をキチンと理解してるならこんな杜撰な説明はしないだろうし、高階関数を使ってない人間にデコレータを説明する事も不可能なんだ。
もう一つ問題としては既存の関数と言う意味だ。これが極めて曖昧な言い回しなんだよ。
例えば上の(例にならない)単純な例を見てみよう。
def hello(func):
def inner():
print("Hello ")
func()
return inner
def name():
print("Alice")
これを書いた時点で、nameは定義され既存の関数と化す。
ところが、既存の関数nameは@でデコれないんだ。
>>> @hello
... name
SyntaxError: invalid syntax
ご覧のようにエラーになる。
と言う事は、フツーでは、Pythonの組み込み関数も関数名でデコる事は不可能、って事になるんだ。
一体何がどうしてデコレータで既存の関数の変更が可能、なんて事を言い出したんだろう。
事実上、ちょっと後で見るが、@構文(って言い回しをここではするが)は関数定義構文、あるいはその拡張なんだ。
よって、@構文は既存の関数をどうにかする構文じゃない。これが出来るのはdefと同様の関数定義、なんだよ。
とまぁ、Web上でPythonのデコレータの作り方を検索するとロクな例や説明が引っかからない。
よって、ここではPython用語で言うトコでの最も有名なデコレータを紹介し、@構文が一体何をやってるか、を説明してみよう。
単純に言うと、メモワイズ関数とは、それこそ関数をデコレートするための関数で、何らかの計算負荷がかかる計算を、一回計算が済んだものはメモリ上に保持しておき、もう一回その計算が行われる際、再計算せずに保存したデータから値を持ってきて、計算量を減らそう、と言うテクニックだ。
Pythonでは単純には次のように定義する。
def memoize(fn):
cache = dict()
def wrapper(*args, **kwds):
try:
return cache[args]
except KeyError:
cache[args] = fn(*args)
return cache[args]
return wrapper
辞書型としてcache(キャッシュ)を定義しておく。
ローカル関数wrapperは引数argsが来た時にそれをキーとして辞書cacheから対応する値を返す。
一方、キーに対応する値が見つからない場合、キーエラー(KeyError)例外が生じるので、その際、引数に与えられたfnを使って値を計算した後それをcacheへと登録し、改めてcacheから対応する値を返す。
メモワイズ関数は別名「キャッシュ化技法」とか厳しいカンジで呼ばれるが、やってるこたぁ大した事がない「最適化技法」だ。これで一旦計算した値は再利用可能となる。
なお、Pythonでは*argsと言うのは「可変長引数」を意味するが、それはタプルとしてまとめられる。また、リストと違ってタプルは辞書型のキーとなる事が可能だ。
従って、可変長引数の関数だろうと、その引数はまとめて辞書のキーになれるんだ。
さて、ここで単純な実験をしてみよう。
timeモジュールからsleepと言う関数をimportして次のような関数を書いてみる。
from time import sleep
def foo(x):
sleep(5)
return x
関数fooは単純な関数で、引数で受け取った値をそのまま返す関数だ。ただし、副作用として、「5秒間停止」する。
言い換えると、引数をそのまま返すまでに「5秒間」かかるわけだ。
次に、メモワイズ関数で関数fooをデコり、変数slowidへと代入しておく。
>>> slowid = memoize(foo)
そしてcProfileをimportしたあと、次のようにする。
>>> cProfile.run("slowid(1)")
結果は例えば、僕の実行環境だと次のようになる。

予告どおり5秒、正確には実行には全体で5.002秒かかった、と計測してくれる。
なお、slowid(1)と言うたった一回の関数呼び出しに対してPythonのバックグラウンドで走る関数を含めて、総数で1,571回も関数呼び出しが行われてるのが驚きだ。
しかし、同じくcProfile.run("slowid(1)")と2回目を実行すると次のような驚くべき結果を目にする事だろう。
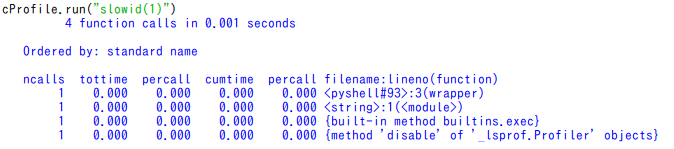
全く同じ関数slowidを実行した筈なのに実行時間が大幅に低減されてて、その実行時間は0.001秒だ。と言うかsleepが実行されていない。
また、1,500回以上あった「関数呼び出し」もたった4回に減っている。
これがメモワイズ関数の効果、だ。
細かく見てみよう。
関数slowidの初回実行時、メモワイズ関数の辞書型(cache)には何も登録されてない。従ってtry節のcache[(1,)]は失敗しKeyError例外が送出され制御はexcept節へと移行する。
そこで、まずはcache[(1,)]に対してfoo(1)を計算してその値(1)を登録する。そしてfooが呼び出された以上、ここで5秒間待たされるわけだ。
そして改めてcache[(1,)]が検索され、その値を返す。
これらが初回実行時のslowidの動き、だ。
しかしながら、2回目の実行時の時にはメモワイズ関数のcacheにはキーが(1,)、値が1と言うペアのデータは登録済みだ。従って、slowid(1)と言う呼び出しでメモワイズ関数のtry節が実行され、今度は性交成功する。辞書型cacheを検索するだけ、で結果は出て、関数fooの出番はない。よってsleepも実行されない。
これがメモワイズ関数の「動き」だ。cacheにデータが登録されてなかったら、与えられた引数である関数を使って値を計算するが、登録されていたらcacheのデータ検索で発見した値を返すだけ。
結果、大幅に計算プロセスを減少出来るわけだ。
とまぁ、強力で、イイこと尽くめに見えるメモワイズ関数なんだけど、実はこのままじゃあんま役に立たないんだ。
と言うか実用性がない。
例えばここで、みんな大好き、フィボナッチ数列を考えてみよう。

もちろん、フィボナッチ数列自体はwhileでも書けるんで、もっと効率的に記述は出来るが、ここでは定義通りな非効率版を用いる。
じゃあ、この非効率版フィボナッチ数列はメモワイズ関数で最適化可能なのか、と言うと最適化されない、んだよ。
試してみよう。
>>> memoize(fib)(30)
多分おっそろしく計算に時間がかかるか、あるいは「計算が終わらない(あるいは終わるように見えない)」って事になるだろう。
一方、@構文を使って次のようにフィボナッチ数列を定義したとする。

今度は一瞬で計算が終わるんだ。
>>> fib(50)
12586269025
これが、@構文を使ってデコレータを利用した関数定義のメリット、なんだ。
しかもこれに付いて解説しているサイトは全く見当たらない。
一体、@構文とは何なのか。
@構文の正体、を解説する前にちと実験しよう。
問題は、メモワイズ関数内のcacheがどういう状態なのか、を逐一チェック出来ない、と言うトコロにある。
そこで、あくまで実験の為に、メモワイズ関数内のcacheをグローバル変数として外に出してしまおう。
もちろん、本来ならcacheはメモワイズ関数内にあるべきだ。何故ならこの関数はcacheと言う「状態」を保持するトコにポイントがあるし有用性があるんだけど、そうしてると外部からその「状態」を覗けない。
結果、「実験の為に」敢えてcacheをグローバル変数として書いてしまおう。
cache = dict()
def memoize(fn):
def wrapper(*args, **kwds):
try:
return cache[args]
except KeyError:
cache[args] = fn(*args)
return cache[args]
return wrapper
そして、フィボナッチ数列じゃちと複雑なんで、代わりに階乗関数factorialを考えてみる。

これももっと効率的に書けなくはないが、実験の為に敢えて定義通りの、しかもPythonが苦手な再帰で書いている。
さて、次のようにして走らせてみる。
>>> memoize(factorial)(10)
3628800
さすがにこの程度だと、いくら再帰が苦手なPythonでも許容出来る計算量だ。
しかし興味はそっちじゃない。cacheがどうなってるか、だ。
見てみよう。
>>> cache
{(10,): 3628800}
まぁ、想定通り、ってば想定通りだよな。キーが(10,)と言うタプル、そして値が3,628,000って値のペアが生じてる。
ここで一旦cacheを初期化しよう。
>>> cache = {}
次は@構文を使ってもう一回階乗関数factorialを定義してみる。

そしてfactorialを実行してみる。
>>> factorial(10)
3628800
今度はcacheはどうなってるのか。
>>> cache
{(1,): 1, (2,): 2, (3,): 6, (4,): 24, (5,): 120, (6,): 720, (7,): 5040, (8,): 40320, (9,): 362880, (10,): 3628800}
なんと、factorial(10)のデータだけじゃなく、factorialの定義上その計算に必要になってた、factorial(1)〜factorial(9)のデータが全て揃っている。
繰り返そう、これが@構文のメリットなんだ。
では@構文の仕組みを説明しよう。
その前にもう一度cacheを初期化しておき、factorialを@構文を使わずに定義しなおしておく。
そして今度は次のようにしてみる。
factorial = memoize(factorial)
関数と同名の変数を用意し、メモワイズでデコった関数を代入する。
一見、こうすれば、関数factorialがぶっ壊れたように見えるだろう。その通り、だ。
しかし、これは意図したぶっ壊し、なんだ。
またもやfactorialを実行してみる。
>>> factorial(10)
3628800
cacheを覗いてみよう。
>>> cache
{(1,): 1, (2,): 2, (3,): 6, (4,): 24, (5,): 120, (6,): 720, (7,): 5040, (8,): 40320, (9,): 362880, (10,): 3628800}
なんと、今度は@構文を用いて定義したfactorialと同様の効果が見られる。
ここまで来ると、@構文が何をどのように定義してるのか、と言うのが朧気ながら分かってくる筈だ。
- @構文は@に続くデコレータ名により、どの関数をデコレータとして利用するか指定する。
- 続いてデコレータでデコられる関数を定義する。
- 2.の関数名と同名の変数を自動生成し、デコレータにデコられた2.の関数を代入する。
- Pythonでは関数はファーストクラスオブジェクトな為、3.で定義された変数は関数(しかも2.の関数名と同じ)として機能する。
これが@構文が行う事の全て、だ。特に2.の作用として、事実上@構文は関数定義、あるいはdef構文の拡張だ。
Lispに詳しい層だと、@構文は事実上、次のようなマクロに等しい、ってのが予想がつくだろう。
;; Racketでのマクロ例(define-syntax @
(syntax-rules (define)
;; 実はここで指定するdefineは関数定義ではなく、構文要素としてのdefineとなる。
((_ decorator (define (head arg ...) body ...))
(begin
;; 関数定義を行い
(define (head arg ...)
body ...)
;; 同名の変数名にデコった関数を代入する
(set! head (decorator head))))))
んで、恐らく、だが、@構文下のdefは@構文下にないフツーのdefとは違って、@構文の要素になってるんじゃないか、と思われる。要は@構文下のdefは切り離せない(まぁ、切り離す必要はねぇんだけど・笑)。
いずれにせよ、これが@構文がやってる事の全て、だ。
なお、蛇足ながら、上のプロセスを見てて、特に3.の「2.の関数名と同名の変数を自動生成し、デコレータにデコられた2.の関数を代入する」ってプロセスが気持ち悪い、って人もいると思う。「関数をぶっ壊してるだろ?」と。「なんでそれなのに正常に動いてるのか?」と。
上の元々のメモワイズ関数とfactorial関数のコンビネーションに戻ってみよう。もう一回確認するが、元々のfactorial関数の定義は次のようになっていた。
関数factorialは内部的にfactorialを呼び出す。つまり、再帰的定義だ。
そしてメモワイズ関数でデコって初回呼び出ししてみる。
>>> memoize(factorial)(10)
3628800
さて、初回呼び出しに伴ってメモワイズ関数はtry節でcacheから(10,)をキーとするデータを見つけ出そうとするが、生憎それは見つからずKeyError例外が生じ、結果制御はexcept節へと移る。
そこで、引数にあたるfactorialを使ってfactorial(10)を計算し、その結果をcache[(10,)]へと登録する。ここまではいい?
当然factorialは再帰関数なんで内部的にfactorialを呼び出す・・・が、実はこの過程に於いては、内部的に呼ばれたfactorialはcacheに登録されない、んだ。何故なら、当然そこのfactorialはメモワイズ関数でデコられていない。ここもメモワイズでデコられていれば、再帰関数である以上、その処理も効率的になる筈、なんだ。
つまり、@構文が行ってる
factorial = memoize(factorial)
と言う「関数名と同名の変数を生成してメモワイズでデコった関数を代入する」行為は、この再帰呼出しされた関数factorialを強制的にメモワイズでデコられたfactorialに変更する効果がある、んだ。
これを図示してみよう。
最初は関数factorialは次のようになっている。
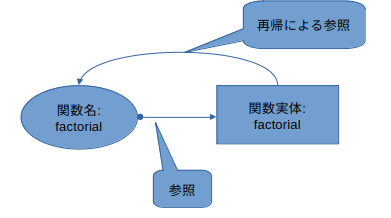
関数名factorialは事実上変数名で、関数を実行する「関数実体」が代入されている(※5)。そして厳密に言うと「代入」と言うのは間違いで、変数factorialはポインタを持っていて、関数実体のfactorialを指している。これを束縛と言う。
また、低レベルでは変数factorialは一種のタグ名だ。関数実体factorialは再帰関数だったんだけど、自分を直接呼び出す、と言うよか、そこに埋められてるタグを指定すると、関数名factorialがやってきて、そこからまたポインタを手繰って・・・と再帰が実現される。
ところが、
factorial = memoize(factorial)
を実行すると変数名factorialのポインタが指す先が変更されるんだ。

細かく見て行こう。
Pythonは先行評価の言語なんで、memoize(factorial)と言う表現を見つけるとまずは引数を評価しようとする。この場合の引数はfactorialだよな。そして変数名(タグ)factorialを見て、それを実体化する。Pythonでは関数はファーストクラスオブジェクトなので、データとして解釈し、引数が利用するポインタは関数実体であるfactorialを参照するわけだ。
その後、factorial = memoize(factorial)と言う全体表現により、タグ名(変数名)factorialのポインタが指してる先は関数実体であるfactorialからmemoize(factorial)へと変更される。
ここで気をつけなければならないのは、通常、変数の再束縛が生じた時、Pythonではガベージコレクタにより、「最初に指していた」古いデータは破棄される筈、なんだ。
ところが、memoize(factorial)と言う指定を最初に行ってる為、引数が持ってるポインタは相変わらず古い(筈の)データ、関数実体のfactorialを指している。
そして、ガベージコレクタは一般に、「ポインタが指してる」データは破棄しないんだ。言い換えると、ガベージコレクタがメモリを掃除するのは、どのポインタもそのメモリのセグメントを指してない時に限る、んだ。
結果、memoize(factorial)の引数factorialは古いデータである筈の関数実体factorialを指し、一方、変数名factorialはmemoize(factorial)と言う関数実体を指す。memoize(factorial)は実行された時、cacheに適するデータがある場合は、そのデータを参照してその値を返す。一方、データが発見出来なかった時には、関数実体factorialを呼び出して実行する。
factorialは再帰関数なんで、内部にあるタグ名を利用して変数factorialにアクセスするが、変数factorialの参照先はmemoize(factorial)へと変更されている。よって自分自身を再帰呼出しはされず、変数factorialの新しい参照先、memoize(factorial)が呼び出される・・・・・・。
ってのが起きてる事なんだ。
Pythonのデコレータに付いては以上、かな。
繰り返すが、Pythonのデコレータに付いて理解するには、まずは関数型言語「らしい」高階関数を理解する事。Pythonicな態度だと恐らく理解出来ないだろう。ここには関数型言語で培われたノウハウが詰まってる、んだ。
そして恐らく、これを理解する一番簡単な例は、上で書いてきたようなメモワイズ関数だ。これが典型的なデコレータなんだけど、実はそんなに難しくない、ってのは見てきた通りだ。
是非ともメモワイズ関数の攻略を基礎として、Pythonのデコレータを攻略して欲しい。
※1: しかしながら、理論的にはラムダ式は複文は取れない。従って「理論的に正しい」のはPythonのラムダ式の方だ。
通常、ラムダ式を持ってるプログラミング言語は「理論的に正しいかどうか」より「便利か否か」を優先して設計してる。
※2: JavaScriptには入出力がない。よって厳密な意味ではconsole.logはブラウザの機能であってJavaScriptではない。
※3: Rubyの場合、メソッド(いわゆる関数)は変数とは名前空間が分かれている(Lisp-2)。従って、引数にシンボルとして渡されたメソッドにはANSI Common Lispのfuncallにあたるcallを適用しなければならない。
※4: 実はPythonでは@functools.cacheとして組み込みデコレータになっている。
※5: 通常、多くのプログラミング言語では、関数名と変数名は同一の名前空間にあって差異はない。これを(Lisp以外でも)通称Lisp-1と呼び、PythonもLisp-1の言語だ。













