








ARYOP プチコン3号のオブションの高度サウンドユニットに付属されている命令が速い。およそこれまでの80倍!
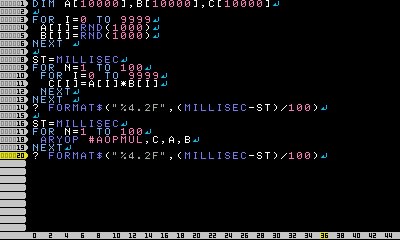
プログラムの実行結果
157.03 ms
1.96 ms
80倍近く速い
(プログラムの内容は配列一万個どうしの掛け算)
この命令、配列をごっそりまとめて簡単な計算してくれるという変わった命令
ほかの言語でも見かけたことがない。アセンブラとかにあるのだろうか?
#AOPMAD演算とか『スーパーコンピューターを20万円で創る』のGRAPEを思い出しました。
しばらく、この命令でポリゴンの座標計算プログラム作ってました。

プチコンBIG待たずにテクスチャーマッピングとかいけます。画像はちょっとバンプマッピングっぽいことをしてます。
他の言語と比較してみました。

10000回まわしてみました。さらに80倍近く速いだと…
ようし、こうなったらC++で勝負だ
私の場合、何と戦っているのか、だいたい不明です。
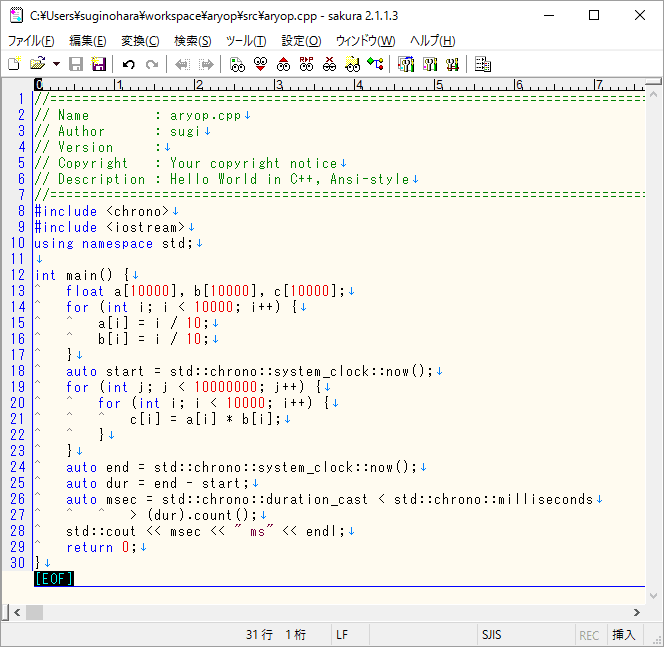
久しぶりのC++ コーディングしてみて、あっという間になまっているのを実感する。
g++ -o aryop.exe aryop.cpp -std=c++11
(忘れたときのためにコマンドをメモメモ...)
コンパイルして…
実行
65 ms
ただしprocessingのjavaと同じループ回数だと0ms表示だったためループ回数をさらに1000倍している。
最適化がどれぐらい働きかけているかは不明だけど
ARYOPの30万倍以上速い
もう何が何だかわからない。
これは家にある、世間的には旧式のマシンの話。
最近のパソコンなら、このプログラムでも 0msなのかも。
ようし、こうなったら...
参考文献
座標回転公式と球面三角法
手を動かしてさくさく理解する C言語/C++ 処理時間計測 入門
『スーパーコンピューターを20万円で創る』
以下蛇足--------------------------------
このあとOpenCLとかCUDAをちょっとやろうとして、
AMD NVIDIA Intel マイクロソフトなどの壁に阻まれて一時挫折します。
バージョンアップの嵐でネットの情報もまちまちだし難しいし、撤退もやむなし。
2009年版のMacbook OS Xで試してみたら28msと同じぐらいのスペックのCPUなのに倍速が出ました。73万倍
このMacbookのOSを切り替えてUbuntu 14.10で試すと最速時に23msでました。85万倍
C++のプログラム掛け算のベースの値が違うので同じように変更してみましたがほとんど変わらなかったです。
これでOpenCLつかったらどれぐらいでるのやら。
参考情報
Nintendo 1048 0H 266Mhz×2
メモリ128M
プチコン3号
AMD Athlon Dual Core 4850e 2.5GHz
メモリ6G
Windows 10
Intel Core 2 Duo 2.26GHz
メモリ5G
OS X 10.11.4 & Ubuntu 14.10
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
4/28追記 C++はソースに致命的な、ミスがあり、
20行目にiを0で初期化することを忘れています。失礼いたしました。
再度乱数発生も修正して計測したところ、439ms ARYOPの45倍弱でした。

Intel Core 2 Duo 2.26GHz
メモリ5G
Ubuntu 16.04
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
プログラムの実行結果
157.03 ms
1.96 ms
80倍近く速い
(プログラムの内容は配列一万個どうしの掛け算)
この命令、配列をごっそりまとめて簡単な計算してくれるという変わった命令
ほかの言語でも見かけたことがない。アセンブラとかにあるのだろうか?
#AOPMAD演算とか『スーパーコンピューターを20万円で創る』のGRAPEを思い出しました。
しばらく、この命令でポリゴンの座標計算プログラム作ってました。
プチコンBIG待たずにテクスチャーマッピングとかいけます。画像はちょっとバンプマッピングっぽいことをしてます。
他の言語と比較してみました。
10000回まわしてみました。さらに80倍近く速いだと…
ようし、こうなったらC++で勝負だ
私の場合、何と戦っているのか、だいたい不明です。
久しぶりのC++ コーディングしてみて、あっという間になまっているのを実感する。
g++ -o aryop.exe aryop.cpp -std=c++11
(忘れたときのためにコマンドをメモメモ...)
コンパイルして…
実行
65 ms
ただしprocessingのjavaと同じループ回数だと0ms表示だったためループ回数をさらに1000倍している。
最適化がどれぐらい働きかけているかは不明だけど
もう何が何だかわからない。
これは家にある、世間的には旧式のマシンの話。
最近のパソコンなら、このプログラムでも 0msなのかも。
ようし、こうなったら...
参考文献
座標回転公式と球面三角法
手を動かしてさくさく理解する C言語/C++ 処理時間計測 入門
『スーパーコンピューターを20万円で創る』
以下蛇足--------------------------------
このあとOpenCLとかCUDAをちょっとやろうとして、
AMD NVIDIA Intel マイクロソフトなどの壁に阻まれて一時挫折します。
バージョンアップの嵐でネットの情報もまちまちだし難しいし、撤退もやむなし。
2009年版のMacbook OS Xで試してみたら28msと同じぐらいのスペックのCPUなのに倍速が出ました。
このMacbookのOSを切り替えてUbuntu 14.10で試すと最速時に23msでました。
C++のプログラム掛け算のベースの値が違うので同じように変更してみましたがほとんど変わらなかったです。
これでOpenCLつかったらどれぐらいでるのやら。
参考情報
Nintendo 1048 0H 266Mhz×2
メモリ128M
プチコン3号
AMD Athlon Dual Core 4850e 2.5GHz
メモリ6G
Windows 10
Intel Core 2 Duo 2.26GHz
メモリ5G
OS X 10.11.4 & Ubuntu 14.10
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
4/28追記 C++はソースに致命的な、ミスがあり、
20行目にiを0で初期化することを忘れています。失礼いたしました。
再度乱数発生も修正して計測したところ、439ms ARYOPの45倍弱でした。
Intel Core 2 Duo 2.26GHz
メモリ5G
Ubuntu 16.04
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー









