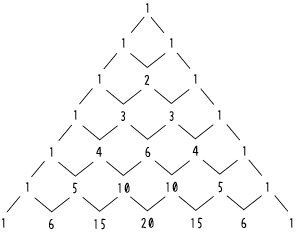
ぐるぐる曼荼羅
締め切りが 2018/02/25 10:00 AM なので,その 1 分後に投稿されるように予約
【概要】
下図のように、正の整数が全て並んでいます。
数をひとつ指定しますので、その数のマスの上下左右に隣接しているマスの数を、昇順にコンマ区切りで出力してください。
【入力】
入力は標準入力から来ます。
35
のように、普通に10進数です。
【出力】
入力で指定された数のマスの上下左右に隣接しているマスの数を、昇順にコンマ区切りで出力してください。
先ほどの入力の場合、
8,34,36,100,101
を出力すれば正解です。
【例】
入力が 35 のとき,出力は 8,34,36,100,101
入力が 43 のとき,出力は 11,42,44,119,120
【補足】
・ 不正な入力に対処する必要はありません。
・ 入力は、1以上 十兆(10000000000000)以下です。
==================================================
規則性を見つけ出すこと。
例えば,n = 35 の場合,n が含まれるレベルは小数部が 0 か 5,それより内側のレベルは小数部が 00, 25, 50, 75,外側のレベルは小数部なし(整数) とすれば,普通に配置できる(参照するときには,整数部のみを見ればよい)。
右下の隅に出てくる数(今の場合だと 7, 31, 91) は オンライン整数列大辞典の A068156 から導ける。
n が含まれるレベルにある数を x とすれば,内側のレベルに並んでいる数 z は z = x/2+定数1,外側のレベルに並んでいる数 y は y = x*2+定数2 の関係になっている。
n の前後は小数部が 0 の n-1 と n+1,外側に接するのは整数そのもの,内側に接するのは z の整数部。
ワークシートを使っても簡単に答えを出せる。
解答先の R がバグっているのか,n = 10000000000000 のときだけ,cat(sort(unique(ans)), sep=",") ではだめで,cat(paste(sort(unique(ans)), collapse=",")) だと通る。見た目は同じなのに。
別の処理系(実行くん)でやると,"4999999999769, 9999..." のように,カンマの後に(他のカンマの後にはないのに,ここだけ)不可解な空白が入っている。わけわからん...
f = function(n) {
ans = NULL
if (n < 14) {
a = matrix(c(49:40, 14, rep(13:10, each=2), 39, 15, rep(13:10, each=2), 38, 16,
2, 2, rep(1, 4), 9, 9, 37, 17, 2, 2, rep(1, 4), 9, 9, 36, 18,
3, 3, rep(1, 4), 8, 8, 35, 19, 3, 3, rep(1, 4), 8, 8, 34, 20,
rep(4:7, each=2), 33, 21, rep(4:7, each=2), 32, 22:31), byrow=TRUE, ncol=10)
index = which(a == n, arr.ind = TRUE)
for (k in 1:nrow(index)) {
i = index[k, 1]
j = index[k, 2]
ans = c(ans, a[i - 1, j], a[i + 1, j], a[i, j - 1], a[i, j + 1])
}
ans = ans[ans != n]
} else {
options(scipen = 100)
mx = 0:44
A068156 = 3 * 2 ^ mx + 0 ^ mx - 3
e4 = cumsum(A068156 * 4) - 3
e3 = e4 - A068156
e2 = e3 - A068156
e1 = e2 - A068156
b1 = b2 = b3 = b4 = e1
for (i in 3:length(e1)) {
b1[i - 1] = e4[i - 2] + 1
b2[i - 1] = e1[i - 1] + 1
b3[i - 1] = e2[i - 1] + 1
b4[i - 1] = e3[i - 1] + 1
}
lev = which(b1 <= n & n <= e4)
m = e1[lev]-b1[lev]+1
k = (n-b1[lev]) %/% m + 1
if (n == b1[lev]) {
ans = c(b1[lev]+1, e4[lev])
} else if (n == e4[lev]) {
ans = c(b1[lev], e4[lev]-1)
} else {
ans = c(n-1, n+1)
}
outer = 2*n+3*k+12*lev-15
ans = c(ans, outer, outer+1)
if (n %in% c(e1[lev], e2[lev], e3[lev])) {
ans = c(ans, outer+3:4)
} else if (n == e4[lev]) {
ans = c(ans, n+1:2)
}
if (! n %in% c(e1[lev], e2[lev], e3[lev])) {
if (n == b1[lev] || n == b1[lev]+1) {
ans = c(ans, b1[lev]-1)
} else {
odd = k %% 2 == 1
n2 = ifelse(odd == 1, n%/%2, (n-1)%/%2)
inner = n2 + 14 - 1.5*k - 6*lev- 0.5*odd
ans = c(ans, inner)
}
}
}
cat(sort(unique(ans)), sep=",")
}
#f(scan(file("stdin", "r")))
f(1) # 2,3,5,6,8,9,11,12
f(2) # 1 3 13 16 17
f(3) # 1 2 4 18 19
f(4) # 3 5 20 21 23 24
f(5) # 1 4 6 25 26
f(6) # 1 5 7 27 28
f(7) # 6 8 29 30 32 33
f(8) # 1 7 9 34 35
f(10) # 9 11 38 39 41 42
f(11) # 1 10 12 43 44
f(12) # 1 11 13 45 46
f(13) # 2 12 14 15 47 48
###
f(48) # 13 47 49 129 130
f(17) # 2 16 18 58 59
f(21) # 4 20 22 66 67
f(22) # 21 23 68 69 71 72
f(23) # 4 22 24 73 74
f(26) # 5 25 27 79 80
f(30) # 7 29 31 87 88
f(31) # 30 32 89 90 92 93
f(32) # 7 31 33 94 95
f(35) # 8 34 36 100 101
f(39) # 10 38 40 108 109
f(40) # 39 41 110 111 113 114
f(41) # 10 40 42 115 116
f(45) # 12 44 46 123 124
f(10000000000000) # 4999999999769,9999999999999,10000000000001,20000000000474,20000000000475
Python3 で書いてみたけど,くそったれ,だな。
処理系により indent が上手く扱えないとか,変なことが起きる。制御構文をインデントでという言語仕様は,百害あって一利なし。 { } でくくればいいじゃん。
Python で書くメリットは,全くない。
import numpy as np
def f(n):
ans = []
if n < 14:
a = np.array([
[49, 48, 47, 46, 45, 44, 43, 42, 41, 40],
[14, 13, 13, 12, 12, 11, 11, 10, 10, 39],
[15, 13, 13, 12, 12, 11, 11, 10, 10, 38],
[16, 2, 2, 1, 1, 1, 1, 9, 9, 37],
[17, 2, 2, 1, 1, 1, 1, 9, 9, 36],
[18, 3, 3, 1, 1, 1, 1, 8, 8, 35],
[19, 3, 3, 1, 1, 1, 1, 8, 8, 34],
[20, 4, 4, 5, 5, 6, 6, 7, 7, 33],
[21, 4, 4, 5, 5, 6, 6, 7, 7, 32],
[22, 23, 24, 25, 26, 27, 28, 29, 30, 31]])
for i in range(10):
for j in range(10):
if a[i, j] == n:
if i > 0 and a[i-1, j] != n:
ans.append(a[i-1, j])
if i < 9and a[i+1, j] != n:
ans.append(a[i+1, j])
if j > 0and a[i, j-1] != n:
ans.append(a[i, j-1])
if j < 9and a[i, j+1] != n:
ans.append(a[i, j+1])
else:
mx = 45
A068156 = np.zeros(mx)
for i in range(45):
A068156[i] = 3 * 2 ** i + 0 ** i - 3
e4 = np.cumsum(A068156 * 4) - 3
e3 = e4 - A068156
e2 = e3 - A068156
e1 = e2 - A068156
b1 = np.zeros(mx)
b2 = np.zeros(mx)
b3 = np.zeros(mx)
b4 = np.zeros(mx)
for i in range(2, mx):
b1[i - 1] = e4[i - 2] + 1
b2[i - 1] = e1[i - 1] + 1
b3[i - 1] = e2[i - 1] + 1
b4[i - 1] = e3[i - 1] + 1
for i in range(2, mx):
if b1[i] <= n and n <= e4[i]:
lev = i
break
m = e1[lev]-b1[lev]+1
k = int((n-b1[lev]) / m + 1)
if n == b1[lev]:
ans.extend([b1[lev]+1, e4[lev]])
elif n == e4[lev]:
ans.extend([b1[lev], e4[lev]-1])
else:
ans.extend([n-1, n+1])
outer = 2*n+3*k+12*lev-3
ans.extend([outer, outer+1])
if n == e1[lev] or n == e2[lev] or n == e3[lev]:
ans.extend([outer+3, outer+4])
elif n == e4[lev]:
ans.extend([n+1, n+2])
if n != e1[lev] and n != e2[lev] and n != e3[lev]:
if n == b1[lev] or n == b1[lev]+1:
ans.append(b1[lev]-1)
else:
odd = k % 2
if odd == True:
n2 = int(n/2)
else:
n2 = int((n-1)/2)
inner = n2 + 8 - 1.5*k - 6*lev- 0.5*odd
ans.append(inner)
ans = np.sort(np.unique(ans))
s = str(int(ans[0]))
for i in range(1, len(ans)):
s = s+","+str(int(ans[i]))
print(s)
f(int(input()))