
簡単に書けるんじゃね?と思ってたプログラムが全然簡単じゃなくって絶賛詰まり中。
そこで気分転換を図る事とした。
やっぱ「継続」は難しい。
何が困難を生んでるか、っつーとデバッガで捕捉出来ないトコが大きい。ある変数がcontinuationと表示されていても、本当に知りたいのは「その中身」なわけで、そこが辿れない。
人間を泣かせるだけじゃなくって、デバッガ泣かせなのも「継続」なんだ。一見した時「どんな情報を持ってるのか」サッパリ分からん。動作をデバッガで追えないんだ。
これはプログラミング言語泣かせだ。結果「暗中模索」でプログラムを書く必要が出てきて、それがとてもツラい。
となると、何か思いついて「実装する」ってのが極めて難しい。っつーか「応用」はしづらい機能だよな。
ただ、言い換えると「継続が使えるパターン」ってのは既に発表されてるわけで、そのパターン数は決して多くない。と言う事は、「継続が何か理解せんでも」限定されたパターンに於いては「既知の情報」になってるわけで、そこに則る限りは難しくはない、って事は言えるわけだ。「自分で何か開発しよう」とすればドツボにハマるだけでな(笑)。
と言うわけで、継続と戦っていた(笑)。
さて、龍虎氏がどんどんハッカー染みてきている(笑)。面白い(笑)。
Pythonから始まってLisp、Rustと来て今度はLuaにも突入したそうだ(笑)。この手の広げ方、ってのはC言語でプログラミングを始めた人には不可能なんだよ(笑)。ほぼ最初にLispに触ったせいで、基礎体力が付きまくってる辺りで物凄い人になってしまってる(笑)。
やっぱ「ほぼ最初に触ったプログラミング言語が何か」ってのは凄い影響が出るんだよなぁ。
もちろん、Lispをやったから、と言って全プログラミング言語の全コンセプトを把握は出来ない。そんなプログラミング言語はない(※1)。
けど、やっぱ「差分が小さい」んだよね。最初にLispなんかの高抽象度の言語を把握しておけば、「新しく知るべき」差分は当然小さくなるんだ。
これは「最初にC言語をやった」人だと得られない「思考力」になる。それくらい違いがある、んだ。
いや、マジで教育現場でのLispの復権は必要なんじゃないか、って思う。抽象度の高い言語で抽象的に考える訓練をまずはすべきだ、ってホント強く思ってるんだ。ハッキリ言うけど「コンピュータがどう動作するのか」知る必要性ってのはそんなに無いんだよ。何故なら以前書いたけど、「高級言語」ってのは定義上、「コンピュータがどう動作するのか」を隠蔽する為に作られている。ハードウェアが機械式だろうと電子式だろうと「同じように書ける」ってのが高級言語の存在意義で、現在のノイマン式コンピュータでしか「上手く動作出来ない」仕組みを知る事はハッキリ言って、高級言語を使う、って意味だと単なるトリビアに過ぎない。
どうしてもハードウェアの動作を知りたい、って人は、特定のCPUに於けるアセンブリ言語を学ぶか、あるいはこれも何度も言ってるけど、BrainfuckやらWhitespaceなんかの実装をした方が「良く学べる」ハズで、曲がりなりにもそのテの仮想マシン(つまりインタプリタだ)の実装の経験の方が役立つハズだ。
そしてそうすれば「実装する側の言語を選ばない」。
 | コンピュータの構成と設計 MIPS Edition 第6版 上・下電子合本版 David Patterson 日経BP |
欧米でアセンブリ及びCPUの仕組みを学ぶ際に良く挙げられてる名著。ただし、メインで扱うのは我々が常用してるPCのブツではなく、往年のグラフィックワークステーション、SGIのマシンや、SONY PlayStation、Nintendo 64で使われていたMIPSのCPUを想定している。MIPSのCPUはGoogleを輩出した米スタンフォード大学で開発されたブツで、非常に設計が綺麗で、現行のコンピュータ・アーキテクチャの基礎を学ぶには良いCPUだと考えられている。
余談だけど、教えて!gooなんかの方で、プログラミング初心者に向けて「抽象的に考える事が必要」なんかのアドバイスがある。いや、字面で見てみると「もっともだな」と言うような発言をしてるように思うが、実はこれって「誤用」なんじゃねーの、って疑いがあるんだ。
「抽象的に考える」ってのは「見えないモノの動きを想像する」って意味じゃねぇんだ。もし、「CPUやメモリの動作を想像する」事を「抽象的に考える」と捉えてるなら大間違いだ。それは「具体的に考えてる」んであって、「抽象的に考えてる」んじゃない。この2つはベクトルの向いてる方向が全然違う。真逆だ。
例えばC言語ユーザーが混乱する事に再帰がある。スタックに関数を積んで処理するメモリがあって・・・とか具体的に考えると混乱する典型例だ。再帰を再帰として「そのまま」捉えるのが抽象性であって、「ハードウェア上でどう再帰が動くのか」と考えるのは「具体的に考えてる」だけ、なんだ。
どうも多くのC言語ユーザーは「抽象的に考える」と言う意味が分かってなくって誤用してんじゃねぇの、とか疑っている。そもそも(特定の構造の)ハードウェアベッタリの言語を使ってきて、「ハードウェアがどう動くか」想像してプログラムを書いてる人間が、抽象的に考える、って訓練なんざした事ないだろ。
やっぱLispを知ってる層とそうじゃない層は考え方の基盤が違って、プログラミング初心者はまずはLispを触る、ってのは悪い選択肢じゃないんじゃないか、って思う。C言語とPascal以外の高級言語を扱う際にホントの基礎体力を与えるのはこの言語だと思う。
そして、Pythonはやっぱ捨てるべきだよな。龍虎氏も引っかかったみたいだが、もはやPythonは気軽に使えるプログラミング言語ではなくなってしまった。「要仮想環境」だ。
そしてそんな手間をかけさせるプログラミング言語は初心者向けじゃない。捨てろ。Pythonは完全にJavaみたいな「プロ用開発言語」になっちまった。そしてやっぱ「プロ用」が初心者向けを兼ねる、ってのはなかなかあり得ないんだよ。
Ubuntu系ディストロだけPythonの「要仮想環境」の弊害が大きいのか、とか思ってたら他のディストロもそうなってんのか、とか呆れ返ってる。もはやPythonパラダイスはひょっとしたらWindowsだけ、なのかもしれんが、Windows版だって明日はどうなるか分からない。そもそもPythonは公的仕様があるような言語でもない。そういう不安要素が多い言語で「プログラミング基礎教育」なんつーのは片腹痛い、ってなハナシだ。
さて、今回は「遅延評価」が主なトピックだ。龍虎氏が
多分、ずっと以前にCametanさんが解説してくれてるはずで申し訳ないですけど、ようやく実感を持って頭に入ってくるタイミングが来たって感じかも。
と示唆しているが、その通り、だ。
このブログでも何回も扱っているが、それが「必要だ」と感じるには、個人的経験でも「タイミング」が必要になる。ブラックビスケッツだ(違
 | Timing~タイミング~ ブラック・ビスケッツ Sony Music Labels Inc. |
少なくとも、遅延評価は、かなり「理屈だらけ」で、要は数学的規則性が前面に出てくるような時じゃないと使いづらい。記述ルールが明解じゃないと扱いづらいんだ。
いずれにせよ、遅延評価を一回まとめてみよう。
まず、プログラミング言語に於いての関数の評価の話を基礎としてはじめよう。
繰り返すが、殆どのプログラミング言語では先行評価を採用している。常に引数が最初に評価され、その結果に対して関数が適用され、そして計算が成される。
一般には、先行評価の方が「実装しやすい」と言われている。ただし、こういう問題がある。
例えば条件分岐を考えよう。果たして条件分岐は関数で書けるのか、と言う問題だ。
## Pythonでの例def new_if(predicate, then_clause, else_clause):
return then_clause if predicate else else_clause
これは一見上手く動くように見える。
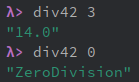
>>> new_if(2 == 3, 0, 5)
5
>>> new_if(1 == 1, 0, 5)
0
しかし、次のような例だと破綻するんだ。
まずは次のような関数を書いてみる。
def dev42(denominator):
return new_if(denominator == 0, "ZeroDenominator", 42 / denominator)
これも一見上手く動くように見える。
>>> dev42(7)
6.0
しかし次のように使うと破綻するんだ。
>>> dev42(0)
Traceback (most recent call last):
File "/usr/lib/python3.12/idlelib/run.py", line 580, in runcode
exec(code, self.locals)
File "<pyshell#3>", line 1, in <module>
File "/home/sun/test.py", line 5, in dev42
return new_if(denominator == 0, "ZeroDenominator", 42 / denominator)
~~~^~~~~~~~~~~~~
ZeroDivisionError: division by zero
仮に関数div42をフツーにif文、ないしはif式で書いたらこういうエラーは出ない。
## こういう定義だったらdef dev42(denominator):
return "ZeroDenominator" if denominator == 0 else 42 / denominator
## エラーにはならない>>> dev42(0)
'ZeroDenominator'
ロジックは同じ筈なのに一体何が違うのか。
答えは先行評価、だからだ。関数new_ifは計算に入る前「与えられた引数を」まずは評価する。結果、predicateもthen_clauseもelse_clauseも計算に入る前にそれぞれの値を得るが、結果その時点で42/0も実行されちまうんだ。predicateが真だろうと偽だろうと関わらず、だ。
つまり、「先行評価」で引数が全部評価された時点で42/0は「ゼロによる除算」って事でエラー対象になる。それがnew_ifによって引き起こされる事、だ。
と言う事は、フツーの条件分岐(ここでのif)はpredicateの結果によって、then_clauseが評価されたりelse_clauseが評価されたり変わるわけだ。片方が評価されたらもう一方は評価されない。言わば、関数と全く違う動きをするわけだ。
言い換えると条件分岐なんかはある種の例外なんだ。関数の先行評価、と言うルールに従っていない。いや、逆に言うと、それら評価規則の例外を構文と呼んでるわけだ(※3)。
先行評価には例外が存在する。
一方、例えばHaskellのような言語(※4)だと次のようなプログラムを書いても問題なく実行される。
new_if predicate then_form else_form =
if predicate
then then_form
else else_form
div42 denominator =
new_if (denominator == 0) "ZeroDivision" (show (42 / denominator))
Haskellは静的型付け言語なんで、関数が返す「値」も同じ型じゃないとならない。結果、ここでは文字列としてる。
Pythonだと失敗した例がHaskellでは上手く動く。それはHaskellが評価規則として遅延評価を採用している言語だから、だ。引数は必要になるまで評価されない。
言い換えると、遅延評価を採用しているプログラミング言語は一貫してて例外が存在しない(※5)。つまり、構文も関数も同レベルで存在する、って事だ(※6)。
いずれにせよ、先行評価のプログラミング言語と遅延評価のプログラミング言語は、言語基盤が全く違うんで、同じ計算結果を出すにせよ、互換性の無い全く別のシステム、って事になる。
一方、先行評価のプログラミング言語で関数の先行評価は変えられないが、データ生成等に於いて遅延評価を一部導入する事は可能だ。
ここでは、そういった「先行評価」のプログラミング言語で、「部分的遅延評価」にまつわる話をRacketを用いて説明していってみよう。
ところでいきなり余談。
「遅延評価」って言い回しを聞くと難しそう、って感じる人が多いかもしんない。「遅延」って単語が怖すぎるんだよな(笑)。
一方、英語ではLazy Evaluationと言って、実は形容詞"Lazy"はどっちかっつーとスラングに近い側の表現だったりする。
詳しい説明は例によってもとこんぐさん辺りにお願いしたいトコだが(笑)、Lazyはニュアンス的には「メンドい」とか「だるい」とか言う意味に近い。

Lazyな人(謎
そう、意外に思うかもしれないが、実は日本語の「遅延評価」と言うようなカッキリとした名前じゃなくって、むしろ柔らかい表現になってる。「メンドイ評価」とか「だるい評価」とか言った方が原語の意味にむしろ近いんじゃないか(笑)。

Rustでイテレータの便利さを知ってしまったのでLuaにある概念なのか心配だったけど、思ってたよりも全然モダンな設計だった。もっとBasic的なものかと予想してたもので。
ところでLuaに付いて。
僕個人は一回も触った事はないんだけど、ある意味物凄く有名な言語ではある。
プログラマが「Luaでプログラムを組む」と言うより、C/C++で書かれたソフトウェアの「マクロ言語」として採用される例が多い。「マクロ言語」じゃ分かりづらければ「ユーザー用機能拡張言語」として組み込まれる事が多い言語処理系だ。Excelに対するVBAとか、GNU Emacsに対するEmacs Lispにあたるような用途なんだけど、「単独処理系」として存在する為、Luaを機能拡張用言語として採用しているソフトウェアだと、一旦Luaを学べば新しく学びなおす必要がなくなる、と言う利点がある。
有名所では、Windows用の動画編集ソフト、aviutilなんかでもエフェクトを記述するマクロ言語として採用されている。
さてイテレータに対してもおさらいしておこう。
日本語では反復子、等と訳されるが、広義だと低レベルの反復を隠蔽しつつ、「何らかの繰り返しを簡単に記述出来る」機能の事だ。Lispのmap、reduce、Pythonのリスト内包表記、なんかは全部広義のイテレータと呼んで良いだろう。
一方、もうちょっと狭い意味だと、実装にもよるが、大体次の2つのパターンに集約可能だと思う。
- 配列等のデータ型に付随した、そのデータ型が持つ自分自身に対する反復処理機能
- データ自体を生成していく機能
Rubyなんかで言うイテレータは1番だ。
一方、Python用語で言うイテレータ/イテラブルは大体のケースで2番を指す。もっと一般的な用語で言うとジェネレータ、と言うのがPython用語で言うトコのイテレータ/イテラブルだ(※7)。
Rustで言うイテレータはPythonで言うイテレータに近いと思われる(もちろん1番も含む場合がある)。
なお、「(ジェネレータも含み)イテレータの便利さを知ってしまった」なら確かに「遅延評価まで後一歩」のトコにいる、って事だ。
システム的に違いは無いわけじゃないけど、イテレータ/ジェネレータと遅延評価は共通する性質が多い(もちろん違う部分もあるが)。
なお、Schemeではジェネレータは一般に、それこそ継続を使って実装する例として良く挙げられる。
一方、個人的には、現象だけ見てみるとむしろ遅延評価を使って定義した方がスッキリするんじゃないか、とか思ってる。
例えばこのようなコードを定義すると、簡単なリストから遅延リスト(ストリーム)を生成出来、nextと言うキーワードで順次値を取り出す事が出来る。
> (define v (iter '(1 2 3)))
> (v 'next)
1
> (v 'next)
2
> (v 'next)
3
> (v 'next)
. . stream-first: contract violation
expected: (and/c stream? (not/c stream-empty?))
given: #<stream>
これが恐らく、一般に望まれるイテレータ/ジェネレータの動きだろう。
このように、解釈しようによっては、イテレータ/ジェネレータは「部分的遅延評価」で書かれたデータ型を破壊的変更しつつ、先頭から値を取ってくるモノだ、と言える。

これは理由にはならないのでは?
一応なるかな。
ただ、先行評価だと受け取るリストを逆順にしてfoldlを噛ませばfoldrと同じになる、ってやってたからね(笑)。

無限リストって・・感覚的にはむしろLeftじゃないと出来ないような気がするが?
実は直感に反して、foldlは無限リスト対象にならない。無限リスト対象なのはfoldrの方なんだ。
教科書通りだとfoldlとfoldrの実装はこのようになる(※8)。
> (foldl - 0 '(1 2 3))
-6
> (foldr - 0 '(1 2 3))
2
> (foldl append '() '((1) (2) (3)))
'(1 2 3)
> (foldr append '() '((1) (2) (3)))
'(1 2 3)
さて、上のコードの#lang racketを#lang lazyへと変更する。これで処理系は遅延評価ベースのLazy Racketへと切り替わる。
そこで次のようなコードを書いて実行してみよう。
(define (findFirstEvenFoldr)
(define result (cons 1 (map add1 result))) ; 無限長の整数リストを生成
(define (firstEven x result)
(if (even? x)
`(,(! x))
result))
(foldr firstEven '() result)) ; 無限長のリストへfirstEvenを適用
内部的にfoldrを使ってるが、プログラムの意図自体は見た通り、「最初に見つかった偶数を返す」だけの簡単なモノだ。答えは2になるだろう。
> (findFirstEvenFoldr)
'(2)
ところが実験してみれば分かると思うけど、これはfoldlを使うと上手く行かないんだ(※9)。
秘密は、一見foldrでも上手く行かないように思うが、foldrは無限長リスト相手に処理しきれないように見えても、与える関数の「条件分岐」に依り、結果、処理できる対象を制御出来るから、なんだ。つまり「無限長リスト」全部を操作せんで済む。
そのロジックがfoldlでは起こらない。
理解力が足りないので定番を知って帰納的に理解するしかねぇ・・ってことでパターンを教えてもらう。あ、Thunkか・・なるほど、1枚関数に包む事で遅延化出来ると
パターンも何も、「理論的」な話をすると、その通り、無引数ラムダ式で実行部分を包む、つまりThunkを作るのが「遅延評価の基礎」だ。
一方、AIが挙げてる例は「並列」と言うよりちょっとレイヤーが違う次元の話を並べてるような気がする。
例えば、冒頭のnew_ifの例を考えてみよう。Pythonで、
def new_if(predicate, then_thunk, else_thunk):
return then_thunk() if predicate else else_thunk()
と書いて、then節とelse節にはThunkを与える、と言うルールにすると、次の関数は上手く動く事となる。
def dev42(denominator):
return new_if(denominator == 0, lambda: "ZeroDenominator", lambda: 42 / denominator)
>>> dev42(7)
6.0
>>> dev42(0)
'ZeroDenominator'
そう、ラムダ式を備えてる言語なら、遅延評価自体は理論的には簡単に扱う事が出来る。
問題は、一々lambdaって書きたいか、ってだけの話と言えば話、なんだ。
面倒だろ、と(笑)。
メモ化もそうなのか?この例はメモ化って感じがあんまり無い気がするけど?
メモワイズに付いてはここで記述している。
問題はメモ化自体が遅延評価なのか否か、って辺りなんだけど、一般的に言うと「違う」だろう。
ただし、実装上、メモ化を利用して実装する、って事は「ある」って話だ。
要はレイヤーが違って、「貴方が使っている遅延評価前提のプログラミング言語で」、遅延評価がどうやって実装されてるのか、と言う話が殆どじゃないか。
その辺の詳しい話はSICPに記述されている。

これも遅延評価になるのか・・
「ならない」(笑)。
ただし、上でも書いた通り、ジェネレータ/イテレータの類は「実行に於いて」部分的遅延評価で組み上げたデータと似たような動きをする。
それこそ、ここでのcreate_generatorは次のようなストリームと似たような動作をする。
(define create-generator
(stream-cons 0 (stream-map add1 create-generator)))
create_generatorは0から始めて1づつ増やした値を延々と返していく。
一方、Racketで書いたcreate-generatorは0から始めた無限長の整数列を返すが、定義上はcreate_generatorと同様に「計算規則を与えてる」だけだ。
ただし、ジェネレータ/イテレータの類と遅延評価の一番の違いは、前者は「破壊的変更」を伴って、一旦値を送出したら元に戻らない、って辺りだ。
一方、部分的遅延評価で得られたストリームは永続的にそこに存在する。上で書いたiterの簡単な実装でも見たけど、ストリームを破壊的変更しないとジェネレータ/イテレータと動作を完全に合わせる事が出来ない。

これはよく分からんが・・まあ、あんまり縁がなさそうな気がするから良いか
いや、これはむしろ「一番縁がある」だろう。
先行評価型言語に於ける、部分的遅延評価の一番の旨味は、今まで見てきた通り、遅延リスト(ストリーム)の存在だ。そこが一番美味しい。
1. でも見たけど、部分的遅延評価は、理論的にはラムダ式で形成するthunkによる実装だ。
しかし、一般には、上で見た通り、遅延評価させたい部分をlambdaで包む為、記述がメンド臭い上、関数自体は引数が先に評価されてしまう、と言う欠点がある。
Schemeのマクロ、delayはこれを解決する為にあって(※10)、理論的には、与えられたS式を単にlambdaでラップする。
(define-syntax delay
(syntax-rules ()
((_ e) (lambda () e))))
逆に関数forceは単にdelayで作られたthunkを実行するだけ、だ。
(define (force thunk)
(thunk))
そして遅延リスト(ストリーム)の基本的なコンストラクタであるマクロ、stream-consは次のように書ける。
(define-syntax stream-cons
(syntax-rules ()
((_ head tail) (cons head (delay tail)))))
そしてheadとtailの代わりに次のような関数2つを定義する。
(define stream-car car) ;; headの代わり
(define (stream-cdr lst) ;; tailの代わり
(force (cdr lst)))
Luaのコードに比べてシンプルなのは、Lispにはマクロがあるから、だ(※11)。
そしてこれだけ、で遅延リストを構成する基礎となる。例えば次のような関数
(define (stream-map f s)
(if (null? s)
s
(stream-cons (f (stream-car s))
(stream-map f (stream-cdr s)))))
を定義すると、前の例で見せた「無限長の」遅延リスト(ストリーム)を簡単に形成する事が出来る。
よって、先行評価な言語でラムダ式がある場合、もっともお世話になりそうな例は、この、部分的遅延評価による「遅延リスト」生成だと思われる。

コールバックもよく分からんが・・共通する特徴、コレが知りたかった。無引数関数でラップするってのはなるほど!そdelayed_operationんでその中に計算を入れておくと?で、必要な時にその関数を呼び出すと計算が行われると。
「コールバック」と言う単語自体は、「高階関数の引数となってる関数」の意味だ。
delayed_operationは関数callbackを取る一引数の高階関数で、callbackはdelayed_operationに対して文字通りコールバックだ。
ただし、この例は、事実上、上に挙げたdelayの定義と全く同じだ。
しかしながら、Luaも先行評価の言語だろうから、delayed_operationに与えた引数callbackは完全に「関数だけ」であることが求められる。delayは式でも構わない、と言うのとは違う。
それもこれも、Lispにはマクロがあるんで、引数を「まずは評価せずに」thunk内に簡単に閉じ込められるから、だ。一方、(Lispの意味で言う)マクロ無しの言語だとそういう器用な真似が出来ない。
と言うわけで、AIが「並べた」事柄は、並列じゃなく、あるものは言語の下のレイヤー、あるものは基礎的な話、あるものは応用、とちとバラバラのレベルに付いて語ってる。
いずれにせよ、基礎から「遅延評価」をまとめ直すには、良いトピックだったかもしんない。
※1: ただし、Lispで学べない概念は一般的には恐らく、静的型付け、トレイト、ファンクタ、モナド辺りしかないんじゃないか。
※2: SICPの問題1.6と言うのはこれに付いての問題だ。
※3: CPUなんかのハードウェアに密接した考え方をする層は「CPUには条件分岐を司るジャンプ機能があって・・・」と言いたがるだろうが、ハッキリ言って全く関係ない。繰り返すが、高級言語は「ハードウェアがどういう仕様だろうが」関係なく独立して存在する。高級言語の評価規則は必ずしもハードウェアと密接に関係しているわけではない。
しかしながら、ハードウェアの動作とかけ離れたような高級言語の実装だとパフォーマンスが悪くなる、ってのは事実だ。ただし、「それ」と理論面は全く関係ない。
※4: ほぼ唯一の著名な純粋関数型言語。副作用が一切存在しない。その代わりにモナド、と言われる理解し難い概念があり、尖ったプログラマ達を混乱に叩き落とした。
なお、モナドとはイスラエルの諜報機関の事ではない。
※5: いいことづくめに見えるが、引数が、展開によってはメモリを食いつぶすような巨大なデータに成長する事がある。Haskellでは結果、「任意で」先行評価に切り替えるような「例外的動作」を許容する。
また、遅延評価をベースにした言語だと、末尾再帰と極めて相性が悪い。評価規則が違う為、無限ループに陥る、と言う事が良く生じる(結果、いつ末尾再帰が使えるのか、一見して分かりづらい)。
遅延評価だと「非効率的に見える」フツーの再帰の方が、結果相性が良く、また、非効率にはならない。
※6: Haskellを持ち出すまでもなく、実はRacketでも試せる。
Racketに付属してるLazy Racketと言うのが遅延評価を基礎としたRacketの亜種だ。一種の実験実装だが、Haskellに比べても色々とラクに「遅延評価をベースとしたプログラミング言語」を試せるだろう。
なお、SICPの4.2と言うのが、Schemeで遅延評価を基礎としたSchemeの亜種を作ろう、と言うネタだ。
※7: 厳密ではないが、関数型言語のfoldがイテレータだとすればunfoldはジェネレータだ、と捉えても良い。
※8: 以前見たが、fold系関数の実装は3通り考えられ、ここでのfoldlの実装はいわゆるRacket/Schemeで扱われてるfold/foldlの実装ではなく、foldrと対称的なfoldlだ。
※9: ところが、フツーの先行評価のRacketだと、関数の構成要素を全部ストリーム関連に置き換えても上手く行かない。ここで書かれてる事は「関数の引数」自体が遅延評価される事が前提だから、だ。一方、先行評価環境では、ストリーム関連の関数に置き換えても関数定義自体が遅延評価であるわけじゃない。
事実、Schemeの遅延評価ライブラリであるSRFI-41には有限長のストリームを左から処理していくstream-foldは存在してもstream-foldrは存在しない。
代わりと言っては何だが、無限長のストリームを扱うstream-scanと言う関数が存在してて、無限長のストリームを返すようになっている。この定義は一種、foldrの改造版となっている。
単純には、
(define (stream-scan f acc strm)
(if (stream-empty? strm)
(stream acc)
(stream-cons acc
(stream-scan f (f acc (stream-first strm))
(stream-rest strm)))))
と言うのがその定義で、結果、アキュムレータ(acc)の変化の過程がそのまま無限長のストリームになって返される。
なお、Pythonのitertools.accumulateの定義は、理論的にはこのstream-scanと同じモノだ。
※10 そもそも「マクロ」が引数を最初に評価しない。
Lispのマクロは引数を評価せず、それを指定に従って並べ替えた「後」に評価する。
つまり、Lispのマクロは先行評価言語であるLispの内側に「突然現れた」遅延評価言語だ、と見ることが出来、Haskellユーザーが言う「マクロ不要論」は、Haskellのような遅延評価ベースだと、冒頭の例でも見た通り、事実上「構文」と「関数」の境界線が曖昧で、関数で先行評価言語で言う「構文」が簡単に組み立てられてしまうから、だ。
※11: 基本的に同様の方法論が、遅延評価を持たないANSI Common Lispでの実装法としてLand of Lispでも紹介されていた。
 | Land of Lisp Land of Lisp ノーブランド品 |
※12: 実際、Pythonには厳密には遅延評価は無い、が、一番お世話になるのは、同様な遅延リスト(Pythonではイテラブル)によるデータ生成だ。










