









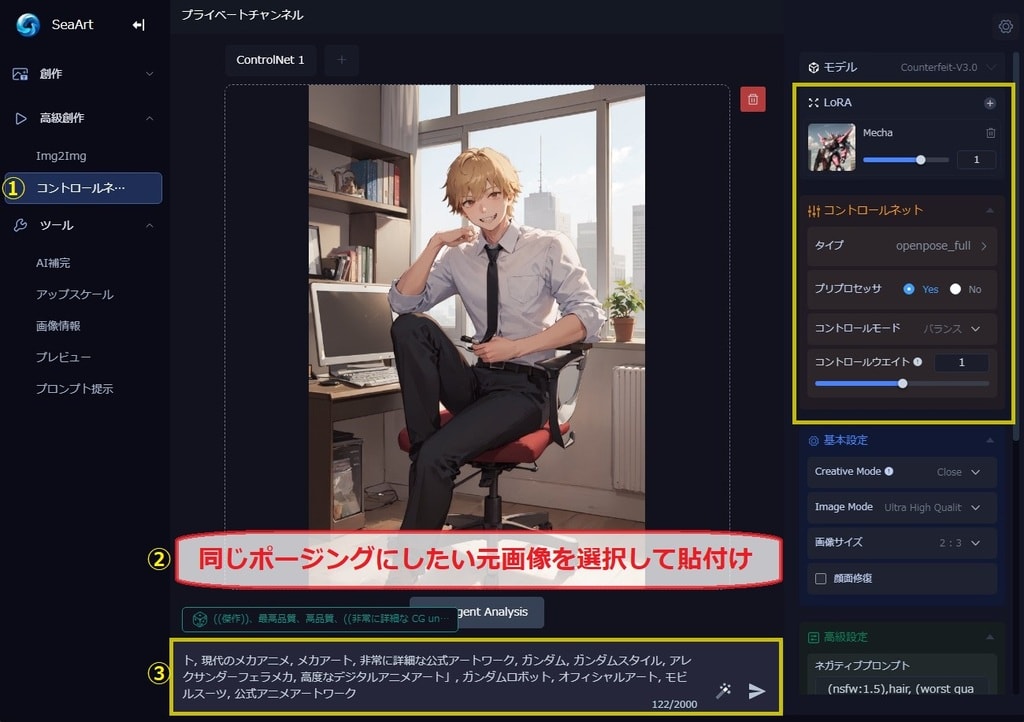
今回は、お題のとおりSeaArtの高級創作(拡張機能)のひとつ「コントロールネット」を使って指定したポーズで画像生成させる試みです。
まずは、同じポーズで描きたい元画像を用意します。

このポーズを真似て画像生成をしてみます。
SeaArtのAI作成から
①コントロールネットを選択します。
②それぞれに特化したタイプを選択します。

今回はアップロードされたポースを参考にして生成するのでopenpose_full を選択します。
《参考:コントロールネットタイプ一覧》
- canny:アップロードされた画像を参考に、線の輪郭を抽出することで、元の画像の細部をより精確に残しつつ、精密な線画を描きます。
- openpose_full:アップロードされた人物画像を参考に、人物のポーズと動作を抽出し、元の画像と同じポーズの新しい画像を生成します。
- lineart :画像の線特徴を自動的に識別、抽出、再構成し、画像をアニメ風の線画に変換します。
- lineart_anime:画像の線特徴を自動的に識別、抽出、再構成し、画像をアニメ風の線画に変換します。また、アニメスタイルの効果を加えます。
- depth:アップロードされた人物や建物、あるいはシーンの画像の深度を推定し、テキストやその深度情報を用いて、構造と細部をより多く残しながら新しい画像を生成します。
- normal_bae:アップロードされた画像をモデリングスタイルの前処理画像に変換した後、新しい画像を生成します。人物モデリングや建物モデリングに適しています。
- segmentation:ユーザーから提供された画面の説明に基づいて、アップロードされた画像を自動で認識し、画面内の内容を異なる部分に分割し、示意図付きの分割結果を生成します。
- tile_resample:画像の詳細を調整し、解像度を向上させ、全体的な画像品質を劇的に向上させることができます。
- mlsd:ユーザーがアップロードした建築図、オブジェクト図、シーン図の線と輪郭を認識し、前処理画像を生成してから新しい画像を生成します。
- scribble_hed:アップロードされた画像または線画を着色し、落書き風の絵を生成します。人物の着色に適しています。
- hed_safe:アップロードされた画像の輪郭特徴を抽出・検知し、迅速かつ正確に認識し、高品質な線画を生成します。輪郭の保存と細部の復元でより優れた機能を発揮します。
- color_grid: AI が元の画像の色の特徴を自動的に認識、抽出、再構築し、新しいカラー グリッド アートワークを生成できます。
- shuffle:画像からさまざまな特徴情報を抽出し、ランダムに組み合わせ、調整することで、新しい画像を生成します。
- 参考生成:アップロードされた画像の人物、キャラクター、物品などを参考に、類似する新しい画像を生成します。
③プロンプトを入力しGenerateします。
今回は、ちょっと趣向を凝らし公開されているモデルを元にコントロールネットを利用してみました。
指定したポーズをさせてみたい元ネタ画像を用意します。

今回は、ガンダムのモデルがあったのでこのモデリングとプロンプトを参考にコントロールネットで上の画像の「足を組んだ状態」の再現を試みました。

プロンプトとネガティブプロンプトをコピーします。

モデルとプロンプト、ネガティブは、そのまま利用させて頂き作成できたのがこちらの画像です。ほぼ意図通りの画像が生成できました。

プロンプトとモデルを変えるだけで、自由に画像が生成出来てしまいます。
今回は、試していませんが簡単な骨格(棒人間)を描くだけでも同じポーズで生成してくれるそうなので、次回は。自分で創作したポーズで描いてみようと思います。










※コメント投稿者のブログIDはブログ作成者のみに通知されます