









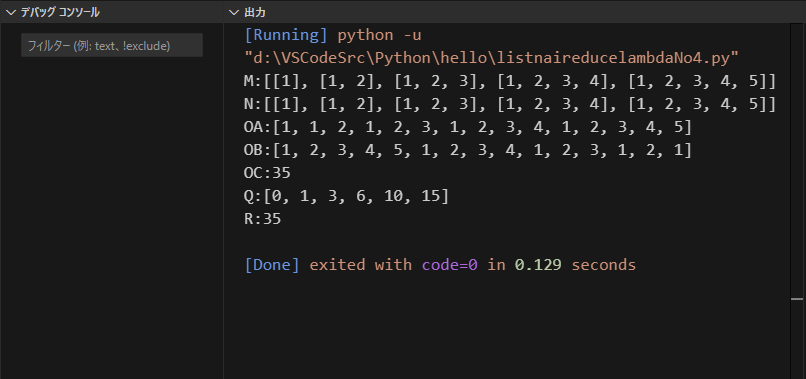
出力のMとNを見ると、結果は同じです。
配列(pythonではリスト)の配列です。自分的には、関数型から程遠い
Mがシックリきますけど。
しかし、Nでもforを使ってます。
Cametanさんによれば、誤解がないとして、forがある場面では
reduceが使えるか?考える、でしたが、もしかしたら、違うかも知れません。
今までの例を見ると、lambda x, y: y + [y(-1) + x], [ 1,2,3,4,5]が
配列の配列を作っている部分と思われます。が、その部分だけ切り取って
print出来ない。配列の配列が出来ていることの、確認です。それが出来ない。
もしかしたら、配列の配列は出来ていないのかも知れませんね?
数字の並びだけは同じですけど。

















これはリスト内包表記二重掛けにすべきでしょう。
>>> [[j for j in range(1, i + 1)] for i in range(1, 6)]
[[1], [1, 2], [1, 2, 3], [1, 2, 3, 4], [1, 2, 3, 4, 5]]
>>>
> 配列の配列を作っている部分と思われます
いや、違うでしょ。
> lambda y, x: y + [y[-1] + x]
と言うコールバック関数は単に配列を作ってるだけ、えす。
y -> 配列
[y[-1] + x] -> 配列
配列 + 配列はオーバーライドにより単に配列になります。配列と配列を単にappendしてるだけですね、ここは。
まだよくわからないのが、lambda式の部分です。まえに単純な+の場合、(((1+2)+3)+4)みたいな、と展開される、が有りました。
それを適用したら?どうなると悩んでます?
[1,2,3,4,5]は一度通過するだけですか?
reduce(lambda y, x: y + [y[-1] + x], [1, 2, 3, 4, 5], [0])
STEP1:
x => 1, y => [0]なので
y + [y[-1] + x] => [0] + [0 + 1] => [0] + [1] => [0, 1]
STEP2:
x => 2, y => [0, 1]なので
y + [y[-1] + x] => [0, 1] + [1 + 2] => [0, 1] + [3] => [0, 1, 3]
STEP3:
x => 3, y => [0, 1, 3]なので
y + [y[-1] + x] => [0, 1, 3] + [3 + 3] => [0, 1, 3] + [6] => [0, 1, 3, 6]
STEP4:
x => 4, y => [0, 1, 3, 6]なので
y + [y[-1] + x] => [0, 1, 3, 6] + [6 + 4] => [0, 1, 3, 6] + [10] => [0, 1, 3, 6, 10]
STEP5:
x => 4, y => [0, 1, 3, 6, 10]なので
y + [y[-1] + x] => [0, 1, 3, 6, 10] + [10 + 5] => [0, 1, 3, 6, 10] + [15] => [0, 1, 3, 6, 10, 15]
終了、と。
yは「初期値」または「前回の計算結果」、xは[1, 2, 3, 4, 5]から要素を順繰りに引っこ抜いてきています。
yは「前回の計算結果(リスト)」で、y[-1]は「前回の計算結果(リスト)の最後の要素」です。
上のプロセス(STEP)を良く見てみて下さい。
全部、コールバック関数(ラムダ式)が指定した通りに計算が行われています。