
星田さんの記事に関するコメント。
今回はちと長めに抜粋してみようか。
すんなりと1つ片付いたので例の場合分け成績関数の改善をちょっと考えてみることにした。Pythonの時に辞書、Schemeだと連想リストで・・ってのをCametanさんに教えてもらってたな!ということでリストのCDR部分にその後の手続きを入れておいて・・あ!

そうかEvalに流し込んで実行させたら・・・?結局全然行数が減らないなwと思ったんですが、連想リストのCDR部をEvalで実行させるとか出来たら面白いかも・・と挑戦してみました
が、駄目!

このenvironmentの部分が意味不明。引数不足でエラーが・・うーん・・サンプルを見ても「モジュールです」とかあるんだけどますます?

なんと言うかFormatみたいな感じで変数をぶっ込んで実行させるみたいなと言いましょうか
と言うのが流れ。
まず言っておくと、発想がいい。素晴らしいよね。
ただ、結論から言うと、このコードに関しては、caseを使った方が結果シンプルにはなるたぁ思うんだ。
しかしながら、なかなか技術的に重要な示唆、っつーか考察が提示されている。
よって、あくまで「テクニカルな観点で」見ていこうと思う。
まず「evalを使いたい局面である」と言う事。こういう要求が出てくるのは不思議じゃあない。
ただし、Land of Lispにも書いてあったと思うんだけど、それは危険なんだ。evalの直接使用は避けられるなら避けるべきだ(そして100%避けられる)。
ポール・グレアムも書いてたんだけど、evalを使いたいような局面に立ったら、それはマクロを使う場面だ、と言っている。
別にマクロを自作しなくてもいい。明らかにcaseはマクロなんで、ポール・グレアムの助言にそのまま従うなら、結果caseを使うべき、って話になる。
通常、evalは「環境」と言う引数を取る。ここで言う「環境」はインタプリタなんかのシステムで使ってる変数束縛やら、あるいはデフォルトで使える関数群なんかを指す。これらはフツー、Lispではオプショナル引数で与えられるもので、こっちで必ずしも指定しなくて構わないものだ。
;;; Racketでの例。;;; 別に「環境」を指定しなくて良い。> (eval '(+ 1 2))
3
>
;;; ANSI Common Lispでの例。;;; こちらも「環境」を指定しなくて良い。CL-USER> (eval '(+ 2 3))
5
CL-USER>
ただし、R7RSやGaucheの場合、evalでの環境引数はオプショナルじゃなくなっちまった。
1つの理由として上に挙げたように、「簡単にevalを使えるのは危険だから」だろう。簡単に危険を招き入れるのは得策じゃない。だから使うのを難しくした、ってのが1つの理由じゃなかろうか。そうすれば、自分で環境を呼び出すか、あるいは設定する手間がかかる。手間がかかれば使うのが億劫になる。従ってevalは使わない、みたいなね。
と言う事はevalを使わない代わりにどうすれば良いのか、と言うのが今回のネタだ。しかもマクロ自作を避けよう、ってのがトピックになる。
まずもう一回、星田さんが書いたオリジナルのコードを見てみよう。

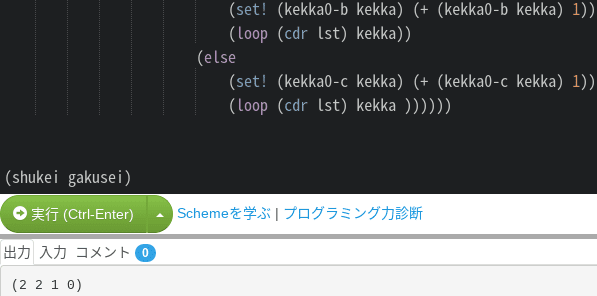
テーマは「連想リストを使い、evalを避け、条件分岐を代替するにはどうすれば良いか?」だ。要するにリファクタリングだな。
まずは条件分岐を連想リストに置き換える事、とする。これが大まかな方針なんだけど、ちとその前に考えなきゃならない事がある。「一体どこに連想リストを置くのか?」だ。ちなみに、これがcaseがよりbetterな手だ、と言う理由にもなる。
単純に条件分岐を連想リストに置き換えるならこれは極めてスマートな手だ。ところが提示された関数は「再帰関数」なんだよな。再帰関数内に連想リストを仕込むと、連想リストまで「再生成されちまって」効率が悪い。出来れば連想リストは再帰関数本体に含まれない方が良い。
もう1つ、オリジナルのコードでは考えておかなきゃいけない点がある。これは「破壊的変更」を前提としてる事だ。別にここでは「破壊的変更を選んだ」事は責めないんだけど、ちと考えて欲しい点が出てきてる。
それはここだ。
(let loop ((lst lst) (kekka kekka)) ...
lstはいい。問題はkekkaの方だ。この2つは目的とする作用が違う。
前者のlstの場合、cdrを取っていく事が目的でここにある。そして事実上、名前付きlet上でlstと言う変数を「再生成」してる、って言うのがポイントなんだよな。つまり、メモリ上で敢えて言うと、ここの部分で最初のlstは次のlstとメモリ上同じ位置にいないんだ。次のlstは「新しく作られている」。より正確に言うと、「lstのcdr部分をコピーしたモノが新しくlstと言う名前になってる」って事だよな(要するに、理論的には全く新しいメモリ領域にコピーされている)。
じゃあ後者は?もちろん同じロジックが適用される筈なんだけど、実は「破壊的変更をする」と言う事は「新しいメモリ領域にコピーする必要がない」と言う事なんだ。kekkaと言う変数はあるメモリ領域にあって、その中の「要素」を破壊的に変更する事を意図するなら、実は「別にここに無くても良い」って事になる。再生成する必要がない、からね。
つまり、破壊的変更前提なら、リファクタリングの第一弾は
(define (shukei lst)
(let ((kekka kekka)) ;; 破壊的変更目的なら kekka は名前付きlet内にいなくて良い
(let loop ((lst lst))
(if (null? lst)
(hyouzi_kekka)
(cond ((equal? "S" (test-seiseki (car lst)))
(set! (kekka0-s kekka) (+ (kekka0-s kekka) 1))
(loop (cdr lst)))
((equal? "A" (test-seiseki (car lst)))
(set! (kekka0-a kekka) (+ (kekka0-a kekka) 1))
(loop (cdr lst)))
((equal? "B" (test-seiseki (car lst)))
(set! (kekka0-b kekka) (+ (kekka0-b kekka) 1))
(loop (cdr lst)))
(else
(set! (kekka0-s kekka) (+ (kekka0-s kekka) 1))
(loop (cdr lst))))))))
とこれでいい。
あるいは、当初はkekkaを大域変数として考慮してたようにも見えるんで、これでもいいと思う。
(define kekka (make-kekka0 0 0 0 0)) ;; 大域変数としてここで置いたままでも良い(define (shukei lst)
(let loop ((lst lst))
(if (null? lst)
(hyouzi_kekka)
(cond ((equal? "S" (test-seiseki (car lst)))
(set! (kekka0-s kekka) (+ (kekka0-s kekka) 1))
(loop (cdr lst)))
((equal? "A" (test-seiseki (car lst)))
(set! (kekka0-a kekka) (+ (kekka0-a kekka) 1))
(loop (cdr lst)))
((equal? "B" (test-seiseki (car lst)))
(set! (kekka0-b kekka) (+ (kekka0-b kekka) 1))
(loop (cdr lst)))
(else
(set! (kekka0-s kekka) (+ (kekka0-s kekka) 1))
(loop (cdr lst))))))))
これは関数型言語として望ましいスタイルじゃあない。ただし、「破壊的変更」と言うやり方を考えるなら真っ当なやり方、ではある。
いずれにせよ、普段はLisp使いは「メモリがどうなってんだか」考えなくていいんだけど。っつーのも「いくら新しいメモリ領域を使ってデータをコピー」しようが、ガベージコレクタが駆け回って「未使用になったメモリ領域」を開放してくれるしね。全然何も考えなくて良い(だからLisp programmers know costs of nothingって言われる・笑*1)。
ただし、「破壊的変更」し、なおかつ「そのデータを新しくコピーする」ってのはさすがに無駄だ。だって「コピーを新しく作らないように」破壊的変更するのに、それでもコピーしちゃう、ってのは無駄でしょ?
要は、「破壊的変更」する際にはどうしても「メモリがどうなのか」ある程度考えなきゃいけなくなっちゃうわけ。
さて、次に条件分岐代わりの連想リスト使用を考えよう。
ポイントは「連想リストを使うなら再帰に巻き込まれないようにする」だ。従って、名前付きletの外側に置く、ってのが必要になるだろう。
つまり、形式的には
(define (shukei lst)
(let* ((kekka kekka)) (rensou '(("S" ....
か、あるいはやっぱりshukeiの外部に置いて
(define rensou '(("S" ...
とするか、どっちか、と言う事になる。
そして「実行させる」前提ならば、クオートされてる「部分」をevalさせたい、って要求がここで出てくるわけだな。
連想リストの「値」を関数にしたい、しかし、クオートすると単なるデータになってしまう・・・この問題は最近何度か出てこなかったか?
そう、単なるクオートを使う、ってのがそもそもの問題の原因なんだ。一部分を「評価したい」場合はどうするのか?またもや準クオート(quasiquote:`)とコンマ(,)の出番なんだ。何も連想リストはクオートでなければ作れない、って事はない。むしろ、クオートが使える局面では準クオートとコンマは自由に使える、って事を思い出そう。
ここでは星田さんが想定してたような「連想リストを関数の外部に置く」形式で考える。
上の議論に従うと、単純には連想リストをこう設計すれば良い。
(define rensou `(("S" . ,(set! (kekka0-s kekka) (+ (kekka0-s kekka) 1)))
("A" . ,(set! (kekka0-a kekka) (+ (kekka0-a kekka) 1)))
("B" . ,(set! (kekka0-b kekka) (+ (kekka0-b kekka) 1)))
("C" . ,(set! (kekka0-c kekka) (+ (kekka0-c kekka) 1)))))
そして関数本体をこうする。
(define (shukei lst)
(let loop ((lst lst))
(if (null? lst)
(hyouzi_kekka)
(begin (cdr (assoc (test-seiseki (car lst)) rensou))
(loop (cdr lst)))))))
ところがこれでも上手く行かない、って事に気づくだろう。
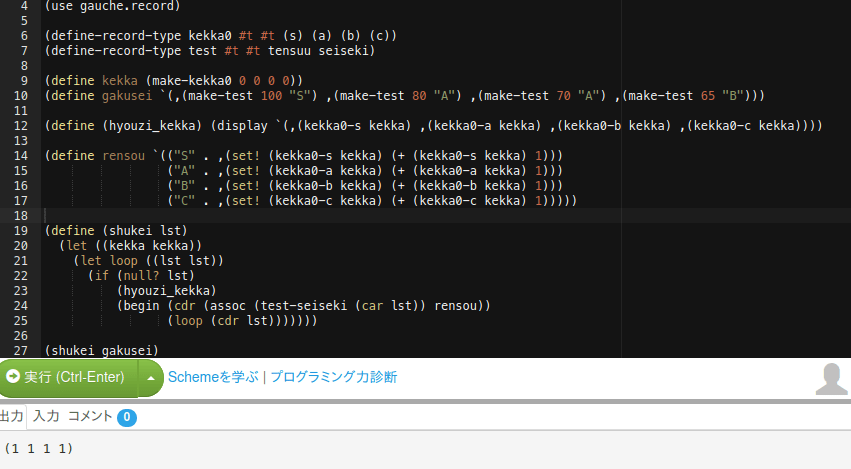
結果が(1 1 1 1)となってしまう。何でだろ?
そう、準クオートとコンマにより連想リストは設定された時点で「それぞれ一回ずつ」実行されてしまう。そして「実行した」以上結果だけ残してあとは消えてしまうんだ。
これはマズい。予想と違う。
必要なのは「連想リストを設計した時点では評価を止めてて、関数本体内で評価を"選ぶ"形式にしたい」って事だ。そんな事出来るんだろうか?
出来るんだよな。それが「ラムダ式」だ。
連想リストに設定する「値」を無引数ラムダ式で「包む」。そうすれば再実行可能な「関数」と言うデータとして値を設定出来る。あとは関数本体内で「評価」しちまえば目的を達する事が出来る。
つまり、連想リスト側を、
(define rensou `(("S" . ,(lambda ()
(set! (kekka0-s kekka) (+ (kekka0-s kekka) 1))))
("A" . ,(lambda ()
(set! (kekka0-a kekka) (+ (kekka0-a kekka) 1))))
("B" . ,(lambda ()
(set! (kekka0-b kekka) (+ (kekka0-b kekka) 1))))
("C" . ,(lambda ()(set! (kekka0-c kekka) (+ (kekka0-c kekka) 1))))))
と設定しておく。そして本体側を
(define (shukei lst)
(let loop ((lst lst))
(if (null? lst)
(hyouzi_kekka)
;;; 一見 ((cdr assoc ... とカッコの数が1つ多く見えるのは、ここで返ってくる
;;; 「値」が無引数ラムダ式で、それを「実行」するためだ。
(begin ((cdr (assoc (test-seiseki (car lst)) rensou)))
(loop (cdr lst)))))))
とする。そうすれば意図通りにプログラムが動くだろう。
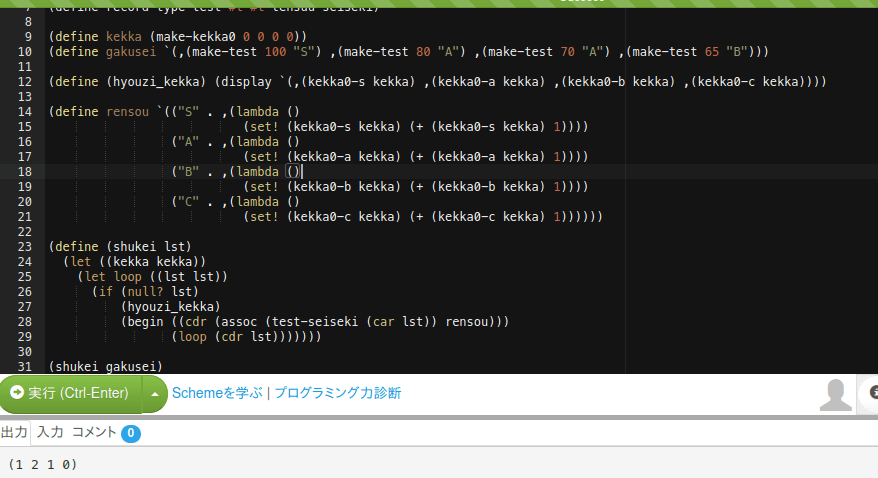
繰り返すけど、このプログラムは基本的にはcaseを使うべきだと思う。
ただし、星田さんの発想が非常に良く、また、普遍的なthunk、要するに無引数ラムダ式を「使う」問題としては典型的な良問になってるんだ。
評価を「止め」て、必要な時に「実行する」ってのを考えるには非常に良い着眼点になってると思う。
もう一度ポール・グレアムの言葉を思い出そう。
ハッシュテーブルにクロージャを詰め込む とか、弱い言語だったらオブジェクト指向テクニックが必要だっただろうと 思えることはたくさんやってきた
ハッシュテーブルじゃなくて連想リストだけど、星田さんが直感的に考えた事はこの「ハッシュテーブルにクロージャを詰め込む」場面だ。
よって、ポール・グレアムが「たくさんやってきた」トコに星田さんは近づいている。
>2022/07/18〜
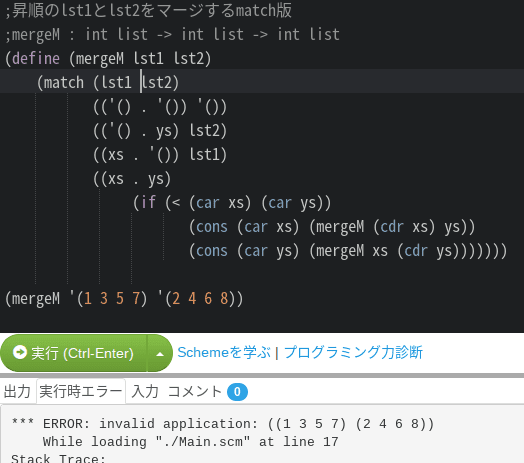
- matchの後の分解する対象、Ocamlみたいに一気に複数を取れるのか?
- matchの後ってifは許されるのか、書き方ってOcaml的で良いのか?
- matchの後、再構成する時に束縛したxとかyに混ぜてlstをそのまま使ってたりするように見受けられるけどルールがあるのか・・もしかしてmatchの後のリストに入ってる場合は(上の例では)lst2は(y . ys)になり、それ以外で関数の引数になってるのはlstとするのか?
- 取れます。ただ、ちょっとテクが必要。
- 許されます。良いです。一般的に条件節の後ろの実行文は何を入れてもO.K.。じゃないと条件文の入れ子が出来ない。
- パターン記述の部分の変数は完全にコンテクストから切り離されてて、「パターン記述」の為に使われてるだけ、なんでそれの実行部分への使い回しはスコープ的にもやってO.K.です。元と混ぜて全然O.K。
ちなみに、正解はこうだ。
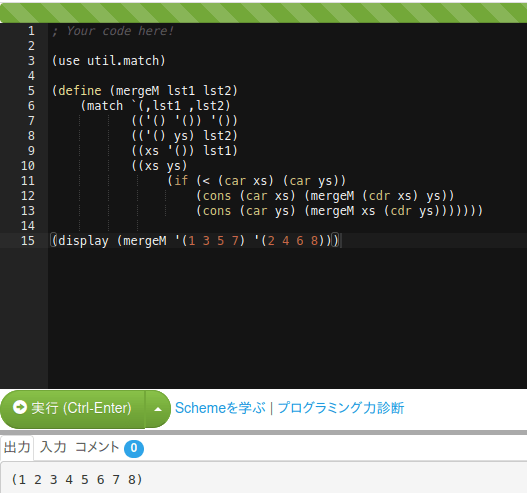
まず、matchの第一引数に「どういうデータが受け渡されるのか」教えないとなんない。従って、(list lst1 lst2)と言うデータを与えるか、`(,lst1 ,lst2)を与えるかしないとならない。
次。ちょっとパターン記法がGaucheの場合メンドイんだけど、.(ドット)を用いる、例えば(x . xs)とか言う場合、あくまで「リストを分解して先頭とそれ以外」と言う意味になる。今回のように「2要素のリスト」の場合、ドットは要らない(何故なら2要素しか存在せん、と確定してるから)。また、要素を空リストと判別させる為、matchの第一引数で要素を全部評価しなきゃならないわけ。
※1: Lispプログラマはコストの何たるかを知らない、の意。
ただし、これはANSI Common Lispのプログラマには当てはまらない。ANSI Common Lispは最適化の為のツールや関数等を山ほど持ってるし、真のANSI Common Lispハッカーはアセンブリレベルでの記述も良く知っている。じゃないと効率的な最適化が不可能だから、だ。
一般のLispプログラマに対しては当てはまる、でもCLerには当てはまらない、と言えるだろう。











