Julia で統計解析
2022/8/14 にバージョンアップ
https://r-de-r.github.io/stats/Julia-stats1.html
https://r-de-r.github.io/stats/Julia-stats2.html
https://r-de-r.github.io/stats/Julia-stats3.html
https://r-de-r.github.io/stats/Julia-stats4.html
https://r-de-r.github.io/stats/Julia-stats5.html
https://r-de-r.github.io/stats/Julia-stats6.html
https://r-de-r.github.io/stats/Julia-stats7.html
https://r-de-r.github.io/stats/Julia-stats8.html
https://r-de-r.github.io/stats/Julia-stats9.html
第 1 章 Julia の実行環境
1. 必要なファイルをダウンロードする
2. Julia のインストール
3. Julia を起動し終了する
4. 作業ディレクトリを変える
5. Julia の環境設定をする
5.1. startup.jl ファイルがあるかを確認
5.2. config がなかった場合
5.3. startup.jl がある場合
5.4. 変更内容の確認
6. オンラインヘルプを使う
7. パッケージを利用する
8. エディタを使う
8.1. Atom
8.2. Jupyter lab
9. 結果を保存する
第 2 章 データの入出力
1. データをデータフレームへ読み込む
1.1. Excel のワークシートファイル
1.2. CSV ファイル
1.2.1. 典型的な CSV ファイル
1.2.2. 一般の CSV ファイル
1.2.3. CSV.read の引数
1.3. インターネット上の CSV ファイル
1.4. モニター上に表示された表をデータフレームに読み込む
1.5. クリップボードにコピーした内容をデータフレームにする
1.6. 文字列行から入力する
1.7. エンコーディングの違うファイルを読む
1.8. デリミタで区切られていない固定書式ファイルを読む
2. データフレームを CSV ファイルに書き出す
2.1. CSV.write の引数
第 3 章 データフレームの取り扱い
1. データを使用するための準備
1.1. 既存のデータを使用する
1.2. 自前のデータ
2. データフレームの概要
2.1. データフレームの大きさ
2.2. データフレームの変数名
2.3. データフレームの表示
3. データフレームのコピーは copy() で
4. 空データフレーム
5. データフレームの列の参照
6. データフレームの行の参照
7. データフレームの列名の変更
8. 列の抽出
9. 指定された列を削除する
10. 行の抽出
11. 行の削除
12. 重複を除き,ユニークな行のみを含むデータフレームを作る
13. 欠損値を含む行か含まない行か
14. 欠損値を含まない行を抽出する
15. データフレームの列方向連結
16. データフレームの行方向連結
16.1. cols = :setequal, cols=:orderequal
16.2. cols = :intersect
16.3. cols = :subset
16.4. cols = :union
17. データフレームの最終行の次に 1 行追加する
18. 行を繰り返してデータフレームを作る
19. データフレームに列を挿入する
20. データフレームの要素から新しいデータフレームを作る
21. データフレームの各列に関数を施す
22. ソート(並べ替え)
22.1. ソートされているかをチェックする
22.2. ソートの順番を決める
22.3. 並べ替えベクトルを返す
23. 行の包含
23.1. df1 と df2 のすべての組み合わせを作る crossjoin
23.2. df1 の行のうち,df2 に含まれない行を抽出する antijoin
23.3. df1 に,df2 をマージする innerjoin
23.4. df1 に,df2 をマージする leftjoin
23.5. df1 に,df2 をマージする outerjoin
23.6. df2 に,df1 をマージする rightjoin
23.7. 両方に存在する項目のみでマージする semijoin
24. 欠損値のリストワイズ除去
25. ロングフォーマット(縦長データフレーム)に変換する
26. ワイドフォーマット(横長データフレーム)に変換する
27. データフレームをグループ変数に基づいて分割する
27.1. グループ分けされたデータフレームを抽出する
27.2. グループ化されたデータフレームに関する情報
27.3. 親データフレームを返す
28. 列ごとに関数を適用する
29. 行ごとに関数を適用する
30. クエリーによる操作例
30.1. 要素に関数を適用する @map コマンド
30.2. 条件を満たす行を抽出 @filter コマンド
30.3. データフレームのグループ化 @groupby コマンド
30.4. データのソート @orderby,@orderby_descenidng,@thenby,@thenby_descending コマンド
30.5. データフレームのマージ @groupjoin コマンド
30.6. データフレームの連結 @join コマンド
30.7. キーと値のペアを展開 @mapmany コマンド
30.8. 要素を取り出す @take コマンド
30.9. 要素を捨てる @drop コマンド
30.10. 重複データを除く @unique コマンド
30.11. 列の選択 @select コマンド
30.12. 列名の変更 @rename コマンド
30.13. 変数変換 @mutate コマンド
30.14. 欠損値行を除く @dropna コマンド
30.15. 欠損値を含まないデータフレーム @dissallowna コマンド
30.16. 欠損値の置き換え @replacena コマンド
31. データフレームを二次元配列に変換する
第 4 章 一変量統計
1. 一変量統計
1.1. 一変数の場合
1.1.1. 基礎統計量
1.1.2. パーセンタイル値
1.1.3. 度数分布
1.2. 複数の変数の場合
1.2.1. eachcol() を使う
1.2.2. describe() を使う
1.2.3. combine(), select()/select!(), transform()/transform!() を使う
1.3. グループごとの記述統計量
1.3.1. describe() を使う
1.3.2. 変数ごとに統計量を一覧表示
2. 二変量統計
2.1. 二重クロス集計表
2.2. 相関係数,共分散
2.2.1. 欠損値を含まない場合
2.2.1.1. それぞれの関数を使う
2.2.1.2. combine() を使う
2.2.2. 欠損値を含む場合
2.2.2.1. それぞれの関数を使う
2.2.2.2. combine() を使う
2.3. 相関係数行列,分散・共分散行列
2.3.1. 欠損値を含まない場合
2.3.2. 欠損値を含む場合
3. 多変量統計
3.1. 多重クロス集計表
第 5 章 離散データの可視化
1. 例示に使用するデータセット
1.1. カテゴリーデータ
2. 棒グラフ
2.1. 一標本の場合
2.2. 二標本以上の場合
2.2.1. 横に並べる棒グラフ
2.2.2. 積み上げ棒グラフ
2.3. 複数のグラフを行列状にまとめて表示する方法
3. 帯グラフ
4. モザイクプロット
5. バルーンプロット
第 6 章 数値データの可視化
1. ヒストグラム
1.1. 一標本の場合
1.2. 複数標本の場合
2. ボックスプロット(箱ひげ図)
3. バイオリンプロット
4. ドットプロット
5. カーネル密度推定の描画
6. Q-Q プロット
7. 散布図
8. カーネル密度推定
9. 散布図行列
10. 作図レシピ
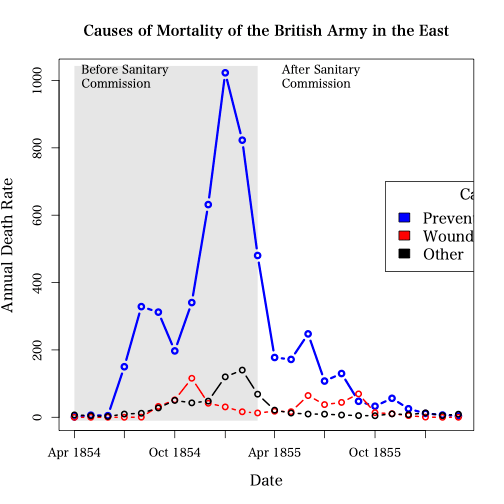
10.1. 二軸グラフ
10.2. Andrews plot
10.3. 星座グラフ
10.4. サンフラワープロット
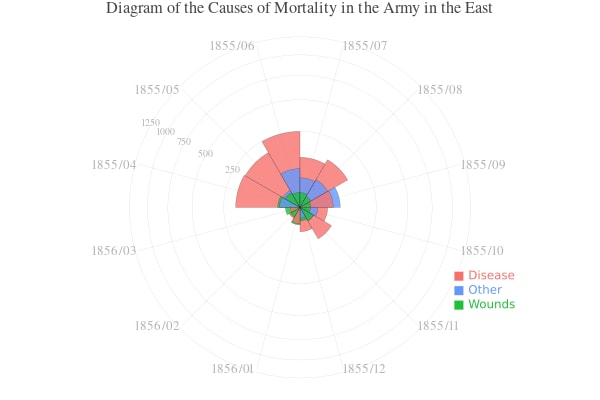
10.5. レーダーチャート
第 7 章 検定と推定
1. 検定関数関数の呼び出し方
2. 検定関数関数により得られる結果の利用法
3. 分布の検定
3.1. 観察度数が一様かどうかの検定
3.1.1. ピアソンの \\chi^2 検定
3.1.2. 対数尤度比検定(G^2 検定)
3.2. 観察度数が理論比に從うかどうかの検定
3.2.1. ピアソンの \\chi^2 検定
3.2.2. 対数尤度比検定(G^2 検定)
4. 独立性の検定
4.1. ピアソンの \\chi^2 検定
4.2. 対数尤度比検定(G^2 検定)
5. パワーダイバージェンス検定
6. フィッシャーの正確検定
7. 二項検定
8. t 検定
8.1. 一標本の検定(母平均の検定)
8.2. 等分散の場合の t 検定
8.3. 等分散でない場合 Welch の方法
9. マン・ホイットニーの U 検定
10. 符号検定
11. ウィルコクソンの符号付き順位和検定
12. 相関係数の検定
13. 対応のない k 標本(独立 k 標本)
13.1. 一元元配置分散分析
13.2. 一元元配置分散分析(ウェルチの方法)
13.3. クラスカル・ウォリス検定
14. コルモゴロフ・スミルノフ検定
14.1. 1 標本の分布の検定
14.2. 2 標本の分布の差の検定
15. アンダーソン・ダーリング検定
15.1. 1 標本の場合
15.2. k 標本の場合
16. ワルド・ウォルフォビッツ連検定
17. 並べ替え検定(無作為検定)
第 8 章 多変量解析
1. 回帰分析
1.1. 線形最小二乗回帰 Linear Least Square
1.1.1. 単回帰分析
1.1.2. 重回帰分析
1.2. リッジ回帰 Ridge Regression
1.2.1. 説明変数が 1 個の場合
1.2.2. 説明変数が 2 個以上の場合
1.3. GLM パッケージによる回帰分析
1.3.1. 重回帰分析 Ordinary Least Squares Regression
1.3.2. プロビット回帰 Probit Regression
1.3.3. ロジット回帰 Logit Regression
1.4. 多項式回帰
1.4.1. 重回帰プログラムを用いる
1.4.2. 多項式回帰 Polynomials パッケージ
1.5. 指数回帰
1.5.1. 説明変数が 1 個の場合
1.5.2. 説明変数が 2 個以上の場合
1.6. 累乗回帰
1.6.1. 説明変数が 1 個の場合
1.6.2. 説明変数が 2 個以上の場合
1.7. 非線形回帰
2. 判別分析
2.1. 二群判別分析
2.2. 多重判別分析
3. 主成分分析
4. 因子分析
5. 古典的多次元尺度解析
6. クラスター分析
6.1. K-means 法による非階層的クラスター分析
6.2. 階層的クラスター分析
7. カテゴリー変数の取り扱い方
7.1. 重回帰分析の場合
7.2. 判別分析の場合
第 9 章 関数