








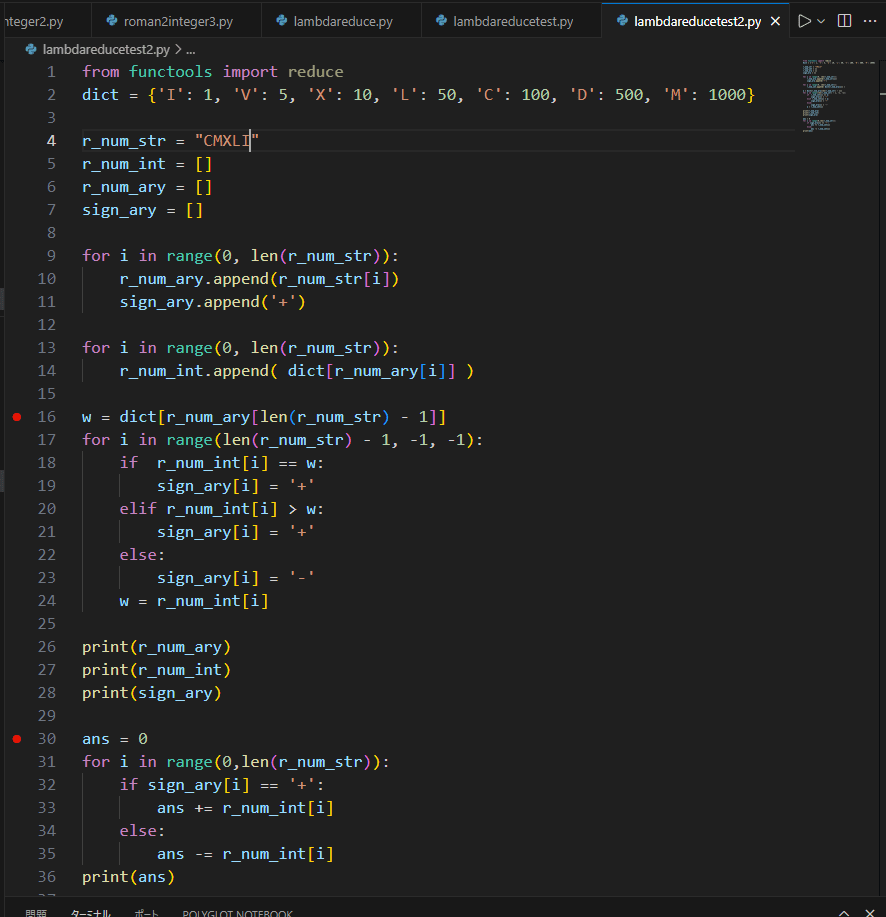

出力を見てもらえば、やっていることが分かると思います。
r_num_strは問題の文字列。
r_num_aryは問題の文字列を文字として、リストにします。
r_num_intは上のリストを数値の配列に置き換えます。
sign_aryはその数値が加算なのか?減算なのか?調べます。
簡単に言えば、数値のリストを右端から見ていって、左隣が同じか大きい場合は加算。
多分初期値の一番右端は、加算で間違いないと思います。
小さい場合は、減算。16行から24行がその部分で、肝です。
Dive into Python3ではローマ数字の妥当性もチェックしてますが、正規表現が自分にはディフィカルトです。(笑)
昨日、ドジャース対レンジャース見たんですが、山本由伸選手、浮足立ってました。
1イニング5失点でマウンドから降りました。コントロールも出来ていなかったし、甘い球は
ホームランは無かったですが、ボコボコでした。次回は修正して、抑えてほしいですね。
最後まで見ませんでしたが、5失点がのしかかり、ドジャースは負けたでしょう。
大谷翔平も試合後は無口で、LAへ向かったようです。

















reduceはリストの計算に使った例が、結構あるのですが、違う使用方法もあるんですね。
了解です。
まずreduceの特性の一つですが、必ずしもアキュムレーションに限りません。
通常の使い方の場合、例えば良くある例で、
>>> reduce(lambda x, y: x + y, [1, 2, 3, 4, 5], 0)
15
なんてのがあるけど、この返り値15が成立するのはx + yでアキュムレータに加算していってるから、ですよね。
一方、初期値に対して「何もしない」事も出来る。
>>> reduce(lambda x, y: y, [1, 2, 3, 4, 5], 0)
5
これはアキュムレータ(x)側の値をyですげ替えて行ってるだけ、です。だから最後の5が残る。
これを使う。
まず本体のこの部分
reduce(lambda x, y: (dic[y] + x[0] - (2 * x[1] if dic[y] > x[1] else 0), dic[y]), str, (0, 0))
に着目します。ラムダ式内のゴチャゴチャは放っといて、ここだけ見ます。
reduce(..., (0, 0))
つまり、アキュムレータの初期値を(0, 0)と言うタプルにしてる。単に「情報が2つ必要だ」と言う事と、タプルがイミュータブルだから、です。タプルは破壊的変更が出来ない、んでこれを使う。もちろんリストを使っても可、ですが「明解性」を示す為にこうしてます。
要は上で書いた通り、実は「アキュムレート」目的じゃなくって「挿げ替え」目的だから、です。
タプルの左側は計算結果、なんだけど、右側は「現時点でのdic[y]の情報保持の為、です。
それはこういう事だ。次の2つのローマ数字を考える。
IV -> 4 VI -> 6
文字列を処理する際に、左側から処理していきますが、使ってる文字の並びが違うと結果が違う。左側の文字が示す数が次に来る数より「大きい」か「小さい」かで処理が変わりますよね?
前者は5 - 1、後者は5 + 1で計算する。しかし、右側の処理をする際に「左側の情報」を保持しとかなきゃなんない。そのためのタプルの第一要素、なんです。
(現在の計算結果、 前回の文字が意味する数値)
で、ラムダ式の中身は基本的には
lambda x, y: (dic[y] + x[0], dic[y])
でイイはずなんだけど、結果、タプルの第一要素が現在処理してるdic[y]より大きいか小さいか、で処理を分けないとならない。
dic[y]がアキュムレータの第一要素(前回の文字が示す数値)より大きい場合:
返り値: (dic[y] + x[0] - 2 * x[1] , dic[y])
それ以外:
返り値: (dic[y] + x[0], dic[y])
例えば前者だと
IV -> x[0]は1になってる -> 1 + 5 = 6だが、2 * x[0]を引くと6 - 2 * 1 -> 6 - 2 = 4で計算終了。
後者だと
VI -> x[0]は5になってる。 5 + 1 = 6で計算終了。
となる。繰り返すと、前回処理した数値が今回処理する数値より小さな場合は、
今回処理する値 + 前回までの計算結果 - 2 * 前回処理した値
で計算出来る、と。そうじゃなければ単に加算すればいい、と。
結果、エンジン的には、
def foo(str):
return reduce(lambda x, y: (dic[y] + x[0] - (2 * x[1] if dic[y] > x[1] else 0), dic[y]), str, (0, 0))
これでいい。ただし、これだとタプルが返っちゃうんです。
>>> foo("CMXLI")
(941, 1)
だから返り値は、エンジン部分が返すタプルの第0要素だけ返す事で成り立たせる。
def foo(str):
return reduce(lambda x, y: (dic[y] + x[0] - (2 * x[1] if dic[y] > x[1] else 0), dic[y]), str, (0, 0))[0]
だから最後に[0]を付けてるわけです。
なお、Lispと違って、Pythonのreduceの第二引数はシーケンスを取ります。文字列もシーケンスなんで、リスト同様に扱えて、「文字列をリストに変換する」必要はありません。
普通の構文にも出来るはず、と思ったんですが、予想以上に複雑で、一日やっても一歩も進みません。(笑)
from functools import reduce
dic = {'I' : 1, 'V' : 5, 'X' : 10, 'L' : 50, 'C' : 100, 'D' : 500, 'M' : 1000}
def foo(str):
return reduce(lambda x, y: (dic[y] + x[0] - (2 * x[1] if dic[y] > x[1] else 0), dic[y]), str, (0, 0))[0]