
星田さんの記事に対するコメント。
> 2022/10/15

メトロ検索プログラムの大詰め、ダイクストラメイン部分。実はこれ、昨日の時点で一応出来てたんですよね。ところが実行してみると・・タイムアウト。もしかして検索データが多いので時間がかかってハネられているのか?いや、書き方の問題かなぁ・・と。
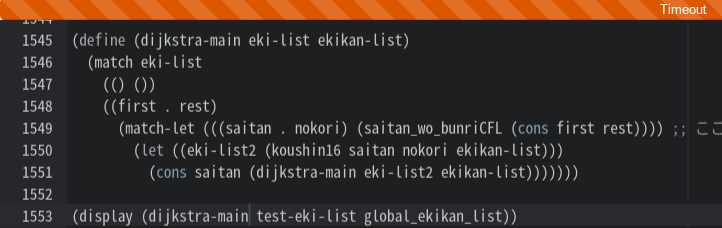
しかしCametanさんに書いてもらったのも同様にタイムアウト。気になるのは先の章で検索効率を高めるという部分(2分木探索)が用意されてるんですよね!もしかしてそれを取り入れたらちゃんと動くのかも知れない!?ちょっと楽しみにしておこう。
ん〜〜、どういうわけだ?ってぇんでチェックしようにも、そもそもPaizaでアカウント持ってなかったんで、今まで書いてきたコードを記録してない。
しょーがないんで、Paizaのアカウント作ってみたんだけど、やっぱオンラインってやりづらいんだよなぁ(苦笑)。
ってなわけで、この辺りまでの「正解」のコードがどうなるのか、OCamlからローカルのGaucheへと翻訳してたんだが・・・・・・。
結論からいうと「結構時間がかかります」(笑)。だからPaizaがどのくらいリソースを1ユーザーに当ててるのかは知らないけど、ひょっとしたらクリティカルだ、って判断されるかも。
いずれにせよ、ファイル量が結構多いんで、ここにアップロードしてる。Paizaで書いたコードと比較してみて欲しい・・・・・・。
とは言ってもこれを作るのが結構大変だった。
ぶっちゃけた話、過去、軽くGaucheに触った事はあるけど、Gaucheで何かした事がない。圧倒的にRacketを使ってて、次点がCHICKEN Schemeだ、ってのが正直なトコだ。
よって、これだけGaucheに付き合った事はないし、Gauche独特のクセ、っつーか問題点にも気づかんかった。
個人的な意見では、やっぱRacketの方がGaucheより遥かに扱いやすい。この辺は個人的な好みもあるんだろうけどね。
今回、「コードが正しいか否か」調べる為、「プログラミングの基礎」ばりにGaucheのユニットテストを使ってたんだけど、これが一筋縄じゃイカんかったんだ。その問題解消にやたら時間がかかってしまったわけ。
星田さんも、今後Gaucheを使い続ける可能性があるんで(ドキュメント自体は分かりやすいしね)、ちとここでGaucheでのユニットテストとその問題点を記述しておこう。
まず、Gaucheでユニットテストを行う際は、(use gauche.test)でユニットテスト用のモジュールをロードする。
ユニットテストをそのまま行うのはGaucheでも問題がない。書式は以下の通りだ。
(test* "テスト名" (引数を与えた関数) 望む結果)
マニュアルには色々書いてるが、「プログラミングの基礎」をやる程度なら上の式一本槍でO.K.だ。

ただし、今回厄介だったのが、プログラミングの基礎で扱ってるメトロネットワークの問題の解が、圧倒的に構造体のリストになる辺りだ。
つまり、Schemeに於いて、レコード型のインスタンスの等価性をどうやって判断するんだ、という問題が出てくる。
これは、ぶっちゃけ、Gaucheの問題と言うより、Schemeの仕様書のポカと言って良い。
ちと説明しよう。
まず、古くから構造体を備えてるANSI Common Lispを見てみる。
例えばANSI Common Lispで次のような構造体を定義してみる。

単に2つのスロットを持っただけ、の構造体だ。名前をfooにしてる。
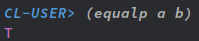
さて、この構造体を使ってインスタンスa、b、の二個を作ってみよう。

両者ともスロットに全く同じ値を与えてる。つまり「中身は全く同じ」筈なんだ。
ところが、equalで判定してもこの両者は「同じではない」と言う判定を喰らってしまう。

あれ?って結果だろう。
これじゃ困るのが分かる?
ANSI Common Lispではユニットテストを行う機能はビルトインではないが、「プログラミングの基礎」の「テスト」のようなモノをやった際、構造体で作ったインスタンスが「同じ値」を持ってても「同じ」だと判定されなければ、そもそもユニットテストの方法論が破綻してしまう。
この原因は、「生成された構造体」が別々のアドレスにいるから起こる事で、ハッキリ言っちゃえばインスタンスの中身を比較してるワケじゃない、って辺りだ。
しかしながら、さすがANSI Common Lisp、キチンと抜け道がある。
と言うか、Schemeだと等価及び等値を調べる述語はeq?、 eqv?、 equal?の3つがあるんで、Lisp全般にその3つしか基本的に無い、って思い込み易いが、実はANSI Common Lispには4つ目がある。それがequalpだ。
さすがANSI Common Lisp、構造体を仕様に含みながら想定される等価判定述語を欠かしてる、と言うようなポカはやってない。しかしながらSchemeではレコード型が仕様に含まれた割にはこれが全く解決されてないんだ。
実は同種の問題をRacketも抱えてるっちゃあ抱えている。

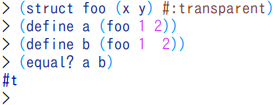
この通り、同じ構造体でスロットの中身を同じにしても、equal?は非情に#fを返す。
Racketでの解決策は、単純に構造体を定義する際に#:transparentを与える事だ。
そうすれば、Schemeのレコード型の等価性問題に巻き込まれるこたぁない。
要するに、Racketで構造体を使う際には常に#:transparentを付けとくのが安全策、と言えば安全策だ。そうすれば、想定外の挙動に悩まされなくて済むだろう。
CHICKEN Schemeの場合、ANSI Common Lispのようなequal=?と言う述語が導入されてて、これで構造体のインスタンスの同値比較ができる。

と言う事は、Gaucheにもこういう抜け道がどっかあるんじゃねぇの?って思うだろ?
結論から言うと全くなかったんだ。Gaucheではレコード型の同値性判定用の述語がデフォルトでは提供されていない。
まぁ、少なくとも、調べた範囲では発見出来なかった・・・・・・ぶっちゃけ、Gaucheのマニュアルは読みやすいんだけど、特定の項目を探したい、なんて場合、検索性能は良くない(※1)。結局Google経由で検索するのが一番確実ではあるんだが、それでも結果、見つからなかったんだ。
Gaucheでは等価述語自体も実はANSI Common Lispスタイルのオブジェクト指向で書かれている。つまり、総称関数的に設計されていて、特定の「等価」を知りたい場合、define-methodでその「比較の仕組み」を追加できる模様だ。

つまりマニュアルに拠ると、equal?で比較して、もし望ましい結果が得られなかった場合、object-equal?と言うメソッドを呼び出して、比較を続けるらしい。

上の例で言うと、だ。

なんだけど、

と言う事だ。ぶっちゃけメンド臭い・・・・・・。
つまり、Gaucheに於いては一般的な汎用のレコード型の比較関数は存在してなく、自分で定義した型(つまり特定のレコード型)毎に総称関数の一部として比較関数(と言うか、ぶっちゃけメソッド)を設計して登録せんとアカン、と言うわけだ。
そしてOOP嫌いでOOPから関数型言語に逃げてきたのに(笑)、GaucheだとOOPを使わなアカンらしい(笑)。
わはははは(笑)。
さて、Racketではモジュールの作り方の概要を学んだ。
そして自作モジュールは今作ってるプログラムからの相対パスを文字列で引数としてrequireに与える事で読み込める。
ヒッジョーに明解で簡便な方法をRacketは提供している。
じゃあ、Gaucheではどうなってるんだろう?
アップローダであげたファイルを見て欲しいんだけど、結構Gaucheでのモジュール作成はメンド臭い。
マニュアルによると次のような書式になっている。

Racketに比べると「かなり長い」。
例えば上で書いたようなa及びbと言う構造体のインスタンス提供するモジュールを書くとすれば、Gaucheでは次のように書く。

こうやってファイルを定義しておけば、例えばファイルをfoo.scmと名付けておけば、理論的には(use foo)としたファイルでaとbは使い放題となる。
ところで、上のファイルだと<foo>と言うレコード型を定義している。じゃあ、(use foo)した側のファイルでレコード型<foo>を使った新しい変数cを定義したい場合はどうするのか?
単純には、レコード型の定義<foo>もエクスポートすれば良いように思える。次の通りに。

ところがこれじゃ上手く行かない。

ご覧の通り、make-<foo>が何か知らない、と言われて怒られる。
Racketのprovideの機能とは対象的だ。
つまり、こういうfoo.rktの定義に対して、

(require <foo>)した側では、構造体<foo>の全機能を自由に使う事が出来る。

一方、どういう事かと言うと、Gaucheの場合、構造体名のシンボルだけをexportするんじゃダメで、コンストラクタ、述語、アクセサ、ミューテータ等を全部記述してexportせなアカンのだ。ウゲ。

これはかなりメンド臭い。

もう一つ問題がある。
Racketの場合、カレントディレクトリ(作業フォルダ)からの相対パスで自由にモジュールを呼び出せる。
一方、Gaucheはそういう設計になっていなくて、基本、2つのフォルダからしかロードが出来ない設計になってるんだ(※2)。
上の画像の(add-load-path ".")と言うのは、ライブラリロード用のパスを2つ含んだ*load-path*変数にカレントディレクトリ(現時点での作業フォルダ)を追加するオマジナイだ。そしてこれは恒久的に追加してるわけではなく、再びGaucheを立ち上げると消えてしまう。そしてまた追加せんとイカン。
どうもGaucheは完全な「コンパイラ指向の処理系」みたいで、他のScheme処理系みたいに「気軽にスクリプトを書く」事には向いてない気がする。分からんけどな。
どっちにせよ、Paizaでこの辺どうなってるのか、ってのもイマイチ分からん、ってのが本当のトコだ。
ちょうど1年ほど前の話なんですけど・・Cametanさん、本当にお世話かけちゃいまして・・ありがとうございます m(_ _)m
あ〜、もうそれくらい経つのかぁ。
っつーか、苫米地さん知ってたのが大きいとは思うんだけど、ぶっちゃけ、こんなにスンナリと「Lispの世界に飛び込んでくる人」ってあんまいないんですよ(笑)。明らかに「向いてた」って事だよな(笑)。
ぶっちゃけ、プログラミングやりたい、って始めた人で脱落する人多数だとは思うんだけど、「情報を知らない」事で、関数型言語の存在を知らないで損してる人が多いのは事実だと思う。脱落した中にも「関数型言語」の方が合う人は絶対いる筈なんで。
必ずしも、「メジャーなプログラミング言語」が全員に合うわけねぇんだよな。世の中AKB48に夢中なヤツばっか、とは限らないわけでしょ?
まぁ、マイナーな言語が合った、って事が喜ばしい事なのかどうなのか、ってのは議論の余地はあるけれども(笑)。
いずれにせよ、前にも言ったけど、今後PythonやRuby、みたいなプログラミング言語に行くとか戻る、とかなった時でも、プログラムを書く際での視点が変わるとは思う。それがエリック・レイモンドが言ってた「悟り」で、多分Lisp知らない人じゃ得られない経験を今してるたぁ思いますよ。
アレなんだよな、例の女の子に星田さんが「Lispやってます」と言った時のその子の反応が知りたい(笑)。どんな反応になるんだか楽しみにしてます(笑)。
> 2022/10/16
この流れだともしかしたら自動二分木作成関数を作ることになるかも知れないなぁ。
うん、赤黒木だから明らかに「平衡二分探索木」ですね。自動で色々とやるヤツだ。
赤黒木はAVL木よりも検索効率が若干悪いんだけど、操作はAVLよりは速い、と。つまり検索効率の若干の悪さ(AVL木に比べると平衡性が劣る)と引き換えに木の組み換え作業時間を減らした平衡二分探索木です。
なお、実のこと言うと、racoで得られるパッケージにdata-red-blackと言うモジュールがあります。
だからゲームで応用したい、ってぇのならいいタイミングかも。パッケージを使うか使わないかはさておき、「仕組みを良く知ってる」方が気楽に使えるだろうしね。
> 2022/10/17
今Racketで作ってるゲームらしきものだけど、なんか二分木探索のイメージが浮かばなかった。ページ構造体のリストで管理するするつもりなんだけど、目的のページ番号とかが明らかなので「配列」っぽいイメージをしてたと判明した。もしも構造体の要素にページデータを持たせて移動ページそを探そうと思ったら、やっぱり二分木探索を取り入れないといけないか・・
うん、Lisp的な「開発」で言うと、最初は連想リストで行けるトコまで行くべきだと思う。
一回それでやってみて、パフォーマンスで問題が生じたら、データ形式を二分木で置き換える、って程度でエエんちゃうかいな。
二分木に比べると連想リストは確かに重いんだけど、一方「気楽に使える」ってのはやっぱメリットなのよ。
LOLでも書いてたと思うんだけど、Lispでの開発は最初はリストで行けるトコまで行く。一旦モックアップを完成させておいて、データ形式はあとですげ替える、って程度でいいと思います。
んでそういう修正を中心として考えると・・・・・・git(※3)なんかのバージョン管理システム導入してもいいと思うんだよな。
まぁ、Web上にたくさん入門サイトもあるし(例えばこんなの)、guiのガワなんかも探せばあるんで(※4)、導入自体は苦もなく行えると思います。
gitを使うコツはmasterと呼ばれる本流では開発しない事。とにかく無節操な程にbranch(傍流)を作る。上手く行ったヤツだけmasterに統合する。実験したい際はbranchからbranchを切る。失敗したら忘れる、成功したら分岐元と合流する・・・とまぁ、本流を避けつつ「自由に色々やってみて」上手く行ったヤツだけ本流と合流させる、ってトコかな(※5)。

コンストラクタの話が出ていたのでリンク先の連想リスト関係を見る。うーん、ある要素を一つ入れ替えて新しい連想リストとして返すという関数は無い模様。
いや、ある。
alist-consを良く見てみよう。こう書いてある。
-> alist
これは連想リストを返す、と言う意味。
つまり、alist-consは常に新しい連想リストを返す、って事だ(※6)。

上の実行結果を見れば分かると思うけど、大域変数*alist*は破壊的変更をされない。
と言う事は、むしろ
しかし破壊的変更をしないとすれば、常に環境変数に*equip*を持ちあるかないといけない(ショップでもバトルでもマスターでも使うので)ということだよな。
と言うのは正解だ。
と言うか、そっちの方が関数型プログラミングらしい。
川合史朗さんも言ってるけど、「何でも引数にしてしまう」のはむしろ望ましい、って気楽に考えた方がいいです。
今ならmatch-letも使えるんで、分解もお手の物だしね。
いや、そうなんですよ!入力を促す部分って絶対にあった方が良いですよねぇ!しかもこんなに短いコードで書けるのか・・。
全てがそうじゃないんだけど、意外とユーティリティの類ってのは「短いコードで書かれた」ブツの比率が多いんじゃないかな・・・。mapもfoldもコード量自体は決して多くないでしょ?汎用的に使える、って事はむしろ「コードが単純」って事の方が多いと思う・・・Pythonのライブラリ関数で「こんな実装です」って紹介してるのも決して複雑じゃないしね。
いや、むしろ、「何かに特化したプログラム」の方が逆にコード的には肥大化していってんじゃないの(笑)?何故ならエラーチェックや何らかが増えるからね。
「こうして欲しくない」って言う「拒否」が増える程コード量が増えていくような気がします。
※1: 「中身はない」んだけど、一方、ドキュメントの内容検索はRacketの勝ちである。Racketの問題点は「検索はいい」んだけど、それでたどり着いたトコには「ロクな説明がない」と言う辺りだ。
ちなみに、Gaucheの名誉の為に言っておくと、ドキュメントの検索性能の悪さで言うとどのScheme処理系も似たようなモンだ。別にGaucheだけ、の話ではない。そしてまるで、「せっかくマニュアルを書いたんだから全部読んで欲しい」と思ってるが如きだ。
一方、ユーザーから言わせれば「忙しいんだからピンポイントで知りたい情報だけ欲しいんだよ!」ってカンジだろう。結果、マニュアル製作者とユーザーの間には感覚の隔たりが生じる。
※2: この辺の設計方針に付いて川合史朗さん自らが色々と説明している。
ただ、これで言えるのは、Gaucheの設計方針は、Perl/Python/Ruby及び、Racketのような「書き捨てのスクリプトを作る言語」ではなく、むしろC言語等の「本格的なアプリケーション作成用コンパイラ」にしたい、と言う本音が見て取れる気がする。
言い換えると、Gaucheは実は本格的で敷居の高い、「気楽に使う事を躊躇う」Lisp処理系だ、と言う事でもある。
※3: 今、あまりにもgithubが有名だが、git ≠ githubだ。
と言うか、githubはあくまで、gitを利用したWebホスティングサービスなだけ、でgitそのものである、とかではない。
つまり、gitを使ってるからと言って、何もweb上にソースコードを晒す義務はない。
※4: 例えばWindowsだとToitorseGit(トータスギット)なんかが有名。Linux用では、と言うか、本当はgit-guiと言う付属GUIが付いてくる。
※5: ちなみに、入門書籍として一番いい、と思われるのは、オーム社から上梓されている「入門git」だと思う。原書は例によって洋書だ。図書館で問い合わせてみればいい。
※6: 二分木にこだわらないのなら、当然ハッシュテーブルを使って良い。
なお、ここで見せたが、原理的にはハッシュテーブルは破壊的変更目的のデータ構造だが、一方、Racketの場合、何故かイミュータブルなハッシュテーブルのシステムがある。この辺がANSI Common Lispのハッシュテーブルと大きく違う辺りで、alist-consのようにhash-setは常に新しいハッシュテーブルを返す。

大域変数として置いて、破壊的変更しないハッシュテーブルに一体何の意味があるんだ、って思う向きもあるが、引数内に保持出来て、ローカルでキー/値の追加・削除が出来る、と言う意味では「破壊変更しないハッシュテーブル」には関数型言語用ツールとしての価値がある。
問題は、ガベージコレクタのコストがどれくらいかかるか、なんだが、前にも書いた通り、コードをコンパイル出来るのなら、最適化が施される可能性はいつでもある。











