








時系列の変化検知手段としての特異スペクトル変換法とやらを試してみる。
おおざっぱに言うと、過去のサンプルの塊と現在のサンプルの塊のそれぞれから、特異値分解による特徴的なパターンを抽出して、過去のそれと現在のそれとの相違を見ようというもの。
まずは、特異値分解を試してみる。
データとしては 1010101 という反復信号を例にとる。窓幅Mを3にとって部分時系列を取得する
例えば、N=4 の部分時系列を取得すると、例えば、[1,0,1], [0 1 0], [1,0,1][, [0,1,0] となる。
これを、フォンミーゼス・フィッシャー分布で扱うためベクトルの長さを 1に規格化すれば、
[0.707, 0, 0.707], [0, 1, 0], [0.707, 0, 0.707], [0, 1, 0] となる。
numpy.linalg.svd で試してみよう。SVDで Xは、部分時系列が列方向なので、ここでは部分時系列を行にして作った配列を転置させて生成する。
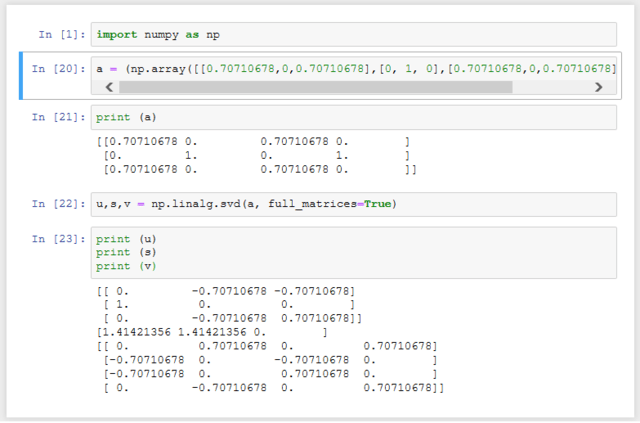
s の最初の2項目が 1.4 なので u の 1列目と2列目が特徴的なパターンということになる。
[0, 1, 0] と [-0.707, 0, -0.707] で符号は別とすれば、確かに特徴的なパターンということになる。
[1] 井出 剛、杉山 将, 異常検知と変化検知, 講談社, 2017 ISBN978-4-06-152908-3
おおざっぱに言うと、過去のサンプルの塊と現在のサンプルの塊のそれぞれから、特異値分解による特徴的なパターンを抽出して、過去のそれと現在のそれとの相違を見ようというもの。
まずは、特異値分解を試してみる。
データとしては 1010101 という反復信号を例にとる。窓幅Mを3にとって部分時系列を取得する
例えば、N=4 の部分時系列を取得すると、例えば、[1,0,1], [0 1 0], [1,0,1][, [0,1,0] となる。
これを、フォンミーゼス・フィッシャー分布で扱うためベクトルの長さを 1に規格化すれば、
[0.707, 0, 0.707], [0, 1, 0], [0.707, 0, 0.707], [0, 1, 0] となる。
numpy.linalg.svd で試してみよう。SVDで Xは、部分時系列が列方向なので、ここでは部分時系列を行にして作った配列を転置させて生成する。
s の最初の2項目が 1.4 なので u の 1列目と2列目が特徴的なパターンということになる。
[0, 1, 0] と [-0.707, 0, -0.707] で符号は別とすれば、確かに特徴的なパターンということになる。
[1] 井出 剛、杉山 将, 異常検知と変化検知, 講談社, 2017 ISBN978-4-06-152908-3




