
何度か書いてるが、「プログラミング言語は全て同じ」と言うわけではない。
ポール・グレアムは次のように書いている。
「自分の経験からすれば、 どんなプログラミング言語も基本的には同じだね」、 そんなふうに言う人は、プログラミング言語についてではなく、 自分がどんなプログラミングをしてきたかについて語っているのだ。
「C言語は全てプログラミングの基礎」と言う人の想定は、実は「全て」じゃなくって、C++とJavaの経験に基づいて言っている。要は「それ以外の言語の経験」なんぞなくて言ってるんだ。
プログラミング言語が「思考の道具」だとすると、そもそもプログラミング言語でプログラミングをする際に「発想の立脚点」からして違う。
その辺なかなか説明するのが難しい。
実際問題、例えば競技プログラミングの問題とか見ると明らかに問題作成上、CやC++やJavaを想定した問題になっている。
一見「どの言語でもいいですよ」って言ってるように見えて違う。これも何度か言ってるが「出力しなさい」と言う以上、それらはC言語系の問題なんだ。そして「配列は固定で伸長不可」って前提の問題だったりする。
この「プログラミング言語はどれも同じ」って発想は色々と間違ってるんだって。
本当なら、PythonならPython、RubyならRuby、とか言語毎に「違ってる」べきなんだよな。全部一緒くたにしよう、ってのがそもそも間違ってるんだ(※1)。
少なくとも、「色んな言語による公平なコード閲覧」が可能なのは知ってる限りRosetta Codeしかなく、日本のアレコレはそういうレベルには到達していない。
つまり、Aizu OnlineだろうとAtCoderだろうと、主催者側は色んなプログラミング言語を知ってるわけじゃないんだ(※2)。
この辺、「プログラミング言語によって"考え方"が全く違う」ってのはなかなか説明するのが難しい。
またその「違い」を受け入れるのも難しいようだ。例えばVisualBasicで
プログラミングを学び始めた人はどうしても「VisualBasicで考えて」そこから離れられない。DOS時代にCを学び始めた人はその当時のCのプログラミング指南からも離れられない(※3)。
ここでは、教えて!gooで見つけてきた問題を題材に使って、LispやPythonで「関数型プログラミング」ではどう考えてプログラミングしていくのか見ていってみよう。
お題は次のようなモノだ。

ここではJavaは扱わない。Javaでのプログラミングだとどっちにしても「フツーの」プログラミングにしかならんから、だ。
なお、人によっては問題を見て「この程度のお題も解けないなんて・・・」とか思うかもしれないが、その辺はスルーしとく。これも前に言ったが、どっちにせよスマホでパソコンのモニタを撮影するような輩はプログラミングが出来ない、んだ。教えて!gooを見てきた限り100%、だ。スマホでPCのモニタを撮影するヤツでマトモなプログラムを書けるヤツは不思議と一人もいなかった。
だからその辺の「質」は考えてもしゃーないんだ。
それよりも、問題自体が全然簡単なんで、「関数型プログラミングならこう考える」と言う例示をするには最適だろう。
また、多少無理くりになる、っつーのも、「問題自体がJavaで考えてる問題だ」と言うのが背景にある。
まず関数型プログラミングの場合、考えるのは「どういうデータを生成するか」だ。ここが始点であって、手続き型言語やオブジェクト指向言語と大幅に違う。
特に、遅延評価あるいはそれに類する機能がある言語の場合、
永久ループを使って
なんて聞いた日にゃあ無限ループなんて絶対に使わない(笑)。ループは「動作」だが、関数型言語のユーザーは、「無限」って言われたら使用するのはデータ、つまり無限長のデータ列、あるいは無限長のシーケンスを使う事を考える。
そう、関数型プログラミング(遅延評価付き)の人たちは「動作」じゃなくってまずは「データ」を考えるんだ。どういうデータを生成しようか、と(※4)。
そして
・1~100までの乱数を発生させる
と聞くと、フツーのプログラミング言語のユーザーは「ループで乱数を何度も作るんだな」と考えるだろうが、(遅延評価付きの)関数型言語のユーザーは「乱数の結果が入った無限長のシーケンスがあればいいんだな」と考える。
要は、フツーの言語のユーザーはループなんかの「動作」で、データを一々生成していく事を考えるけど、関数型言語ユーザーは、既にデータ列があり、そしてそのデータ列を「加工」する事を考えるんだ。
(stream-map
(lambda (x)
(apply random x))
(stream-constant '(0 101)))
stream-constantは引数のデータを持った無限長のシーケンスを生成する。上では'(0 101)を要素に持つ無限長シーケンス、つまり、
('(0 101) '(0 101) '(0 101) ...)
を想定してる。何故に'(0 101)なのか、っつーと生成する乱数(整数)の範囲がそれだから、だ。applyはカッコを外すんで、stream-mapで結果、無限長シーケンス
((random 0 101) (random 0 101) (random 0 101) ...)
を得る。
Pythonの場合は次のように書く。
(randint(*i) for i in repeat((0, 100)))
itertools.repeatはRacketで使ったstream-constantとほぼ同様なイテレータだ。そしてRacketと同様に、それが作る無限長シーケンスの各要素、(0, 100) にrandintをapplyする。いや、Pythonでは2.x時代には実際applyがあったが、今は本当に「カッコを外す」アンパック用の演算子*がある。i(つまり (0, 100) )に付いてる*は「アンパック」を意味してて、結果 randint(0, 100)と言う計算式を生成する。
なお、書式がリスト内包表記に見えるが、カッコがリストの[]ではなく()になってる。これをジェネレータ式と呼ぶ。
リスト内包表記を無限長のシーケンスに適用すると、それこそ無限ループに陥るが、一方、ジェネレータ式なら無限長のシーケンスを無限長のままで処理出来る。つまり、結果も無限長のシーケンスなんだ。
これでループを回す事無く「無限長の乱数列」が入手出来る事となる。
次の情報は、
・このとき数値が5の倍数の時は「スキップ」と出力 continue で処理をスキップ
だ。
これを関数型プログラミングに適用するのはちと厄介に思えるだろ?
でもそうじゃない。「スキップ」って言う通り、5の倍数の時は「何もしない」んだ。でも動作として「何かする」「何もしない」と考えるから混乱するんであって、単純には5の倍数が無限長シーケンス内に無ければいいって事なんだよな。
そう、要は得られた乱数の無限長シーケンスから5の倍数をフィルタリングすればいい、んだ。
よって、Racketではこの部分までを次のように記述する。
(stream-filter
(lambda (y)
(cond ((zero? (modulo y 5))
=> (lambda (bool)
(printf "スキップ~%")
(not bool)))
(else #t)))
(stream-map
(lambda (x)
(apply random x))
(stream-constant '(0 101))))
Lispで良く言われる悪口「ラムダだらけ」に見える(笑)。
しかし、単純には、stream-filterの第1引数の述語(条件を記述した(lambda (y)〜)を満たさないモノをstream-map以降で作ったデータから弾いてるだけ、だ。
問題はその述語が出力を含んでる為、見た目が厄介になっている。
このように、C言語系のプログラミング言語Javaの出題だと、出力が絶対必要、と言う問題を作る傾向がある。
だから言ったろ、問題自体がプログラミング言語の性質を含むんだって。
ついでに言っちゃえば、関数型プログラミングの観点だと、continueやらbreakが多用された場合、まずは条件分岐の設定をどっか間違ったんとちゃうんか、って疑うんだよな。
いや、このテの脱出系機構は絶対プログラミング言語には必要だし、時と場合によっては頼らないとならないんだけど、言っちゃえばこれらはgotoの糖衣構文であって、事実上jumpを書いている。
つまり、これらが多用されてる、ってのは構造化プログラミングじゃない発想でプログラムを組んでる、って事であり、考え方としてはどっか間違った事をやってるんだよ。
しかし、C言語脳はアセンブリ言語的な発想でプログラムを書いてるのでこれらを多用するんだ・・・・・・。
従ってこういう出題を行う。
だからそれにLispで対抗する場合、どうしても述語のラムダ式の内側に出力を忍ばせないとならないが、本質的にはこの部分は真偽値を返すだけの簡単なお仕事をしてる。出力さえ無ければもっと馬鹿みたいに単純な式になることだけ、は間違いないんだ。
なお、この場合、返り値の候補は(not bool)と#tの2つだ。変数boolは(zero? (modulo y 5))を受けていて、この節が実行されると#tが返ってくるんで、それを反転させて返している。
また、プログラミング初心者は出力とreturnを混同しがちだが、出力したあとに返り値をreturnして良い、って事に気づきづらい。まぁ、大体、例題がしょーもなくprintしまくるヤツばっか、ってせいがあるんだけどな。
いずれにせよ、出力は副作用なんで計算自体には全く影響がない、って事をこの例を通じて把握しておこう。
さて、Pythonの場合は、だが。
基本的発想はRacket版と変わらないが、Pythonには若干制限がある。
と言うのも、Pythonのラムダ式はヘナチョコだ。複文が取れない。
と言う事は、Lispみたいに条件判定を無名関数として埋め込めない。
従って、Pythonの場合は述語は述語として独立して作っておいて、本体からそれを呼び出す形式にしないといけない。
def foo(x):
if x % 5 == 0:
print("スキップ")
return False
else:
return True
そのせいで、本体のプログラムは小さくなって可読性が上がる、と言う効果があるんで、ラムダ式がヘナチョコなのを嘆くべきなのか、あるいは使い捨てのスクリプトを書く程度で関数を「キチンと」書かなきゃならない事をメンド臭がるべきなのか、ヒッジョーに微妙だ。
なお、Racketでもこういう風に「単独で述語」を設計出来るんで、Racketの方が「埋め込みにするか」「単独で関数を作るか」その場に応じて選べる。
言い換えるとPythonは可読性を言い訳に選択肢を与えない、って見方も出来るわけだ。
いずれにせよ、Pythonでの本体は次のようなシンプルなモノとなる。
filter(foo, (randint(*i) for i in repeat((0, 100))))
関数filterのやることは通常、最近だとリスト内包表記に置き換えられている。
ただし、リスト内包表記はイテレータを実体化する。今回のケースのように対象のイテレータが「無限長シーケンス」だと、実体化しちまえば無限ループへ陥る。
一方、関数filterはイテレータを受け取りイテレータを返す。つまり、無限長シーケンスを受け取り無限長シーケンスを返す設計になってるんで、実体化しない以上こっちを使うべきだ。
結果、与えられた無限長の乱数列から5の倍数を弾いた無限長シーケンスをこれで生成出来るわけだ。
次の条件はこうだ。
・また数値が7の倍数の時は「hoge」と出力
乱数列を加算しながら数値が7の倍数の時には「hoge」と出力する。
さて、無限長シーケンスを相手取り、そこからやってくる数値を順次加算していく場合はreduce/foldなんかを使う。
当然、SRFI-41にはstream-foldと言う関数があるが、これを使うのはちとマズい。と言うのも、stream-foldは有限長のシーケンス相手にしか使えないんだ。無限長のシーケンスに対応している代替版をstream-scanと言う(※5)。
(stream-scan
(lambda (a b)
(printf "~a~%"
(if (zero? (modulo b 7))
"hoge"
b))
(+ a b))
0
(stream-filter
(lambda (y)
(cond ((zero? (modulo y 5))
=> (lambda (bool)
(printf "スキップ~%")
(not bool)))
(else #t)))
(stream-map
(lambda (x)
(apply random x))
(stream-constant '(0 101)))))
随分と長くなってきたが、これまで見てきた通り、最初に無限長のデータがあって、加工、加工、と言うプロセスだけ、で組み立ててきてるのが分かるだろうか。単純には(foo (bar (baz data)))となってるだけ、だし、改行してインデントしてるだけで本質的にはワンライナーで書いてきてる。
stream-scanで受け取ってるラムダ式も初期値0に無限長シーケンスから受け取る数値を随時加算していってるだけ、だ。本質的な作業はそれだけ、なんだけど、問題の要請によりここでも「無限長シーケンスから渡ってきた数値」が7の倍数の時"hoge"を出力して、それ以外は単にその数値を出力している。
ここも副作用なんで、計算自体には何も影響がない、って事が分かる筈だ。
Python版は例によって、ラムダ式がヘナチョコなんで、Racketではラムダ式を使って埋め込んだ部分を独立した関数にしないといけない。
def bar(x, y):
print('hoge' if y % 7 == 0 else y)
return x + y
これだけ、だ。
また、本体に関してはRacket版と同じように、通常こういう場合はfunctools.reduceを使いたいトコなんだけど、reduceは引数で受け取るイテラブルが有限長の時のみ使用可能だ。無限長のシーケンスを受け取るとお約束で無限ループに陥ってしまう。
こういう無限長のシーケンスを扱う場合に使うのがitertools.accumurateでfilterと同様にイテラブルを受け取ってイテラブルを返す。言い換えると無限長のシーケンスを受け取るとそのまま無限長のシーケンスを返すわけだ。
accumulate(filter(foo, (randint(*i) for i in repeat((0, 100)))),
func = bar,
initial = 0)
Racketのstream-scanと違ってPythonのaccumulateは適用する関数と初期値をキーワード引数で指定する。適用する関数funcには先程作ったbarを、初期値initialには0を指定する。
最後の条件はこれだ、
・合計が500を超えたら「break」と出力しbreakで処理を抜ける
Racketのstream-scanもPythonのaccumulateもその時点時点での「総和」が詰まった無限長シーケンスを返してる。つまりどっかの地点で総和が500を超えた瞬間の情報を内包してて、そこまでのシーケンスを「切り取って」持ってくればいい。
そのための関数がRacketではstream-take-while、Pythonではitertools.takewhileだ。
(stream-take-while
(lambda (z)
(cond ((> z 500)
=> (lambda (v)
(printf "break~%")
(not v)))
(else #t)))
(stream-scan
(lambda (a b)
(printf "~a~%"
(if (zero? (modulo b 7))
"hoge"
b))
(+ a b))
0
(stream-filter
(lambda (y)
(cond ((zero? (modulo y 5))
=> (lambda (bool)
(printf "スキップ~%")
(not bool)))
(else #t)))
(stream-map
(lambda (x)
(apply random x))
(stream-constant '(0 101))))))
stream-scanによる総和の無限シーケンスのどれかが500を超えた時点で、stream-take-whileは与えられたラムダ式に従って"break"を出力し、そこまでのシーケンスを切り取って返す。つまりここで無限長のシーケンスが有限長のシーケンスに変換されたわけだ。
Pythonの場合、例によって独立した関数bazを設計する。
def baz(x):
if x > 500:
print('break')
return False
else:
return True
そしてtakewhileを使って次のように書く。
takewhile(baz,
accumulate(filter(foo, (randint(*i) for i in repeat((0, 100)))),
func = bar,
initial = 0))
これで終わり、だ。
終わりなんだけど、実行するとRacketの場合は不可思議な表記が出てくるだろう。

Pythonの場合だと表記さえ出てこない。中にprintを仕込んでる筈なのに。おかしいな、と。
これ、なんでか、と言うと確かにデータは作ったんだよ。ただし、それらは実体化していない。Pythonで言うと「中にprintを仕込んだ」けど、まだそれらは実行されてないんだ。
こういう「関数が使われていても未実行」の状態をコンピュータサイエンスではプロミス、と呼んだり、あるいはサンク、って呼んだりする。
そしてRacketで表示されてるstream、あるいはPythonで言うイテレータは言っちゃえばプロミスで構成されたデータ型なんだ。
まだ実体化してないような「処理の約束事」で組み上げたデータ型を遅延シーケンス等と呼び、何故にRacketやPythonで無限長のデータ型を扱ってるのに無限ループを起こさないか、と言うのも無限長のデータ型が遅延シーケンスで「まだ実行されてないから」なんだ。
そしてこのように、遅延シーケンスを用いたプログラミングテクニックを遅延評価と呼ぶ(※6)。
Racketで遅延シーケンスを実体化させる一番簡単なテはstream->listで遅延シーケンスをフツーのリストに直してしまうこと、だ。今まで書いてきたコードをstream->listで包んでやればいい。
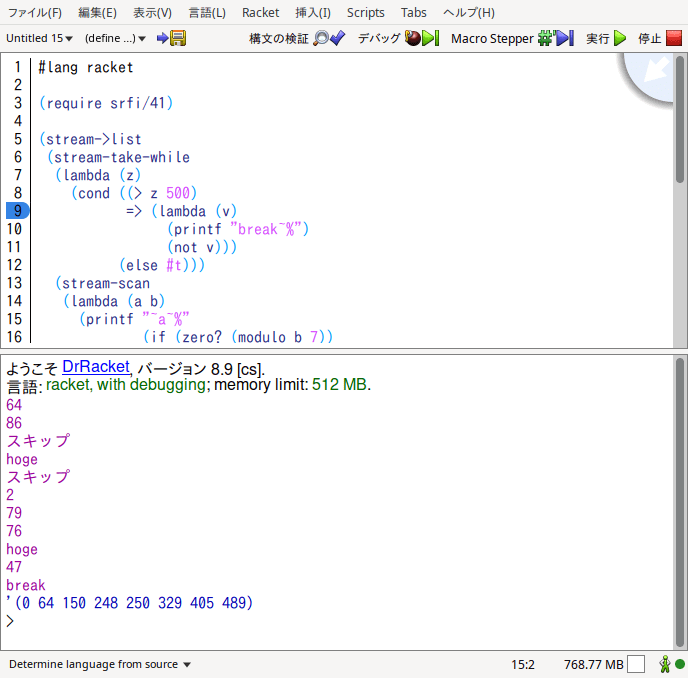
返り値としてリストが返ってくるが、中身を見てみれば「乱数を加算していってる」過程が分かるだろう。そして500を超える前に計算を終わらせている・・・と言うより、500を超える手前で無限長シーケンスから有限長シーケンスとして「切り取った」結果をリストに変換してるわけだ。
また、その結果を見れば分かるが、出力関数displayの影響は全くない。副作用を副作用として用いて、返り値には全く関係なかった、からだ。
Racket版の完成コードはここに置いておこう。
Pythonでの無限長シーケンスの実体化は、いくつか方策が考えられる。
- Racketのようにリスト化する。
- forループで回す。
- リスト内包表記で実体化する。
どれを使ってもいいだろうが、ここではforループで回してみようか。
for i in takewhile(baz,
accumulate(filter(foo, (randint(*i) for i in repeat((0, 100)))),
func = bar,
initial = 0)):
i
forはイテレータから要素を一個一個引っこ抜いてくるんで、iが取り出された時点でiのプロミスは解除され実行される。
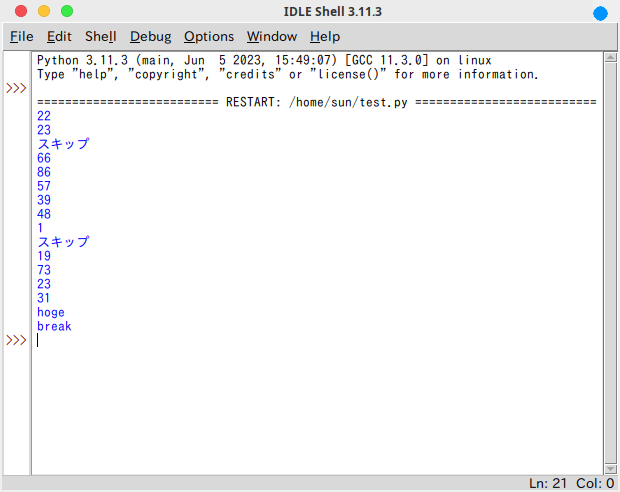
僕は滅多にforループは使わないんだけど、いずれにせよ、こちらもプロミスが解除されて題意が実行されてるのが分かるだろう。
もちろん、Racketみたいにリストにしてもいいし、リスト内包表記で実体化させても良い。好きにやってほしい。
Python版のコードはここに置いておこう。
関数型プログラミングの発想がちょっとは掴めただろうか。
関数型プログラミングは「何かの動作を直接書き下す」よりも「データ設計」をまずして、そのデータを「加工に継ぐ加工」で目的を得る。しかもその「加工」は破壊的変更ではない。一律「元データを参照して加工したもの」をまた再加工して・・・と言うプロセスを踏んでいくんだ。
なお、最近はRustのコードも見せてるんだけど、あいにく、Rustにはいまだ無限長のシーケンスが扱えない。
実験版では実装されてる模様だが、まだまだRust自体での遅延シーケンス機構のプログラミングが難しいらしく、安定版では日の目を見てない模様だ。
従って省いた。
また、Javaでもこの考え方で実装出来るか?と思ったんだけど、あいにくJavaにはPythonで言うitertools.accumulateがない。reduceはあってもaccumulateがない、ってのは設計上の片手落ちと言って良く・・・いや、要はJavaは色々とおかしなトコがある言語だ、ってそれだけの話だ(笑)。多分この辺の遅延評価のプログラミングに詳しくない人が無理矢理「流行り」だから実装してみました、って程度のアレしか無いような気がする(笑)。
いや、Javaユーザーは怒るかもしれんけど、実際ライブラリが「遅延シーケンスの使い込み」を妨げるような構成になってるのは事実なんだ。中間操作だ何だ、って「区分け」するのもおかしいし、reduceが初期値に数値しか取れない、ってのもおかしい。
関数型言語ユーザーが「関数型言語だったら当たり前に使える機能」がJavaには欠けてる、ってのはホント単に「おかしい」んだっての。それだけの話、だ。
と言うわけで、今回の話はおしまい。
※1: ANSI Common Lisp向けのWeb問題集ならNinety-Nine Lisp Problemsが有名(とは言っても問題自体は元々Prolog向けのモノだったらしいが)。
※2: ここで「知ってる」と言うのは、「知識として知ってる」とか「触った事がある」程度の話をしてるわけじゃない。キチンとそのプログラミング言語を勉強して「なにかを書き上げた経験がある」と言う事を指している。
なお、最近のPython入門本出版ブームの著者陣は「Pythonを知らないで」そのテの本を書いてる、って事は何度か指摘してる。
※3: DOS時代のパソコンは2023年時点でのパソコンの性能より遥かに低く、特にメモリがメチャクチャ少なかったので、大域変数使いまくりの破壊的変更しまくりのプログラミング方法じゃないと「効率が悪かった」。
つまり、実はDOSでの「C言語プログラミング」は、当時のUNIXが走ってた「メモリが豊潤なメインフレーム」でのプログラミング指南とも大幅に違ってたわけだ。
文字通り、DOS向けのC言語プログラミングは明らかに「アセンブリ言語代わり」で、現代でもそのプログラミング指南の影響が大きく、それはUNIXのそれとは実は大きく違う。
※4: 実はLisperはそれほどでもない(笑)。このテの発想に特に慣れてるのは、「遅延評価が根幹にある」関数型プログラミング言語、Haskellのユーザーだろう。
※5: ただし、stream-scanで受け取る関数・・・カッコイイ言い方をすればコールバック関数の引数順序は、reduceやfoldl、fold、stream-foldとは逆順になっている・・・いや、結果フツーの関数の引数順序で良い、って事だが。
要は直感的に書いてイイ。
※6: 厳密には違うが、まぁそう考えていい。
本来の意味だとプログラミング言語自体の評価方式を指し、通常、関数上では、引数を評価してから関数を適用させる事に対し、関数を評価したあと、引数を「必要に応じて」評価したあと関数を適用する方式を「遅延評価」と呼ぶ。
つまり、言語設計に於ける「評価方式」が遅延評価なのかそうじゃないのか、と言うのが本来のコンテクストなんだけど、最近ではとあるデータ型に対して遅延評価のデータなのか否か、と言う狭義の使い方が主流となっている。
なお、歴史的にはLisp「だけ」が通常の評価方式と遅延評価のシステムを両方持っていて、関数定義の際に「フツーの関数」と「遅延評価の関数」を分ける事が出来、古くは例えば現在「特殊形式」と言われるsetq(Racketでのset!)は「遅延評価方式で定義された関数」だった。
一方、Lispのメッカ、MITでは、「遅延評価の関数」とコンパイラに作用する「マクロ」を統合した。両者とも「引数を最後に評価する」と言う技術上のテクニックは全く同じだった、からだ。
そう、Lispで言うマクロは、コンパイル時に「展開する」と言う性質はともかくとして、見方によっては「遅延評価で組み立てる関数」そのもの、なんだ。
結果、プログラミング言語の評価方式として、遅延評価を採用してる陣営から「マクロ不要論」が出てくる理由は、「遅延評価を根本に持ってればマクロは必要ない」と言う技術上の主張による。
例えば通常、Lispでは条件式の根幹であるifはユーザー定義出来ないが、一方、遅延評価を基礎としたプログラミング言語では条件分岐は関数として実装可能であり、事実上、確かに「全部がマクロである」プログラミング言語になっている。













