








ここのところMSXやX68000など昔のパソコンが注目されるようになってきました。その影響で昭和のパソコンやゲームが懐かしくなり、時々古いパソコン(マイコン)雑誌を読み返したりしています。そこで気になるのが雑誌に掲載されているゲームなどのプログラムリストです。
かつて手入力することを断念したプログラムも、今ではOCRソフトで読み取ることができるので実機で動作させてみたくなるのです。
でも、フリーのOCRソフトは文章の読み取りは出来ても、BASICプログラムリストやマシン語ダンプリストをきちんと読み取ってくれるものはほとんどありません。自分が知っている限りでは、こちらのProgram List OCRだけです。
これまで何度か雑誌のプログラムリストをProgram List OCRで読み取り、こちらのDumpListEditorで修正およびバイナリファイル変換を行ってきました。とにかくこれしか選択肢がなかったからです。
どちらのソフトも素晴らしく、特にProgram List OCRのマシン語ダンプリストの読み取りはかなり優秀でした。
ところがBASICプログラムではそうはいきません。原稿によって、うまく読み取れるものとまったく読み取れないものがあるのです。また、読み取ったテキストデータも修正箇所が結構あって少し苦労します。
そこで、無料で使えるGoogleドライブのOCR機能ででBASICプログラムリストを読み取ってみたらどうなるのだろうと思い付き試してみました。
GoogleのOCRを使ってみると、文字の読み取りは優秀でかなりの精度で読み取ってくれました。ところが、プログラムリストのレイアウトが大きく崩れてします。手作業で元の形に修正することは可能でしたが、かなり面倒です。
ただ、修正作業は複数に分割された行を一行にするとか、文字や記号の間に入ったスペースを削除するとか同じようなことの繰り返しが大部分でした。それならばこれらをプログラムで処理すれば、単純作業をある程度自動化できるのではと考えたのです。
OCRで読み取ったテキストを修正するソフトウェアを作成すれば、GoogleのOCR機能も少しは実用的に使うことができるかもしれません。
ということで実際にソフトウェアを作成して、これらのOCRエンジンで利用したときにどれが一番効率よくプログラムリストの読み取りに使えるのか試してみることにしました。
ただ、ProgramListOCRで使用しているTesseract(テッセラクト)とGoogleのOCRエンジンを比較するだけではつまらないので、Windowsに搭載されているOCRエンジンも合わせて試してみることにしました。
そんな訳でまずはOCRエンジンで読み取ったテキストのレイアウト修正を行うソフトを作成しました。
ダウンロードはこちらから。DumpListTool.zip (右上のダウンロードボタンを押してください。)
プログラムはWindowsの.Net6でWPFを使っています。開発はWindows11で行いましたが、たぶんWindows10でも動作すると思います。(未確認)
解凍して出来たフォルダーの中に以下の3つのプログラムが入っています。
DumpFormater.exe ProgramListOCRとGoogleのOCRで読み取ったテキストのレイアウト修正プログラム
DumpCutter.exe GoogleのOCRで読み取る画像ファイルを加工するためのプログラム
BasicOcrReader.exe WindowsのOCRエンジンを使うためのプログラム
使用方法についてはまた後で説明します。これらのプログラムはテスト用に作成した物なので動作の保証はしません。また、これらのプログラムで被ったいかなるトラブルに関して責任はもちませんので、ご了承ください。
読み取りに使用する画像ファイルですが、あまり大きすぎるとOCRソフトで読み取るときに時間がかかるのとWindowsOCRのデフォルトの最大画像サイズが一辺10000ドットまでとなっていたので、それより小さなサイズにしました。OCRソフトに読み込む前にトリミングするので画像サイズは一定ではありませんが、トリミング前の画像の長い方の辺が4000~6000ドットで72dpiの画像を使用しました。
また、画像は読み取り前にグラフィックツールのgimpで以下のような加工を行っておきました。
1.傾きを修正
OCRで読み取りたい画像ファイルをgimpにドラッグ&ドロップして読み込ませたら、傾いたプログラムリストをなるべく真っすぐにします。後で説明しますがGoogleOCRで読み取るマシン語ダンプリストは上記ダウンロードのDumpCutter.exeで加工する必要があり、リストが斜めになっていると不都合が起きるのでこの作業が必要になります。
gimpでShift+Rを押すと回転ツールが表示されるのでスライダーをマウスでドラッグして画像を回転させます。スライダーにフォーカスがあるときはキーボードのカーソルキーでより細かい回転が行えます。さらに細かく回転させたいときは角度の項目に直接数値を入力します。
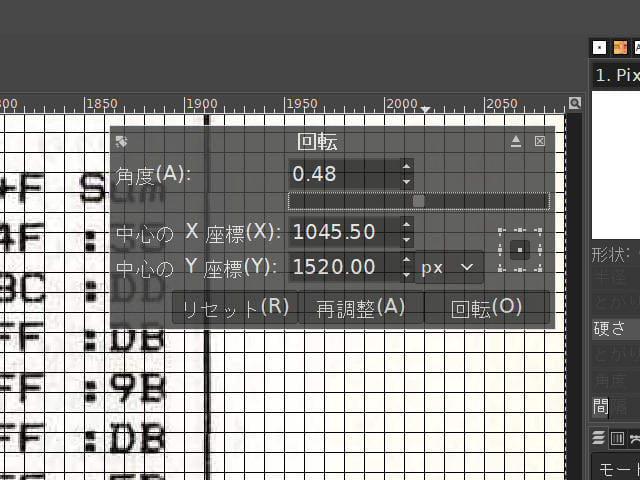
回転作業の時にグリッドを表示させておくと目安になって便利です。gimpのメニューから「表示」→「グリッドの表示」を選択するとグリッドが表示されます。メニューの「表示」→「表示倍率」で画像を見やすいサイズにして作業します。
雑誌によってはリストが90°回転されて印刷されているものもあり、スキャン画像を90°回転してレイヤーからはみ出すと、はみ出した部分の編集が出来なくなるので「画像」→「キャンバスをレイヤーに合わせる」で編集可能にします。
2.トリミング
画像で読み取りを行いたい部分を切り取ります。見出しやページ番号や枠線などがあると、OCRエンジンがこれらも文字変換してしまい、誤変換やレイアウトが崩れる要因の一つとなってしまいます。
gimpでトリミングする方法はいくつかありますが、今回はShift+Cで切り抜きツールを起動します。切り抜きたい部分を左上の座標から右下までマウスでドラッグして範囲指定します。指定後でも範囲指定の縁をドラッグすると範囲を変更できます。

最後にリターンキーを押して切り抜きを確定します。
3.文字と背景の明暗をはっきりさせる
メニューの「色」→「脱色」→「グレースケール化」でOKボタンを押して色を消すと背景の紙の汚れや凹凸、裏ページの印刷が見えてきます。次に「色」→「明るさ・コントラスト」でコントラストのスライダーをマウスでドラッグして背景の汚れを白く飛ばしてOKボタンを押します。文字が少し白くかすんでしまうので最後に「フィルター」→「強調」→「シャープ(アンシャープマスク)」でOKボタンを押して文字を黒くしメリハリをつけます。




画像の加工は以上です。ProgramListOCRでは多少の画像修正を行うことができますが、今回は使わず上記の手順で加工した画像を使用しました。
最後にCtrl+Shift+Eでエクスポート画面を出して画像を保存します。拡張子によって出力する画像の形式を変えられますが、後で再修正しても画像の劣化が起こらない.png形式で保存することをお勧めします。
これで準備は整いましたのでOCRエンジンを試したいところですが、長くなりそうなのでまた後程。










※コメント投稿者のブログIDはブログ作成者のみに通知されます