









引き続いて、Generative Deep Learning [1] の 4章 Conditional GAN (CGAN)のサンプル (cgan.ipynb)[2]を何とか実行。多少パラメータをいじることで、やっとそれらしい結果を得られた。
cgan.ipynbは、セレブ顔画像セットを Blond_Hairであるかどうかでラベル付きで学習し、生成する画像をブロンドにするかどうかをラベルで制御できるようにするというもの。
前回のサンプルまではそのままで動いたが、cgan.jpynbは2か所ほど手を加える必要があった。
変更点1: トレーニングデータ不足を補うため、下記のようにrepeatメソッドを追加。これをしないと学習の途中でデータが尽きたといって止まってしまう。

変更点2: ブラウザとjupyter labの負荷軽減のため途中経過の画像出力の頻度を制限。これをしないと、ブラウザあるいはjpyterのサーバがクラッシュすることがある。

実行環境は、メモリが16GBでCPUが Core i5 10600 (3.3GHz) 6 コア 12 Thread.
前回のWGANがRTX A2000だと無理だったので、最初からあきらめてCPUでの実行とした。
最初は、動かすための前記変更だけを行ったサンプルコードの場合。
全部で2000epoch のうち、500epochごとの進捗がこちら. おなじlatent空間の点からlabelだけ変えて生成した画像を並べている。
501/2000

1001/2000

1501/2000

1991/2000

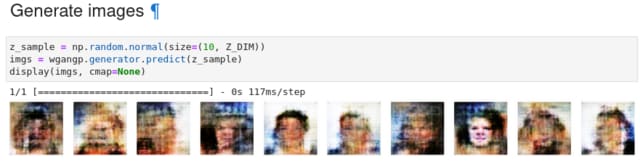
そして、学習完了後に生成画像がこちら。なお、latent空間の点はお互いにばらばら。

金髪か否かで生成し分けているのだが、どうだろう。 言われればそうかもしれないが、よくわからない。そもそも、顔イメージそのものが学習しきれていないように思うがどうだろう。
ちなみに、学習にかかった時間は120分30秒
まず試したのがcriticの回数をepockあたり3回から5回に増やすこと。
501/2000

1001/2000

1501/2000

1981/2000

Generate imagesの結果

所要時間 3時間6分 (186分)
次に、criticをepockあたり5回で、さらにepochの回数を倍の4000にした。
1001/4000

2001/4000

3001/4000

3951/4000
Generate imagesの結果

所要時間 6時間12分(372分)
ばらばらのlaten vectorから作った画像を並べた Generate images の結果だと分かりにくいが、同じlatent vectorからlabelだけ変えて作った画像を並べた3951epochでの画像をみると、Blond Hair という属性を学習して画像を作り分けられるようになったと言えるだろう。
CGANサンプルの実行にはかなり時間がかかりしんどかった。学習に費やされる時間が長かったのはもちろんだが、エラー終了してしまって無駄になった時間がさらに長かった。延々とCPUを走らせて、そろそろ終わりかなというところブラウザがクラッシュとかなると、ちょっと辛い。
いろいろと試すには大容量VRAMを搭載したGPUが必須かな...
24GBを積んだP40ならヤフオクでも3万円で出品されているけれど、パッシブ冷却だからパワフルな送風ファンが必須。AI実験用のサブPCは、古いタワーなので 送風ファンのスペースが足りなくてP40は使えない。メインPCは、そのつもりで買った大型ケースなので送風ファンごと収まるけれど、AIの実験でメインPCが長い時間使えなくなるのが不便。それが理由でAI実験環境にサブPCに移したのだからなぁ。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition
cgan.ipynbは、セレブ顔画像セットを Blond_Hairであるかどうかでラベル付きで学習し、生成する画像をブロンドにするかどうかをラベルで制御できるようにするというもの。
前回のサンプルまではそのままで動いたが、cgan.jpynbは2か所ほど手を加える必要があった。
変更点1: トレーニングデータ不足を補うため、下記のようにrepeatメソッドを追加。これをしないと学習の途中でデータが尽きたといって止まってしまう。
変更点2: ブラウザとjupyter labの負荷軽減のため途中経過の画像出力の頻度を制限。これをしないと、ブラウザあるいはjpyterのサーバがクラッシュすることがある。
実行環境は、メモリが16GBでCPUが Core i5 10600 (3.3GHz) 6 コア 12 Thread.
前回のWGANがRTX A2000だと無理だったので、最初からあきらめてCPUでの実行とした。
最初は、動かすための前記変更だけを行ったサンプルコードの場合。
全部で2000epoch のうち、500epochごとの進捗がこちら. おなじlatent空間の点からlabelだけ変えて生成した画像を並べている。
501/2000
1001/2000
1501/2000
1991/2000
そして、学習完了後に生成画像がこちら。なお、latent空間の点はお互いにばらばら。
金髪か否かで生成し分けているのだが、どうだろう。 言われればそうかもしれないが、よくわからない。そもそも、顔イメージそのものが学習しきれていないように思うがどうだろう。
ちなみに、学習にかかった時間は120分30秒
まず試したのがcriticの回数をepockあたり3回から5回に増やすこと。
501/2000
1001/2000
1501/2000
1981/2000
Generate imagesの結果
所要時間 3時間6分 (186分)
次に、criticをepockあたり5回で、さらにepochの回数を倍の4000にした。
1001/4000
2001/4000
3001/4000
3951/4000
Generate imagesの結果
所要時間 6時間12分(372分)
ばらばらのlaten vectorから作った画像を並べた Generate images の結果だと分かりにくいが、同じlatent vectorからlabelだけ変えて作った画像を並べた3951epochでの画像をみると、Blond Hair という属性を学習して画像を作り分けられるようになったと言えるだろう。
CGANサンプルの実行にはかなり時間がかかりしんどかった。学習に費やされる時間が長かったのはもちろんだが、エラー終了してしまって無駄になった時間がさらに長かった。延々とCPUを走らせて、そろそろ終わりかなというところブラウザがクラッシュとかなると、ちょっと辛い。
いろいろと試すには大容量VRAMを搭載したGPUが必須かな...
24GBを積んだP40ならヤフオクでも3万円で出品されているけれど、パッシブ冷却だからパワフルな送風ファンが必須。AI実験用のサブPCは、古いタワーなので 送風ファンのスペースが足りなくてP40は使えない。メインPCは、そのつもりで買った大型ケースなので送風ファンごと収まるけれど、AIの実験でメインPCが長い時間使えなくなるのが不便。それが理由でAI実験環境にサブPCに移したのだからなぁ。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] https://github.com/davidADSP/Generative_Deep_Learning_2nd_Edition




















 ちなみにPC環境は、
第10世代 core i5 10600 (6コア 12スレッド)
メモリ 16GB
GPU: NVIDIA RTX A2000
OS: Ubuntu 22.04.3 LTS
2nd Edition の邦訳はまだない。英語版はAmazon.co.jp で kindle版も購入可能。 また、eBooks.comからだとPDFやEPUB形式で購入できるようだ。
なお初版は、生成 Deep Learning [2] というタイトルで邦訳が出ているが、サンプルが腐っているのでお勧めできない。そう、初版と2nd EditionではGithubにあるサンプルも全く別物で、初版の方はすでにサポート終了と宣言されている。おそらく、kerasの仕様変更が原因だと思うが03_03_vae_digits_train.ipynbなどがエラーになってしまう。
そんな訳で私は2nd editionを買いなおした。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] 生成 Deep Learning, David Foster著 松田 晃一, 小沼千絵 訳、オライリー・ジャパン ISBN978-4-87311-920-5
ちなみにPC環境は、
第10世代 core i5 10600 (6コア 12スレッド)
メモリ 16GB
GPU: NVIDIA RTX A2000
OS: Ubuntu 22.04.3 LTS
2nd Edition の邦訳はまだない。英語版はAmazon.co.jp で kindle版も購入可能。 また、eBooks.comからだとPDFやEPUB形式で購入できるようだ。
なお初版は、生成 Deep Learning [2] というタイトルで邦訳が出ているが、サンプルが腐っているのでお勧めできない。そう、初版と2nd EditionではGithubにあるサンプルも全く別物で、初版の方はすでにサポート終了と宣言されている。おそらく、kerasの仕様変更が原因だと思うが03_03_vae_digits_train.ipynbなどがエラーになってしまう。
そんな訳で私は2nd editionを買いなおした。
[1] Generative Deep Learning, 2nd Edition by David Foster, Released May 2023, Publisher: O'Reilly Media, Inc. ISBN: 9781098134181
[2] 生成 Deep Learning, David Foster著 松田 晃一, 小沼千絵 訳、オライリー・ジャパン ISBN978-4-87311-920-5




