
さて、星田さんがいよいよ高階関数に突入だ。
これは長い間「Lispならでは」のテクニックだったんだけど、今ではPythonでも使えるテクニックだ。
「Pythonでも出来る」のなら当然ここで学んだ事はPythonで応用出来るし、Pythonでも「書こう」と思ったら色んな箇所で使える。
C言語みたいな言語は、「関数を作れるのに」手続き型言語、と見做される大きな理由は高階関数が使えないからだ、と言って良い。
言い換えると高階関数は関数型言語のキモなのだ。
そして最近のオブジェクト指向言語(C++/Java/C#)なんかではビルトインの高階関数がやっとこさ使えるようにはなったんだけど、相当不格好なのも「滅茶苦茶無理してる」からに他ならない。

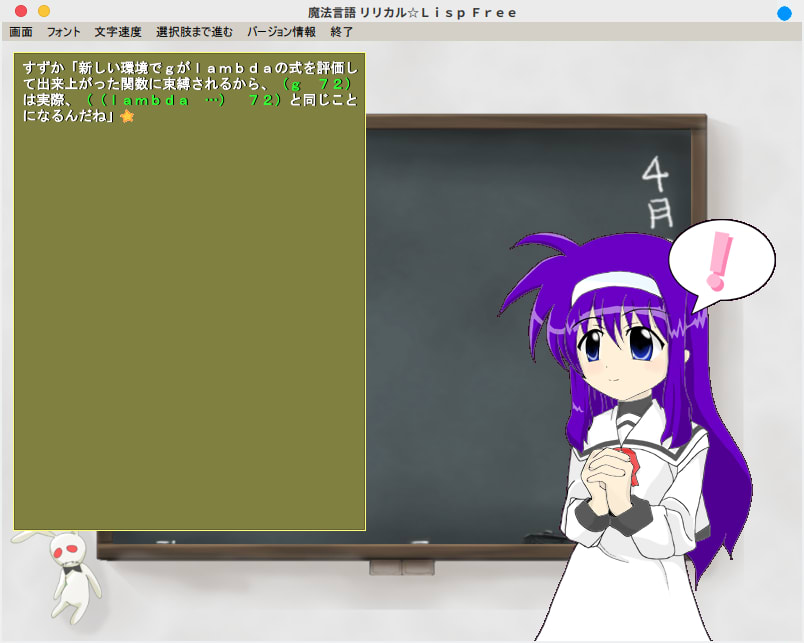
これ、今となったら分かるんですけど最初これ読んでる時には分かってなかったな・・関数を呼び出す関数って事だったんですね(しっかりしろ)
「関数を呼び出す関数」と言うより「関数に受け渡す関数」かな。
つまり、ここでも、c72と言う関数は事実上何もしていない。ただただ粛々と72と言う値を引数として与えられた関数gへと手渡してるだけ。
通常、高階関数は引数として与えられた関数を使って内部で計算する。ただし、継続受け渡し方式、つまりCPSと言う方式では「引数として与えられた関数は計算内部で計算には使わず」単に内部で計算した結果を受け渡す対象としてだけ使う。
言い換えると、CPSでは引数として与えられた関数をreturn代わりにして使う、と言う事。
この辺リリカル☆Lispでは触れられてないので、補足しておこうと思いました。
だから例のラムダ式に限らず、一引数の数字を取れる関数を引数として使う事が可能です。
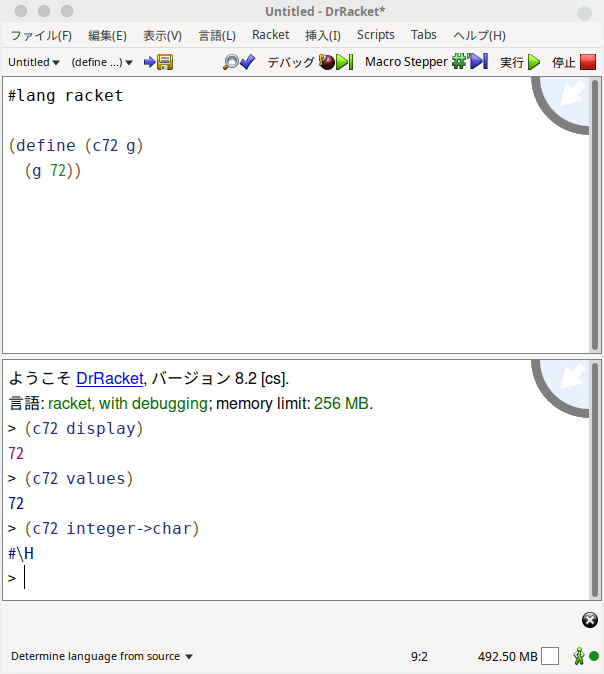
多分、結果を見ると「ちょっと変な気が」するでしょう。

ちなみにCARをCDRに変えたらどうなるんだ?という実験。エラーか~・・lのリストは破壊されてないんだから別にXに足されても良いような気がするけどなぁ?
いやいや。
carは「リストの要素」を返しますが、cdrはリスト(と言うデータ構造)を返します。
つまり、エラーの原因は「+と言う関数は数しか引数として取れないから」です。そしてScheme/RacketはPythonみたいにリスト同士を+では結合出来ません。
いずれにせよ、実験は良い事です。

うわ・・なんだコレは・・と思ったけど、今から考えたら「+」や「*」もシンボル?で使えるのか~・・そして関数として使うとこれをちゃんと理解してたらなぁ・・
と言う事はまたもや、このブログで何度も取り上げてるPythonのfunctools.reduceは「こうやって書かれてる」と言った原理的なコード、だと言うこと。
# Python での reduce の実装例def reduce(g, n, l):
return reducei(g, l, n)def reducei(g, l, x):
while True:
if l == []:
return x
x = g(x, l[0])
l = l[1:]
従って、ANSI Common Lispなら、

Scheme/Racketなら、

Pythonなら

となります。

ああ、Mapってそういう意味だったのか!それでPythonのリスト操作の時に良く見かけたんだな・・
そういう事です。
少なくともリスト内包表記が取り入れられるまで、このブログでも何度か指摘してますが、PythonではLispの高階関数の影響が大きかったのです。
ちなみに、上の実行例をPythonのリスト内包表記で書くと、
>>> [i == [] for i in ["a", [], "b"]]
[False, True, False]
>>>
となる。
Pythonでは、mapとリスト内包表記の対応を考えてみるのも良い練習です。


ふんふん、まあ読んでる時には分かってる気になってるんだけどね。これから何度も書かないと使えるようにはならんやろな
そしてPythonでは練習としてリスト内包表記でやってみる。
>>> [n * n for n in [3, 5, 9]]
[9, 25, 81]
>>> [x[0] + x[1] for x in zip([1, 3, 5], [2, 4, 6])]
[3, 7, 11]
>>>
んで、二例目だけど、Pythonのリスト内包表記はmapとは違って複数のリストを平行して走査出来ない。zipを忘れるととんでもない結果とかになるんで、気をつけましょう。
# ダメな例>>> [x + y for x in [1, 3, 5] for y in [2, 4, 6]]
[3, 5, 7, 5, 7, 9, 7, 9, 11]
>>>
# zipを使わず二つのリストから直接に要素を取り出すと「全部の組み合わせ」を試そうとする。使いどころに気をつけよう。
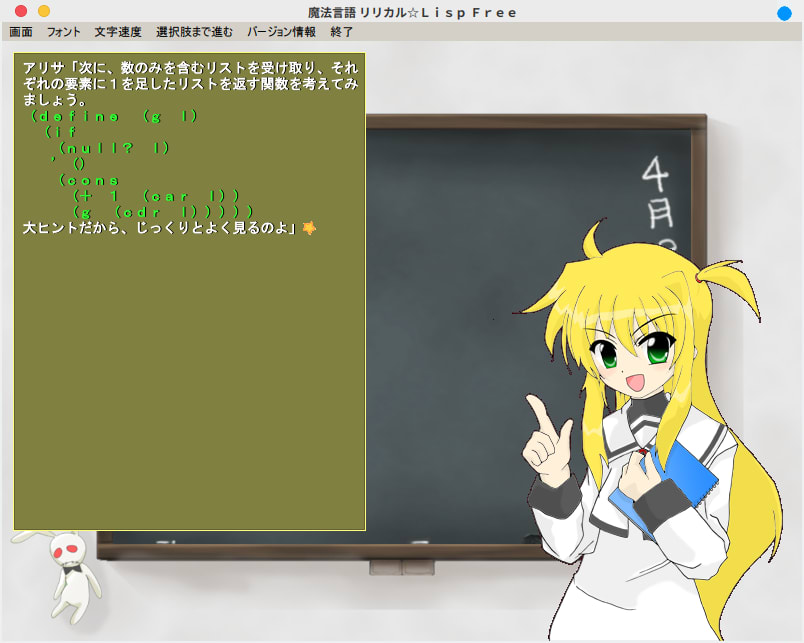


そして練習問題・・今となっては分かりそうなんだけども・・そもそも問題の意味がよく分からなくてお手上げ、ついにネットで「リリカルLISP 11話 解答」とかって検索してしまった・・そして11話で詰まってる人が作者からアドバイスをもらってる書き込みを発見、ああ・・カンニングしてしまいました。そもそも問題の意味を全然理解できてなかったのでどうしようもなかった・・
いや、全然(笑)。
この辺もドラゴン桜方式でエエんちゃうかな。
数学と同じで。
ちょっと考えて取っ掛かりが掴めなかったら解答見て暗記しちゃう。

これ、多分和田秀樹が言い出したやり方なんだけど。
ウンウン唸って考えるのはいいんだけど、ウンウン唸って考え続けてもダメな時はダメなんだよ(笑)。
だから暫く考えて取っ掛かりが見つからん時は諦めて解法暗記した方がいいのね。
んで、また暫くしてからトライした方が結果道筋を覚えやすいんだ。
言い訳ですけど、Paizaの問題みたいに「こういう引数を入れたらこういう結果が出る関数」とか実際の出力例が示されていれば・・。
いや、言い訳ちゃうんじゃないかな。
ただし、高階関数ってのは関数引数とデータによっては(上のreduceのように)「挙動が変わる」のがままあるんで出力例をあげるのが難しいんだよな(笑)。
ユニットテストは結果有効ではあるけど「完璧では」ないんだ。
なお、このブログでも高階関数の事は以前書いたわけだけど、このmapってのは高階関数の傑作で、高階関数の練習問題としては良く使われます。
Scheme/Racketだと次のように書く。
(define (map1 func lst)
(if (null? lst)
'()
(cons (func (car lst))
(map1 func (cdr lst)))))
Pythonだとこう。
def map1(func, lst):
return [] if lst == [] else [func(lst[0])] + map1(func, lst[1:])
当然両者とも末尾再帰にして、Scheme/Racketなら例えば名前付きletを使って
(define (map1 func lst)
(let map1i ((lst (reverse lst)) (acc '()))
(if (null? lst)
acc
(map1i (cdr lst) (cons (func (car lst)) acc)))))
あるいはinternal defineを使って
(define (map1 func lst)
(define (map1i lst acc)
(if (null? lst)
acc
(map1i (cdr lst) (cons (func (car lst)) acc))))
(map1i (reverse lst) '()))
Pythonなら人力で末尾再帰最適化をして
def map1(func, lst):
def map1i(lst, acc = []):
while True:
if lst == []:
return accelse:
acc += [func(lst[0])]
lst = lst[1:]
return map1i(lst)
ってなカンジ。
さて、星田さんの記事での以下での実験は大変面白い。
やっぱ実験せんとアカンわな。
それは極めて科学的なスタイルだ。
とりあえず、今の所僕の理解では
(cons (a (cons (b ( cons (c (cons (() ~ )y って感じで式が作られるから頭から追加できるということなのか・・な?
うん、結果そういう事なんだけど・・・。
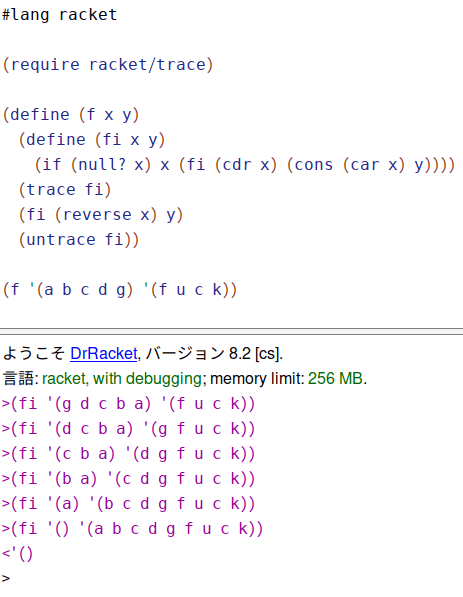
ええとね、Racketで次のように書いてみる。

trace/untraceってのはANSI Common Lisp由来のマクロなんだけど。
これ実行すれば「関数がどういう値を逐次的に返していくのか」図示してくれるのね。
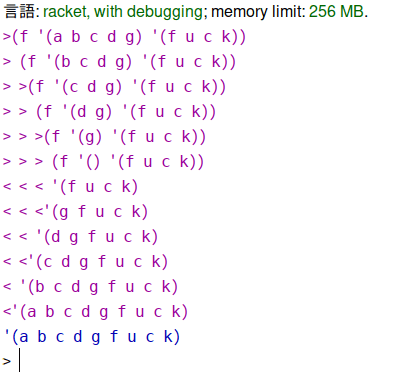
つまりだ。
末尾再帰と再帰の何が違うのか、と言うと、末尾再帰は呼び出されたその時点で呼び出した関数を返しちゃう。
ところが、単なる再帰だと「再帰部分を含んだ計算を返さなければならない」為、再帰部分の展開が全部終了しないと残った計算はずーっと待機状態になるわけ。
言い換えると、スタック上で値を保持したままいなきゃなんないのね。
(define (f x y)
(if (null? x)
y
(cons (car x) (f (cdr x) y)))) ; <- ここで再帰呼び出ししても計算自体は終了してないので待機状態になる
つまり、上だと (f (cdr x) y)が呼び出されてもxがまだnullじゃないとまた再帰部分に潜らなきゃならない。で、そうなると(cons (car x)ってのが「何も出来なくて」待機状態になるわけね。
それがxがnullだと確定するまで「待ち」になるわけよ。ずーっとそのままでボーッと待ってる(笑)。
言い換えると、そういう風にスタック上でボケーっとしてる時間が長い為、一般に「再帰は効率が悪い」って思われてるのね。
そしてPythonで再帰すると、すぐ「RecursionError: maximum recursion depth exceeded. 」ってバカなエラーを返すのもそれが理由。「計算が終わらない」前提でスタックをどんどんと食いつぶしながら「ボケーッと再帰部分が最奥に達するのを」待ってるから、だ。
まぁ、いずれにせよ、再帰で分かんない事があったら、traceしてみる、ってのがANSI Common Lispから来たテクニック。
同時に、例えば末尾再帰版appendを書いてみて、やっぱりtraceしてみればいい。「再帰呼び出しされた時点でその関数を返してる」のが図示される為、スタックを消費しない、ってのが分かるでしょう。
今回は、以上。














