
星田さんの記事に対するコメント。
>> 8/11
String=<>?の件でも思い知ったけど、ざっと目を通すだけでもR7rsとかRacketガイド、Racketリファレンスに目を通しておこうと思いました。
そうね、最低でもR7RSには目を通しておいた方がいいかな・・・・・・。
ホントはね。「仕様書」ってのは実装者向け情報なのよ。Scheme実装を「作る」側が頼る書物なんだけど・・・・・・。
Lispって言うかSchemeを学んでプログラミングに於いて1つ良い習慣を付けられる、とすると、疑問に感じたら仕様書に目を通す癖を付けられる事だと思う。
実際問題、フツー、プログラミングをする、って人は仕様書に目を通す事が少ない。
理由は大体次の2つだ。
- 単純に仕様書が無い言語の方が多い。
- 仕様書は売ってはいるが、高いし厚い。
例えば、Pythonには仕様書がない。従って、どうして言語がそのような実装になってるか、が分からん。また、「Pythonを作りたい!」って思っても走らせながら動作を確認して、徒手空拳で実装するしかない。そして最大の問題は、「これはおかしな動作だ」って思ってもバグかどうか判断がつかない事がままある。
2番目も悩ましい。
例えば日本国内だと、「C言語をやってます」と言う場合、本来なら仕様全部を目にするべきなんだけど、JISで仕様書が売ってはいるが、結構高い。そして分冊されてて全部目を通すには物凄く大変なんだ。
2番目の場合、「権威ある公式仕様」なんだけど、購入して参照するには結構敷居が高いのね(※1)。
だから例えば「C言語やってます」って人でも仕様を読んだ事がある人って結構少ないと思う。殆どの人が「仕様がある」とか「ない」なんかも気にしてないでしょ。
一方、Schemeの場合、「権威ある仕様書はない」んだけど、仕様は公開されてるし、基本それは薄い(※2)。だから入手が簡単だし、読むのも比較的苦労しない。だから「仕様を読む」って習慣をつけるには物凄くいい言語なわけ。
ところで、「仕様書」って言うのはなにか。これは例えば、本来の意味から言うと、「ユーザーマニュアル」的なリファレンス用途の文書じゃないんだ。
「仕様書」とはなにか。その文書で説明されているようにプログラムを組んでいくと、自然とその言語の実装が出来る、って類の文書なのね。まぁ、ある種理想論なんだけど。
つまり、上で書いてる、例えばJISのCの仕様書を入手したとして、そこで書かれたようにプログラムを組めばC言語処理系を自然と作れてる、って意味になるわけ。R7RSを入手して、そこに書いてる通りにプログラムしていくと、自然とそれはSchemeになってるわけだ。逆に、ユーザーマニュアルを読んでその通りに実装してもその言語にはならない。と言うか「その言語を作れるようには」書いてない。それが仕様書とユーザーマニュアルの決定的な違いなわけ。
言い換えると、「仕様書がある言語」と言うのは、「その仕様書が書いてる事柄を最低限全部実装せなアカン」と言う約束事があるのね(※3)。当然それは「独自拡張をしちゃいけない」と言う意味じゃない。その仕様書が書いてる全機能を実装して、なおかつ追加で自分が必要な機能は追加して良い。
これにより、GaucheとSagittarius(※4)とpicrin(※5)は基本的な機能はR7RSにより共有されている。つまり、これらの何が仕様の要求で何が独自拡張なのかを意識する事が出来る、と言う事だ。なんかめんどくさそうに思うかもしれないけど、プログラミング言語実装を使うに於いてはかなり重要な観点で、それを比較的簡単に学べるSchemeは、やはり学習用言語としては(意図してるかは知らんが)良いポジションを与えてくれている。
実際、Schemeを学ぶと仕様を簡単に閲覧出来ない言語を使う事が気持ち悪くなるだろう(笑)。ユーザーマニュアルじゃダメなんだ。Pythonみたいな仕様=実装言語を使うと安心出来なくなる。それは保証がないに等しいから、だな。ついでに、いつ仕様/実装が変更になるかも分からん。文書で仕様が確定されてる、ってのがどれほどありがたいか実感するようになっていくだろう(※6)。
とまず、仕様とそれを読む事の重要性を強調しておいて、だ。

Racketのドキュメントだけど読んでみると、引数xyなのはこのルールがあるからかな?高階関数の手続きとして使われた場合は持ってくるリストが後ろに無いのもなるほどか・・もっと読んでもっと書かないといかんな〜(いつもの結論)。
実はSchemeにはsortがない、ってのに気づいただろうか(笑)?
そう、実はsortはSchemeの仕様範囲外の関数なんだ。
もちろん、sortがあるScheme実装が多いのは事実だろう。ただし、それは独自拡張なんだよ。実装者側が
「sort無いと不便だろ」
ってぇんで入れてくれてるだけ、だ。
ここで仕様の重要性が分かると思う。sortがないScheme実装があっても文句を言ってはいけないのだ(笑)。そしてsortに関しての一般論はSchemeじゃ語れない、って事になる。
なんでSchemeにsortがないんだろうね?便利なのに。
一つの理由としては、コンピュータサイエンスの宿題のネタを潰したくないから(笑)?アルゴリズムの宿題で実装せよ、って言うのでは定番のネタだしな(笑)。
まぁ、それは冗談としても、いつか書いたけど、ソートアルゴリズムにはこれって定番がないからだ。
Schemeの仕様決定はかなり慎重だ。選択肢が「ありすぎる」場合はそれを仕様に含めるのはなるたけ避けようとする。ソートには大まかには二種類存在する。「安定ソート」と「不安定ソート」の二種類だ。両者とも仕様に含めます、なんて決定はSchemeの仕様じゃあやりたがらないだろうしね。だから「無い」。
とは言っても、実装側が「sortを入れます」と言うのを邪魔するモンじゃない。その辺勝手にしたら?と言うのが仕様のポジション。
んで、大体こういう便利機能はANSI Common Lispにはあるわけ。だからANSI Common Lispの形式を借りてくる、ってのが大方のScheme実装者の判断となる。
で、だ。まずANSI Common Lispのsortってのも高階関数で、大方のケースではその基本機能の「見た目」を借りてきてる。
> (define *tester* '((1 2 3) (4 5 6) (7 8 9)))
> (sort *tester* (lambda (x y) (> (car x) (car y))))
'((7 8 9) (4 5 6) (1 2 3))
これは今まで書いてきた通り、一般論になるかどうかは分からん。実装次第なんだけど、例えば上の例で与えてるラムダ式は、与えられたリストのどの部分に着目してソーティングを噛ますかの指示を与えてる。
上の例の場合、リストが要素のリストが与えられてて、内側のリストのどの部分(具体的にはcar)の大小比較を基にしてのソーティングが指示されている。
また、2つの引数の大小比較が基になるんで、当然、与えるラムダ式は二引数関数だ、ってのが基本となる。
繰り返すけど、sortの実装はScheme実装によって違う。
例えば、Racketなら、上のようにラムダ式を与えなくても、#:keyによってどの部分を比較したいか指定して、あとはフツーに比較関数を与えても上と同様の結果が返るように設計されている。
> (define *tester* '((1 2 3) (4 5 6) (7 8 9)))> (sort *tester* > #:key car)
'((7 8 9) (4 5 6) (1 2 3))
>
Racketの場合、ANSI Common Lispっぽいキーワード引数を利用した実装になってるけど、Gaucheの場合はオプショナル引数扱いになっている。

このように、仕様に含まれて無く、またSRFIで提案されてない機能の場合、これらはユーザーマニュアルに頼って調べなきゃならない、って事だ。そしてこう言う場合はポータブルなコード(※7)を書くのは難しくなってくる。
> (sort (let ((commitee-data
'((("JonL" "White") "Iteration")
(("Dick" "Waters") "Iteration")
(("Dick" "Gabriel") "Objects")
(("Kent" "Pitman") "Conditions")
(("Gregor" "kiczales") "Objects")
(("David" "Moon") "Objects")
(("Kathy" "Chapman") "Editorial")
(("Larry" "Masinter") "Cleanup")
(("Sandra" "Loosemore") "Compiler"))))
commitee-data) string<? #:key cadr)
'((("Larry" "Masinter") "Cleanup") ;;; ここから返り値
(("Sandra" "Loosemore") "Compiler")
(("Kent" "Pitman") "Conditions")
(("Kathy" "Chapman") "Editorial")
(("JonL" "White") "Iteration")
(("Dick" "Waters") "Iteration")
(("Dick" "Gabriel") "Objects")
(("Gregor" "kiczales") "Objects")
(("David" "Moon") "Objects"))
>
リストの各要素のcadrに従ってRacketでソーティングする例。同項目は与えられたリストと同じ順番を保持してるので、Racketでのsort関数は安定ソートであると分かる。

Gaucheの場合、マニュアルに拠ると、オプショナル引数に比較関数を指定するか否かで挙動が変わる、との事。この例のように比較関数を指定する事によって安定ソートが実現出来る。
ちなみに、この例ではRacketでもGacheでも最速ソートであるクイックソートが使われなかった、と言う事が分かる。何故ならクイックソートは不安定ソートだからだ。
>> 2022/08/15
matchがネタ。
matchは非常に便利だ。ただし、これも仕様範囲外の独自実装だ。
だからRacketとGaucheでは使い方が被ってるところもあれば表記が違う事がある。Gaucheのユーザーマニュアルを読んだらRacketのユーザーマニュアルも読んでおこう。Gaucheのレコード型に対する対応とRacketのstructに対する対応が一致してるたぁ限らないからね。
個人的にはRacketの方が直感的だとは思うんだけど、Gaucheの方は根拠がないわけじゃなくって、Andrew K. Wrightって人が書いたScheme用のパターンマッチャーがある意味デファクトスタンダードになってて、それに従ってる模様。
割にね、Racketは「独自仕様」を突き詰めるタイプなんだけど、Gaucheの場合は標準っぽい扱いになってる何かがあれば独自実装をするよりそっちを重要視して実装していく、ってカンジ。
まぁ、いずれにせよ、繰り返すけど何が仕様か把握できれば自ずとから何が独自実装なのか分かってくる。
と言う事は、ユーザーマニュアル読むにせよ、ピンポイントで調べたい事がハッキリ分かってくる、って事でもあるんだ。
matchもその例になると思う。
>> 2022/08/22

パターンマッチングを調べていてふと見たページにあった「式」の定義。あ!そういうことか!評価して値が返るものが式・・今更だけど腑に落ちる定義だった・・
うん、これもLispのせいで分かりづらくなってるかも(笑)。
っつーか、Lispには式しかない。式指向言語だ。だからLispやってると「何が式か」ってあんま意識せんのよね。全部式だから。
通常、Lisp以外のプログラミング言語には式の他に文がある。
例えばPythonの条件分岐はif文だ。しかし、Lispの場合は(こういう言い方はせんのだが)if式なの。
例えば、だぜ。
Pythonでこういう書き方をするとエラーになる。
location = "大阪"
val = if location = "大阪":
return "星田オステオパシー"
else:
return "日本オステオパシー連合"
何故かと言うとif文は文である以上、返り値があってもそれを直接変数に代入する事が許されない。これは大方の言語だと許されない書き方なの(※8)。
ただし、Lispならすべてが式である以上、上みたいなプログラムは書いて良いプログラムとなる。
(define *location* "大阪")
(define val (if (string=? *location* "大阪")
"星田オステオパシー"
"日本オステオパシー連合"))
>> 2022/08/24

あ、その前に||って?orか・・
プログラミングでは頻出のand、or、notなんだけど、これはホンマ、各言語で表示がかなり変わるので手癖だと苦労する要素でもある。
なお、Schemeだと当然、
(define-syntax &&
(syntax-rules ()
((_) (and))
((_ x ...) (and x ...))))
(define-syntax ||
(syntax-rules ()
((_) (or))
((_ x ...) (or x ...))))
と記号で再定義してもいい。
>> 2022/08/26
>> 2022/08/29
ネタは挿入ソートなんだけど、コード例はここにあります。
で、「プログラミングの基礎」のやり方だとRacketではこう。

Gaucheだとこうかな。
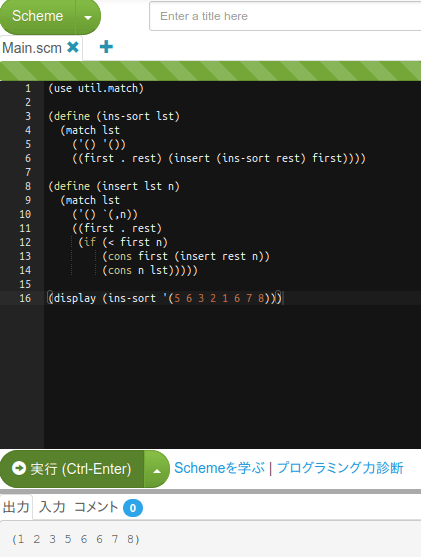
多分到達出来てると思うけどね。
>> 2022/08/30

合成関数「compose」を作れという。お手本だけど恐ろしくスッキリしてますなぁ。スッキリしすぎてよく分からん。まあ、どうせ*目的*しか見ないで作るわけだけど。
まず、合成関数自体は数学なんで、定義はそちらから。
OCamlのコードをRacket/Gaucheで直訳すると次のようになる。
(define (compose f g)
(define (h x) (f (g x)))
h)
Scheme/Racketは、当然ラムダ式も使うんだけど、ローカル関数も異様に使う言語なんでローカル関数使用をためらわない事(※9)。
また、原理的にはcomposeはクロージャを返す関数なので外側の仮引数には関数以外は要らなくなるだろう。
つまり、

が記法となる筈。
なお、ホンマモンのLispらしいcomposeの記述は、ポール・グレアムのOn Lispを参考に。
;;; Racket(define (compose . fns)
(if (null? fns)
identity
(let ((fn1 (last fns))
(fns (take fns (sub1 (length fns)))))
(lambda args
(foldr (lambda (fn x)
(fn x)) (apply fn1 args) fns)))))

あるいは、せっかく覚えたmatchを活用して、
;;; Racket(define (compose . fns)
(match (reverse fns)
('() identity)
((cons fn1 fns) (lambda args
(foldl (lambda (fn x)
(fn x)) (apply fn1 args) fns)))))

としてもいいかもしんない。
ポール・グレアムのオリジナルの版は可変長引数で受け取った関数群(ここがリストにまとめられる)を「分解」するのにオーソドックスな手を使ってて、だからこそちとメンドいんだけど、パターンマッチで分解した方が、コード的にはシンプルになるぞ、と言うmatchの有用性を示す好例になっていると思う。
※1: JIS(日本産業規格)と言う権威で、仕様書が公式に制定されているのは、現在11個のプログラミング言語しかない。
- Fortran
- COBOL
- FullBasic
- PASCAL
- C
- MUMPS
- ISLISP
- C++
- C#
- Ruby
- EcmaScript(いわゆるJavaScript)
※2: ただし、R6RSと言う前回の仕様はデカかった。また、まだ未発表のR7RS-largeがどうなるかは分からん。
※3: 考えてみるとRacketの前身、PLT Schemeが「Schemeを止めだした」のは3.8の頃に遡る。この時、Schemeの仕様にあるset-car!とset-cdr!を実装するのを止めたんだ。理由は「みんな破壊的変更しないほうがいいでしょ?」ってモノで、でもこういう「仕様書に違反しても誰も何も言わない」辺りが、「権威がない仕様書」の残念な辺りだ。
PLT Schemeはリストをイミュータブルなモノとした。結果、原理的に言うと、この時点でPLT SchemeのリストはLisp言語族の言うリストではなく、用途的にはPythonのタプルと近いモノとなる。
そしてPLT Schemeは4.0になって暫くしてから、Schemeである事を完全に止め、名称をRacketとしたんだ。
現時点で、Racketがなにか、と言うと、Pythonのような実装=仕様の言語、あるいはSchemeではないが、Schemeの方言、と言う立場になっている。いずれにせよ、Schemeそのものではない。
※4: オランダ在住の日本人プログラマによる比較的新しい処理系。
※5: これも日本人実装者によるScheme処理系。っつーか、R7RS-smallでさえ真面目に実装してるヤツは日本人しかいない、って言っていいくらいだ(爆
殆どのScheme処理系はR5RS実装で止まっており、事実上、R5RSがSchemeのデファクトスタンダードになっている。
※6: この辺、額面通りに受け取れば、日本には真のCプログラマ、なんてのも数が少ない、と言う事実に気づくだろう。仕様もさておき、マジョリティのマシンにはMicrosoftのOSが走っていて、そしていっちゃんメジャーなMicrosoftのC言語処理系がJISの仕様を満たさないと言う状況だからだ。そして出てくる入門書も旧いANSI仕様に則ったモノばっか、と言うのが最悪のケースなんだ。それは既にC言語ではなく、結果、現在でもC言語ではないなんか違うモノを学ばされている学生が多い、と言う事になる。
Microsoftの名誉の為に言っておくと、現時点ではMicrosoftのC言語処理系は最新のISOのC言語規格に則っている。しかしながら、今度はJISが追っついてなく(JISのCはISOのC99に従っている)、いまだC周りは歪な状態になっていて、まだ是正されていない。
※7: ポータブルなコード、と言うのは可搬性があるコード、の意。つまり同じソースコードを、例えば同じR7RSに従ってるGaucheとSagittariusとPicrinで使いまわすのが難しくなる、って事だ。
この、独自拡張を当てにするとポータブルなコードにならない、と言うのが、例えばLinuxのC言語用ソースコードとWindowsのそれの間で移植が難しくなる原因だ。
※8: Lisp型の、式としての条件分岐が欲しい、と言うニーズに対し、Pythonを含む大方の言語には三項演算子と言う機能が搭載されている。
ただし、Lisperは、「文と式を分ける」と言う言語設計方針がそもそも間違っていて、これがあるが故に三項演算子と言う「余計な追加機能」が必要になり、言語仕様が肥大化/混乱する、と考えてる人が多い。
なお、プログラミング言語Rustは構文の見た目をC系言語に寄せつつ、条件分岐は式にしたりしてて、明らかにLispに寄せている。
※9: ANSI Common Lispのdefunはとにかくグローバルで関数を定義しようとするので、Schemeみたいに「重ねがけ」出来ない。エラーにはならないが、ある関数内でローカル関数を定義したつもりでもグローバル定義になってしまう。
従って、ANSI Common Lispだとローカル関数定義がメンド臭いし、グローバルでガンガン関数を定義してもパッケージ機構があるのでパッケージ内で名前空間を汚してもプログラム全体では名前空間が汚染されない、と言う特徴があるので、あまりANSI Common Lispではローカル関数は使用されない模様だ。
一方、例えばPythonなんかではScheme同様ガンガンローカル関数を定義して構わないので、Schemeではローカル関数を使いまくる練習をすべきだ。










