








「データセットについてのメモ」の中で,table 関数を使うたびに分析で使う変数と ケースの subset を作っている。
少なくとも,変数の subset を毎回作る必要はない。
また,3次元以上の集計表を第3次元ごとに繰り返している。
で、35歳で層別化して出産回数と人工流産回数を見たい場合は、こんな感じでしょうか?
> table(subset(x,subset=age=="<35",select=c(parity, induced)))
induced
parity 0 1 more
1 52 17 0
>1 40 33 26
> table(subset(x,subset=age!="<35",select=c(parity, induced)))
induced
parity 0 1 more
1 24 6 0
>1 27 12 11
これは,xtabs 関数を使うと,何の苦もなく一発で結果が出る。x は既に作成されているデータフレーム。
> xtabs(~parity+induced+age, x)
, , age = <35
induced
parity 0 1 more
1 52 17 0
>1 40 33 26
, , age = >=35
induced
parity 0 1 more
1 24 6 0
>1 27 12 11


「data.frameのrbindにはみんな苦労しているようだ」で紹介されている関数
以下のように作ると,コンパクトにまとまった
rbind3 <- function(lst) {
nr <- sapply(lst, nrow)
end <- cumsum(nr)
start <- c(0, end[-length(lst)])+1
names <- unique(c(sapply(lst, colnames)))
result <- as.data.frame(matrix(NA, sum(nr), length(names)))
colnames(result) <- names
mapply (function(d, s, e) result[s:e, names %in% colnames(d)] <<- d, lst, start, end)
return(result)
}
実行例
> x <- data.frame(A=1:5, B=5:1, row.names=1:5)
> y <- data.frame(B=1:5, C=5:9, row.names=1:5)
> z <- data.frame(C=3:8, A=8:13, row.names=2:7)
> rbind3(list(x, y, z))
A B C
1 1 5 NA
2 2 4 NA
3 3 3 NA
4 4 2 NA
5 5 1 NA
6 NA 1 5
7 NA 2 6
8 NA 3 7
9 NA 4 8
10 NA 5 9
11 3 NA 8
12 4 NA 9
13 5 NA 10
14 6 NA 11
15 7 NA 12
16 8 NA 13
「推計学のすすめ」メモ 3.1 ゴルファーの腕比べの話 ―平均値の差の検定― (符号検定とt検定) でちょっと誤解が
>「対応がある」だとか「等分散である」といったパラメータを設定して行う検定はパラメトリックな方法と呼ばれる。一方、これらを設定しないで行う検定はノンパラメトリックな検定と呼ばれる。
パラメーター(母数)とは,母平均や母分散など,母分布の性状を表すものである
> Rのt検定においてノンパラメトリック手法がデフォルトになっているのもパラメトリックな検定を適用できる範囲が実際はかなり限定されるという背景あっての事だろう。
筆者は,t.test 関数のデフォルトである Welch の方法を「ノンパラメトリック手法」といっているわけで,明らかにおかしい。
> というわけなので私は大丈夫です。
というわけなので,ちょっと統計学の復習が必要でしょう。
> 誰にもわからないかどうかもわからないので少し他の人の回答まってみます。
> いろいろあるみたいです。たとえば、札幌R勉強会とかあるみたいですが、情報ご存知のかた、教えてください。
この質問者は,ほかにもかなりとんちんかんな投稿をしている。
無視するのがよいのかなあ
> 非常に面倒かどうかを知りたいのです。
他の質問内容から見ると,あなたにとっては「非常に面倒」なんでしょうねえ。残念!!
「Rコードの最適化例:混合正規乱数の発生コード」 にあるんだが,なんだかなあ
結局 N1 に従う乱数の個数 n1 が決まれば良いと喝破(なるほど)
rmixnorm3 <- function(n, p1, N1, N2) {
n1 <- sum(runif(n) < p1)
c( N1[2]*rnorm(n1) + N1[1], N2[2]*rnorm(n-n1)+N2[1] )
}
rmixnorm4 <- function(n, p1, N1, N2) {
n1 <- sum(runif(n) < p1)
c( rnorm(n1, m=N1[1], s=N1[2]), rnorm(n-n1, m=N2[1], s=N2[2]) )
}
何が喝破か。
「確率 0.6 で混合」と書いてあるのに,何が悲しくて「その個数を決める」のに,sum(runif(n) < p1) なんかやるの!!
n*p1 でよいでしょうが(必要なら整数に丸めないといけないけど)。ということで,rmixnorm5 を定義して,ベンチマーク。
rmixnorm5 <- function(n, p1, N1, N2) {
n1 <- round(n*p1)
c( rnorm(n1, m=N1[1], s=N1[2]), rnorm(n-n1, m=N2[1], s=N2[2]) )
}
library(rbenchmark)
benchmark(rmixnorm(1e6, 0.4, c(-1,1), c(3,2)), rmixnorm2(1e6, 0.4, c(-1,1), c(3,2)), rmixnorm3(1e6, 0.4, c(-1,1), c(3,2)), rmixnorm4(1e6, 0.4, c(-1,1), c(3,2)), rmixnorm5(1e6, 0.4, c(-1,1), c(3,2)), replications=100)
test replications elapsed relative user.self sys.self
1 rmixnorm(1e+06, 0.4, c(-1, 1), c(3, 2)) 100 19.705 2.039644 17.734 2.418
2 rmixnorm2(1e+06, 0.4, c(-1, 1), c(3, 2)) 100 22.562 2.335369 20.642 2.233
3 rmixnorm3(1e+06, 0.4, c(-1, 1), c(3, 2)) 100 13.959 1.444881 13.148 0.945
4 rmixnorm4(1e+06, 0.4, c(-1, 1), c(3, 2)) 100 13.103 1.356278 12.720 0.467
5 rmixnorm5(1e+06, 0.4, c(-1, 1), c(3, 2)) 100 9.661 1.000000 9.333 0.392
当然,速いに決まっているわ~な(^_^)
これも同じく,本家 Rjpwiki の「Rコード最適化のコツと実例集」にあるのだけど。。。みんな~,騙されるんじゃないぞ~!
> 永続付値(他の環境中の変数への付値)は手間がかかる。遠くの x よりも近くの x
>
> > test1 <- function(){x <- runif(10000)} # 自前の環境中の x へ代入
> > test2 <- function(){x <<- runif(10000)} # 親環境中の x へ代入
> > rm(x); c = 0; for(i in 1:100) c <- c + system.time(test1()); c/100
> [1] 0.0015 0.0000 0.0020 0.0000 0.0000
> > x
> Error: Object "x" not found # 変数 x は関数終了時に消える
> > x <- numeric(10000); c = 0; for(i in 1:100) c <- c + system.time(test2()); c/100
> [1] 0.0018 0.0000 0.0021 0.0000 0.0000
> > x[1:5] # 当然 x は存在
> [1] 0.02132324 0.36266310 0.50504673 0.89662908 0.67079898
> [1] 0.48 0.03 0.50 0.00 0.00
はいはい。やってみましょうね~~。
> test1 <- function() {x <- runif(1000000)} # 自前の環境中の x へ代入
> test2 <- function() {x <<- runif(1000000)} # 親環境中の x へ代入
> library(rbenchmark)
> benchmark(test1(), test2(), replications=1000)
test replications elapsed relative user.self sys.self user.child sys.child
1 test1() 1000 28.783 1.000000 27.833 1.282 0 0
2 test2() 1000 29.294 1.017754 28.239 1.256 0 0
どれでも同じ。遠いってどういうこと?
使いたい機能,使わなければならない機能は,何の遠慮もなく使うがよいゾッ!
よって,この珍説もガセと認定!!
これも同じく,本家 Rjpwiki の「Rコード最適化のコツと実例集」にあるのだけど。。。みんな~,騙されるんじゃあね~ぞ~!
> 既存変数を再利用(変数の構造・サイズが変わる場合はどうかはわかりません)。環境にやさしい資源リサイクル
>
> > test1 <- function() {x <- runif(1000000); y <- x^2} # 変数 y は無駄
> > system.time(test1())
> [1] 0.62 0.04 0.67 0.00 0.00
> > test2 <- function() {x <- runif(1000000); x <- x^2} # 変数 x を再利用
> > system.time(test2())
> [1] 0.48 0.03 0.50 0.00 0.00
この場合は,そもそも代入する必要がないのだから,以下も含めてベンチマーク・テストしてみよう
test3 <- function() {x <- runif(1000000); x^2}
> library(rbenchmark)
> benchmark(test1(), test2(), test3(), replications=1000)
test replications elapsed relative user.self sys.self user.child sys.child
1 test1() 1000 37.084 1.000000 30.681 6.671 0 0
2 test2() 1000 37.149 1.001753 30.557 6.778 0 0
3 test3() 1000 37.144 1.001618 30.558 6.804 0 0
どれでも同じ。「資源はたくさんある」ので,たかが 1000000 個の要素を持つ numeric 変数を新たに使っても,R にとっては痛くもかゆくもない。
よって,この珍説もガセと認定!!
本家 Rjpwiki の「Rコード最適化のコツと実例集」にあるのだけど。。。みんな~,騙されるんじゃないぞ~!
> 変数初期化のコツ。同一のベクトル、配列変数を全要素 0 で繰返し初期化する(良くあること)場合、既存の同じサイズの変数に 0 を掛ければ済む。x-x でも同じこと(少し早くなるとのコメント)。全要素 1 で初期化したければ、0*x + 1 とする。0 は無ならず
> 確かに,y <- 0*x は速いですね。y <- x-x の方がもう少しだけ速いようです。 -- 2004-06-23 (水) 10:41:05
> 1で初期化する場合は0*x+1よりx^0が高速。さらに論理値で良ければx==xがもっと高速 -- aaa? 2009-05-01 (金) 06:31:21
ガセ 全部,ウソッパチ
> x <- runif(100000000)
> gc();gc();system.time(y <- 0*x)
ユーザ システム 経過
0.223 0.216 0.437
> gc();gc();system.time(y <- x-x) # 0*x より速くなることもない
ユーザ システム 経過
0.229 0.220 0.447
奇をてらう必要はない。素直にやるのが一番速い。 <-- 四則演算も結構高くつく
> gc();gc();system.time(y <- numeric(length(x)))
ユーザ システム 経過
0.117 0.223 0.338
===============================================
> gc();gc();system.time(y <- 0*x+1)
ユーザ システム 経過
0.477 0.433 0.906
> gc();gc();system.time(y <- x^0) # 全然,速くない
ユーザ システム 経過
0.613 0.216 0.825
> gc();gc();system.time(y <- x==x) # 全然,速くない
ユーザ システム 経過
0.629 0.112 0.739
奇をてらう必要はない。素直にやるのが一番速い。
> gc();gc();system.time(y <- numeric(length(x))+1)
ユーザ システム 経過
0.370 0.443 0.809
昔は本当だったトリビアも,今ではガセになりはてているものもある。
マシンやコンパイラの違いによることもあるけど。
それにしても,毎度いうことだが,これだけの計算量で違いは1秒にも満たないのだから,あれこれ小細工を弄する必要は全くないと言っていいだろう。
> x <- runif(100000000)
> y <- runif(100000000)
> z <- runif(100000000)
> ## 最初のものより二番目の方が速い
> # 割り算2つよりは掛け算と割り算一つずつが得
> system.time(x/y/z)
ユーザ システム 経過
1.719 0.420 2.129
> system.time(x/(y*z))
ユーザ システム 経過
1.116 0.423 1.533
> # べき乗は高くつく
> system.time(1.1*x^3+2.2*x^2+3.3*x+4.4)
ユーザ システム 経過
5.338 1.964 7.270
> system.time(((1.1*x+2.2)*x+3.3)*x+4.4)
ユーザ システム 経過
1.442 1.437 2.863
> # べき乗は高くつく
> system.time(x^3+2*x^2+3*x+4)
ユーザ システム 経過
5.014 1.666 6.649
> system.time(((x+2)*x+3)*x+4)
ユーザ システム 経過
1.209 1.197 2.393
> # べき乗は高くつく
> system.time(x^y)
ユーザ システム 経過
8.824 0.229 9.018
> system.time(exp(y*log(x)))
ユーザ システム 経過
3.492 0.647 4.120
> # 前もって定数 log(10) を計算しておいても何の得もない
> system.time(10^y)
ユーザ システム 経過
9.068 0.220 9.253
> system.time(exp(y*log(10)))
ユーザ システム 経過
1.671 0.426 2.087
> system.time({a <- log(10); exp(y*a)})
ユーザ システム 経過
1.670 0.425 2.085
いくつかの場合について実測してみた
> y <- runif(100000000)
> # 2倍するのと足し算の差はない
> system.time(2*y)
ユーザ システム 経過
0.458 0.594 1.054
> system.time(y+y)
ユーザ システム 経過
0.435 0.551 0.979
> # 2乗と掛け算の差はない
> system.time(y^2)
ユーザ システム 経過
0.443 0.535 0.971
> system.time(y*y)
ユーザ システム 経過
0.438 0.528 0.958
> # 3乗と2回の掛け算なら,2回の掛け算の方が速い
> system.time(y^3)
ユーザ システム 経過
4.084 0.549 4.611
> system.time(y*y*y)
ユーザ システム 経過
1.228 1.245 10.646
> # 2進数で正確に表せる数ならば,割り算も掛け算も差はない
> system.time(y/4)
ユーザ システム 経過
0.448 0.533 0.972
> system.time(y*0.25)
ユーザ システム 経過
0.442 0.527 0.961
> # 2進数で正確に表せない数ならば,掛け算の方が速い
> system.time(y/10)
ユーザ システム 経過
1.024 0.516 1.529
> system.time(y*0.1)
ユーザ システム 経過
0.442 0.524 0.958
> # 1/2乗と sqrt 関数では,sqrt の方が速い
> system.time(y^0.5)
ユーザ システム 経過
1.234 0.509 1.731
> system.time(sqrt(y))
ユーザ システム 経過
0.978 0.512 1.479
> # 整数倍と実数倍では,実数倍の方が速い
> system.time(123L*y)
ユーザ システム 経過
0.560 0.516 1.068
> system.time(123*y)
ユーザ システム 経過
0.441 0.536 0.968
> # でもねえ,100000000 回の演算でこれだけしか違わないのだから,どっちでもよい
どこぞにやらあるプログラム。プログラムの最適化(高速度化)を目指した結果の報告。
num_steps <- 10000000
step <- 1.0 / num_steps
summ <- 0
for (i in 1:num_steps) {
x <- (i-0.5) * step
summ <- summ + 4.0 / (1.0 + x * x)
}
PI <- step * summ
print(PI)
が遅いので,次のようにしたら,驚異的に速かった。分散処理なんかよりも速かったとのこと。
そうでしょう。そうでしょう。
num_steps <- 1:10000000
step <- 1.0 / 10000000
x <- (num_steps-0.5) * step
PI <- sum((4.0 / (1.0 + x * x)) * step)
print(PI)
でもちょっと,見落としているところがあった。
num_steps <- 1:10000000
step <- 1.0 / 10000000
x <- (num_steps-0.5) * step
PI <- sum(4.0 / (1.0 + x * x)) * step
print(PI)
のようにすると,25%速くなる。
sum((4.0 / (1.0 + x * x)) * step) では,* step は全要素について計算している。しかし,定数計算なので,sum した結果に 1 度だけ掛ければよいというのは,よくいわれること。
ちなみに x * x は x ^2 より速いだろうという思い込みであろうが,R においては x * x と x ^ 2 では,実行速度の差はない。より直感的で分かりやすい書き方をする方がよい。
また,余分な括弧や,実数値に .0 を付けるというのも,他の言語の仕様を引きずっているなあ。R では,小数点のつかない数も実数である(逆に,整数であるときに 3L のように接尾辞 L を付けなくてはならないが)。よぶんなプログラム要素があると,プログラムを読む妨げになる。
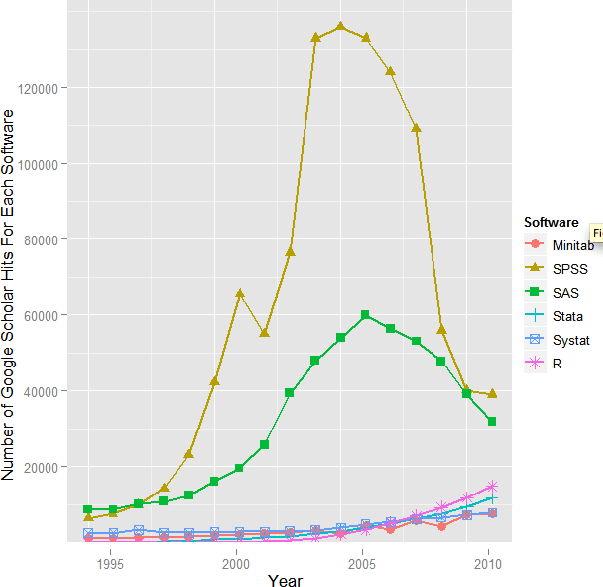
http://r4stats.com/2012/05/09/beginning-of-the-end/ にあるグラフ。
何となく受けのよい ggplot によるもので,R をひいきする身としては好ましいグラフかも知れないが,統計グラフとしてみればとても合格点の付けられるようなものではない。
ggplot のデフォルトで,グラフのバックグラウンドが薄い灰色,グリッド線が白ということが原因だが,どこに y = 0 の軸があるか見にくくなっている。せめて,目盛り数値 0 でも描かれていると注意するのだろうが,それもない。特に 右の方で y = 0 より下の部分が下駄履きになっており,R が実際より大きなものに見えてしまう。この部分を除いたものを添付するので,比較してみるとよい。(ggplot は使いたくないので,お絵かきソフトでその部分をカットしたものを使う)
また,科学にお化粧はいらない。最後に,素の R で描いたグラフを示しておく。これが一番明確。
★ バックグラウンドが灰色などとは不適切きわまりない。
★ グラフにグリッド線などは不要。
★ height が width より異様に大きいのもデータの誇張に一役買っているようだ。


どこぞやらにあるプログラム。指数分布とポアソン分布の関係を示そうとするシミュレーション・プログラムだ。
毎回1個ずつ乱数を発生させるのはもったいない。かといって,毎回何個発生させるのがベストなのか。取りあえずほどほどの個数を発生させておいて,足りなければ追加する。まとめて発生させるメリットと,いろいろな余分な操作のデメリットのせめぎ合いで,良さそうな所を見付ける。
オリジナルはこんな感じのプログラム
VisitorCounter <- function(lambda)
{
counter <- 0
time.arrival <- rexp(1, rate = lambda)
while (time.arrival < 1) {
counter <- counter + 1
time.arrival <- time.arrival + rexp(1, rate = lambda)
}
return(counter)
}
lambda <- 5
N <- 10^5
x <- sapply(1:N, function(i) {VisitorCounter(lambda)})
barplot(rbind(table(x)/N, dpois(0:max(x), lambda)),
col = c("violetred1", "slateblue4"),
legend.text = c("Simulation", "Theoretical"),
args.legend = list(x = "topright"),
beside = TRUE)
書き換えると 5 倍弱の速さのプログラムになる
VisitorCounter2 <- function(N, lambda)
{
result <- integer(N)
repo <- matrix(rexp(15*N, rate = lambda), ncol=N)
colsum <- colSums(repo)
for (i in 1:N) {
x <- repo[, i]
if (colsum[i] < 1) {
repeat {
x <- c(x, rexp(10, rate = lambda))
if (sum(x) > 1) break
}
}
result[i] <- sum(cumsum(x) <= 1)
}
return(result)
}
lambda <- 5
N <- 10^5
x <- VisitorCounter2(N, lambda)
barplot(rbind(table(factor(x, levels=0:max(x)))/N, dpois(0:max(x), lambda)),
col = c("violetred1", "slateblue4"),
legend.text = c("Simulation", "Theoretical"),
args.legend = list(x = "topright"),
beside = TRUE)
だいぶ前に見つけて,忘れてしまっていたのを再発見したので記録。
> x <- data.frame(a=sample(3, 100, rep=T), b=sample(2, 100, rep=T), c=sample(3, 100, rep=T))
> summary(xtabs(~., data=x))
Call: xtabs(formula = ~., data = x)
Number of cases in table: 100
Number of factors: 3
Test for independence of all factors:
Chisq = 11.541, df = 12, p-value = 0.4832
Chi-squared approximation may be incorrect
PVアクセスランキング にほんブログ村







