
うーむ、ちと失敗した。
星田さんの記事を読んでたんだが、こっちで敢えて指摘しなかったせいで、余計な混乱を招いたかもしんない。
言い訳すると、実はこの記事を書いた時点では、Gaucheのモジュール作成の方法とメソッド作成法を軽く紹介したかった、ってのがあって、まずは「皆が思いつくような」レコード型を利用した解法を提示した。
そして演習17-6に付いては「皆が思いつかない」星田さんの解法に合わせた解を書いたつもりだった。
星田さんの記事で、
次回はmatch-lambda*版のtree_mapを勉強させてもらいます(^o^)
って書いてたので、すっかりレコード型から離れて星田さん方式で書いてくのかな、とか思ってたんだ。
どっちにせよ、星田さん方式に付いては改めて書いておいた方が良いだろう、と準備はしてた。実はレコード型を使ってない星田さんの方式が間違ってる、とは一切言ってなかったつもりなんだけど、なんか誤解を与えたみたいで、結果、「2022/10/27 プログラミングの基礎の続き」の記事ではレコード型の方式と星田さんの方式が混在してて、すっかり混乱してしまったように見える。
ゴメン。
つまり、星田さんの方式とは二分木のEmpty、Leaf、Nodeと言うデータに対して、単純に、


みたいに、リストに対してシンボルをconsして「型」とする方式だ。
一方、僕がやったのはマジメにレコード型でデータ型を生成する方式だ。多分フツーはこっちをやるだろうし、OCamlのコードの直訳、って考えればこっちの方だろう。
しかしながら、星田さんの方式にもメリットがある。なんせ、データ型をわざわざ「形式的に」作る必要がない。そしてGaucheのユニットテストの問題を考えてみても等価判定述語をわざわざ作らんでもいい。
詳しい話はSICPに譲るが、星田さんが採用した方式をタグ付きデータと呼ぶ。リストのような合成データにその名の通り「タグ」を付けて、そのタグ名をもって型とする、と言う方法論だ。
これは別にSICPと言う教科書での机上の空論ではない。実際に使う場面がある方法論だ。
例えば、古くはLispマシンのデータ構造に用いられてたらしい。
LispマシンのCPUと言うのは、現行の、例えばIntel製チップのようなブツと違って、物理的にLispそのものがハードウェアだ。CPU自体が例えばSchemeで言うトコのpair?、eq?、car、cdr、cons等を機械語として持っていて、それらをそのまま実行する。
そしてそれらに与えられるメモリ上のデータ構造は、タグ付きデータ、が基本になる。LispマシンのCPUはそのタグを見て、ふさわしい演算を選んで実行するわけだ。
また、プログラミング言語を「作る」際にも用いられる事も多いだろう。プログラミング言語をプログラミング言語で作る際、作る側のデータをそのまま流用する事もあり得るが、一方、「新しいデータ型を与えなければならない」場合は、タグ付きデータが尤も明解な方法の1つだろう。
つまり、

match-lambda*を使ったtree_mapを。これ、バッククォート記法間違ってるんですが数字は倍になってるのでこの時点で気づけてません。
ってのは誤解で、単純にこれは星田さんが作った「タグ付きデータ」の方法論で書かれた関数だ、って事だ。
これがレコード型を採用した方式だと、

と書き換えないといけない。
従って、仮に「タグ付きデータ」で問題を解くと、
演習17-6
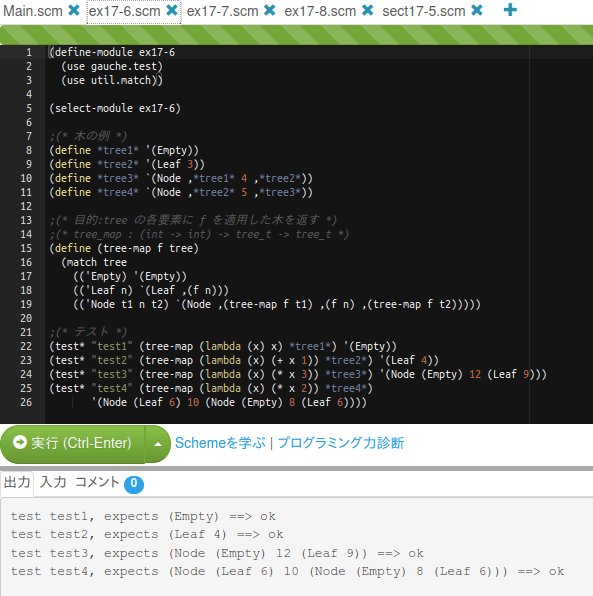
演習17-7

演習17-8

セクション17-5



となるだろう。=> PAIZAでのコード例
結果、レコード型でやろうと、タグ付きデータでやろうとどっちでもいいんだけど、混ぜるな危険、って事だ(笑)。
そしてレコード型での定義や等価判定メソッドの定義が要らない辺り(※1)、簡易性だけで言うと、タグ付きデータの方針は悪くはない、って事になる。
結果、ファイル構成がレコード型での形式に比べると簡素化している。
なお、SRIF-9にも一応参照実装が載ってるが、ここでは、甚だ不完全だけど、R7RSのdefine-record-type自体が、原理的には大体次のような実装だ、と言う事を紹介しよう。

もう一回繰り返すが、説明の為に作ってみただけで甚だ不完全だ。
しかしいくつか重要な事は説明可能だと思う。
まず、define-record-typeはマクロだ。
そしてこのマクロの特徴は、define-record-typeの書式を与えて実行すると、原理的には複数の関数を同時に生成する。
その「複数の関数の中身」が、レコード型のコンストラクタ、レコード型の述語、そしてレコード型のアクセサだ(取り敢えずシンプルさを考えてミューテータは外してある)。
んで、以前から言ってるけど、レコード型は原理的にはそれこそタグ付きベクタがその正体だ。まず、レコード型で定義したユーザー定義型名、と言うモノがタグであり、そしてフィールド名もタグだ。
要するに内情を言うと、星田さんが考えてたデータ構造そのものをレコード型は内包している。
Schemeではレコード型を使ってユーザー定義型を作ると、自動で述語が定義されるが、それは要するに、与えられたレコード型の「タグ」が特定のシンボルと一致してるかどうか調べてるだけ、だ。eq?で一致すると#tを返し、そうじゃなければ#fを返す、と言う、原理的には至極単純な仕組みとなっている。
フィールドにもタグが付けられているので、特定のフィールド名でアクセスすればそのタグを拾って関連付けられたデータを引っ張ってくる、と言う・・・割にアイディア自体は単純なモノだ、と考えて良い。

いずれにせよ、表面に出てこなくても、Schemeのレコード型自体も星田さんが考えてたような「仕組み」が裏にある、と言ったような話だ(※2)。

この説明ホント分かりにくい(と思う)。両方共(lambda expr (match expr clause ...))で一緒だし(-_-;)
うん、分かりづらい(笑)。
気持ちは良く分かる。
ただ、lambda式が「ちょっとだけ」違うんだよ。
- match-lambda => (lambda (expr) (match expr clause ...)
- match-lambda* => (lambda expr (match expr clause ...)
分かるかしら? match-lambdaのlambda式の引数exprにはカッコが付いてるけど、match-lambdaのlambda式の引数exprにはカッコが付いていない。
つまり、後者のlambda式は可変長引数を受け取る、って言ってるんだ。
反面、前者は一引数関数、になる。
もう一度、R7RSのlambdaの項目を調べてみよう。
※1: タグ付きデータで等価判定メソッドの追加が要らなくなるのは、タグ付きデータも「データ形式」なだけで、Lisp上では単なるリストだから、だ。
つまり、素のGaucheのままで、リスト同士の等価判定を用いたテストを行う事が出来る。
※2: なお、ここでの混乱の1つの原因が、Gaucheのmatchに於けるシンボル判定の簡便な記述にある、って事は言える。別にそれ自体は悪い事ではないが。
RacketとGaucheのmatchの違いは、パターンマッチングの評価段階が違う、って事にあるとは思う。Racketの場合、しつこいくらいに、クオートを必要とする記述が多い。
その為に、外から挿入したシンボルを仮にクオートしても「外から来たモノだ」と判別が出来ない。
従って、このようなタグ付きデータを判別する際には、若干煩わしい特殊な記述法が必要になるんだ。

見たとおり、Racketの場合、まるで「記号だらけ」のような表記になる。
繰り返すが、シンボルのconsによって作成したタグ付きデータだが、Racketの場合、その「シンボル」をクオートしてもそのままそのシンボル名は判別出来ない。よって==と言う記号を使って、それが外部から挿入されたシンボルだと明示しないとならない。
一方、構造体を使った記述法と明らかに違ってくるんで、構造体を用いたデザインなのか、タグ付きデータを用いたデザインなのか、は簡単に分かるわけだ。










