








現地で使いやすい両替
締め切りが 201702/21 10:00 AM なので,その 1 分後に投稿されるように予約
設問
日本から海外旅行に行く場合は外貨に両替しますが、海外からの旅行者が日本に来るときは日本円に両替します。
このとき、現時点でのレートに従って両替しますが、使うときに便利なように、紙幣や硬貨を組み合わせます。
できるだけ現地の文化を知りたいので、多くの種類を組み合わせて両替したいところです。
今回は米ドルから日本円への両替を考えます。
紙幣や硬貨の種類の数が最大になるもののうち、全体の枚数が最小になる両替方法を求め、その全体の枚数を出力してください。
例えば、1ドル112.54円のときに100ドルを日本円に交換すると11,254円で、その交換方法として以下のような例があります。
紙幣・硬貨 例1 例2 例3 例4 例5
1万円札 1 0 0 0 0
5千円札 0 1 1 1 1
2千円札 0 0 1 2 2
千円札 1 5 3 1 1
500円玉 0 2 2 1 2
100円玉 2 1 1 4 1
50円玉 1 2 1 4 2
10円玉 0 5 9 14 4
5円玉 0 0 2 2 2
1円玉 4 4 4 4 4
枚数 9 20 24 33 19
例1は紙幣や硬貨の種類が5種類、例2は7種類なのに対し、例3〜5は9種類のため、例3〜5の中から、全体の枚数が少ない例5を選びます。
(他のパターンの中でも、例5が最小になります。)
標準入力から両替後の日本円の金額が指定されたとき、紙幣・効果の種類が最大で全体の枚数が最小になる場合を求め、その時の枚数を標準出力に出力してください。
なお、入力されるのは整数のみで、最大でも50,000とします。
【入出力サンプル】
標準入力
11254
標準出力
19
=================================================
expand.grid ですべての組み合わせを作っておき,その中で,条件を満たす場合を抽出する
f = function(y) {
x = c(10000, 5000, 2000, 1000, 500, 100, 50, 10, 5, 1)
a = expand.grid(0:4*10000, 0:1*5000, 0:5*2000, 0:2*1000, 0:2*500, 0:5*100, 0:2*50, 0:5*10, 0:2*5, 0:5)
index = rowSums(a) == y
a = a[index,]
kind = rowSums(a > 0)
n = apply(a, 1, function(z) sum(z/x))
cat(min(n[which(kind == max(kind))]))
}
f(11254) # 19


ぐるぐるスクエア
締め切りが 2017/02/17 10:00 AM なので,その 1 分後に投稿されるように予約
【概要】
下図のように四角形のマスに数が入っています。
マスは無限に広がっており、全てのマスに数が入っています。
数を指定するので、その数が書かれているマスに隣接する(つまり、辺を共有する)4つのマスに書かれている数を、小さい順に出力してください。
※法則は図から読み取ってください
【入出力】
入力は
12
のように、普通に 10進数で来ます。
出力は、
3,11,13,29
のような感じです。
4つの数をコンマ区切りで昇順に並べてください。
【例】
入力 出力
12 3,11,13,29
34 15,33,35,61
77 46,76,78,116
【補足】
不正な入力に対処する必要はありません。
入力は、1以上、1000以下です。
================================================
規則性を利用してプログラム
「入力は、1以上、1000以下」の意味は何なのだろうか?上限は幾つだろうと計算時間はほとんど瞬殺。
ru = function(n) 4 * n^2 + 4 * n + 1 # 右上 1,9,25,49,81,... の数列 n=0,1,2,3,4,...
lu = function(n) 4 * n^2 + 6 * n + 3 # 左上 1,3,13,31,57,... の数列
ld = function(n) 4 * n^2 + 8 * n + 5 # 左下 1,5,17,37,65,... の数列
rd = function(n) 4 * n^2 + 10 * n + 7 # 右下 1,7,21,43,73,... の数列
up = function(n) 8 * n + 9 # 上のサイクルへの差分 例えば 2(サイクル0) から 11(サイクル1) への差分
left = function(n) 8 * n + 11 # 左のサイクルへの差分 例えば 3(サイクル0) から 14(サイクル1) への差分
down = function(n) 8 * n + 13 # 下のサイクルへの差分 例えば 6(サイクル0) から 19(サイクル1) への差分
right = function(n) 8 * n + 15 # 右のサイクルへの差分 例えば 8(サイクル0) から 23(サイクル1) への差分
f = function(N) {
n = 0 # どのサイクルにあるか検出s
repeat { # サイクルは (1-8), (9-24), (25-48), ... をサイクル 0, 1, 2, ... とする
if (N >= ru(n) && ru(n + 1) > N) {
break
}
n = n + 1
}
RU = ru(n) # サイクルの開始点
LU = lu(n) # サイクルの左折点(左向きから下向きへ)
LD = ld(n) # サイクルの左折点(下向きから右向きへ)
RD = rd(n) # サイクルの左折点(右向きから上向きへ)
a = if (N == 1) { # N = 1 は特別
N + c(up(-1), left(-1), down(-1), right(-1)) # (2, 4, 6, 8)
} else if (N == RU) { # N = RU = 49
c(ru(n - 1) + 1, N - 1, N + 1, ru(n + 1) - 1) # (26, 48, 50, 80)
} else if (N == RU + 1) { # N = RU+1 = 50
c(N - 1, N + 1, ru(n + 1), ru(n + 1) + 2) # (49, 51, 81, 83)
} else if (N > RU + 1 && LU - 1 > N) { # N = 51 thru 55
c(N - up(n - 1), N - 1, N + 1, N + up(n)) # N = 51; (26, 50, 52, 84)
} else if (N == LU - 1) { # N = 56
c(lu(n - 1), N - 1, N + 1, lu(n + 1) - 2) # (31, 55, 57, 89)
} else if (N == LU) { # N = LU = 57
c(N - 1, N + 1, lu(n + 1) - 1, lu(n + 1) + 1) # (56, 58, 90, 92)
} else if (N > LU && LD > N) { # N = 58 thru 64
c(N - left(n - 1), N - 1, N + 1, N + left(n)) # N = 58; (31, 57, 59, 93)
} else if (N == LD) { # N = 65
c(N - 1, N + 1, ld(n + 1) - 1, ld(n + 1) + 1) # (64, 66, 100, 102)
} else if (N > LD && RD > N) { # N = 66 thru 72
c(N - down(n - 1), N - 1, N + 1, N + down(n)) # N = 66; (37, 65, 67, 103)
} else if (N == RD) { # N = 73
c(N - 1, N + 1, rd(n + 1) - 1, rd(n + 1) + 1) # (72, 74, 110, 112)
} else if (N > RD && ru(n + 1) > N) { # N = 74 thru 81
c(N - right(n - 1), N - 1, N + 1, N + right(n)) # n = 74; (43,73,75,113)
}
cat(a, sep = ",")
}
> f(1)
2,4,6,8
> f(2)
1,3,9,11
> f(3)
2,4,12,14
> f(4)
1,3,5,15
> f(5)
4,6,16,18
> f(6)
1,5,7,19
> f(7)
6,8,20,22
> f(8)
1,7,9,23
> f(9)
2,8,10,24
> f(10)
9,11,25,27
> f(100000)
98739,99999,100001,101269
ダブルテトロミノ
締め切りが 2017/02/17 10:00 AM なので,その 1 分後に投稿されるように予約
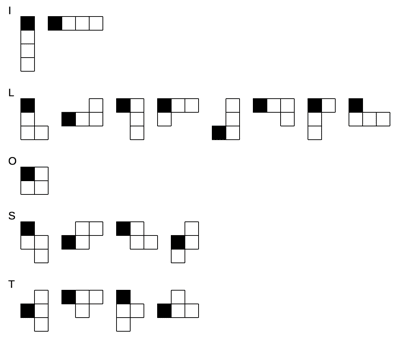
下図のように、黒いマスが 8つあります。

テトロミノ2つを使って黒いマスで示された図形を作るには、どんなテトロミノが必要なのか、全ての組み合わせを求めてください。
例えば上の例の場合、
LとO、LとS
という組み合わせが考えられます。
テトロミノは、下図の 5 種類があります:

裏返したり回転したりしてできるテトロミノは同じ名前です。
入力は
56 37 36 55 35 46 45 47
のような感じです。
空白区切りで黒いマスの位置が書かれています。
黒いマスの位置は、1文字目が x 座標、2文字目がy座標です。
出力は、
LO,LS
のような感じです。
ペアをコンマ区切りで並べてください。
ペア間もペア内も、アルファベット順に整列しておく必要があります。
下表の通りです。
誤 LS,LO
誤 OL,SL
正 LO,LS
入力の形が2つのテトロミノでは作れない場合は、
-
を出力してください。
【例】
入力 出力
56 37 36 55 35 46 45 47 LO,LS
70 07 44 34 98 11 00 32 -
63 60 67 65 64 62 61 66 II
【補足】
不正な入力に対処する必要はありません。
入力には、かならず8マス含まれています。重複はありません。
====================
テトロミノは回転・対称も考えて 19 通りあるので,それをデータ化する。
たとえば,図にある T テトロミノは,左にある黒を(0,0) として,残り 3 つの正方形は (-1,1), (0,1), (1,1) にあるなど。
19 通りのテトロミノを最初の盤面の黒の位置に順次置いていって,最初の同じ盤面になれば 2 つのテトロミノの種類を記憶する。
ブルートフォースでプログラムしたが,制限時間内に答えが出るので,チューンアップはしない。
f = function(s) {
a = cbind(
c(0,0,1,0,2,0,3,0), # I
c(0,0,0,1,0,2,0,3),
c(0,0,1,0,2,0,2,1), # L
c(0,0,0,1,0,2,-1,2),
c(0,0,0,1,1,1,2,1),
c(0,0,1,0,0,1,0,2),
c(0,0,0,1,-1,1,-2,1),
c(0,0,0,1,0,2,1,2),
c(0,0,1,0,2,0,0,1),
c(0,0,1,0,1,1,1,2),
c(0,0,1,0,0,1,1,1), # O
c(0,0,1,0,1,1,2,1), # S
c(0,0,0,1,-1,1,-1,2),
c(0,0,0,1,1,1,1,2),
c(0,0,1,0,0,1,-1,1),
c(0,0,-1,1,0,1,1,1), # T
c(0,0,0,1,0,2,1,1),
c(0,0,1,0,2,0,1,1),
c(0,0,0,1,0,2,-1,1)
)
dim(a) = c(2, 4, 19) # ピースを構成する正方形の4つの座標(x, y)が19種類
p = c("I", "I", rep("L", 8), "O", rep("S", 4), rep("T", 4)) # ピースの名前
xy = matrix(as.numeric(unlist(strsplit(gsub(" ", "", s), ""))) + 1, byrow = TRUE, ncol = 2) # 10行10列の行列における黒いマスの座標
b0 = matrix(0, 10, 10)
b = matrix(0, 10, 10)
b[xy] = 1 # マーク
kxy = (xy[, 2] - 1) * 10 + xy[, 1] # ここまでで盤面の設定(手本の盤面と呼ぶ)
ans = NULL
for (i in 1:19) { # 回転・反転を考慮した19種のテトロミノを順次試す
for (j in i:19) { # 回転・反転を考慮した19種のテトロミノを順次試す
for (k1 in 1:8) { # i番目のテトロミノを置くマスの位置 (xy[k1,1], xy[k1,2]) を順次試す
for (k2 in 1:8) { # j番目のテトロミノを置くマスの位置 (xy[k2,1], xy[k2,2]) を順次試す
b1 = b0 # 新しい(クリーンな)盤面
for (l in 1:4) { # テトロミノを構成する4つの正方形で盤面をマークする
sxi = xy[k1, 1] + a[1, l, i] # i番目のテトロミノが置かれる盤面の行
syi = xy[k1, 2] + a[2, l, i] # i番目のテトロミノが置かれる盤面の列
if ((sxi >= 1 && 10 >= sxi) && (syi >= 1 && 10 >= syi)) {
b1[sxi, syi] = 1 # はみ出さないのでマーク
}
sxj = xy[k2, 1] + a[1, l, j] # j番目のテトロミノが置かれる盤面の行
syj = xy[k2, 2] + a[2, l, j] # j番目のテトロミノが置かれる盤面の列
if ((sxj >= 1 && 10 >= sxj) && (syj >= 1 && 10 >= syj)) {
b1[sxj, syj] = 1 # はみ出さないのでマーク
}
}
if (all(b1 == b)) { # 手本の盤面と同じであれば結果を記録(2つのテトロミノは何だったか)
ans = rbind(ans, c(p[i], p[j]))
}
}
}
}
}
ans = unique(as.data.frame(ans)) # 同じ解を取り除く
if (nrow(ans) == 0) { # 解がないとき
cat("-")
} else { # 解があるとき
cat(paste(apply(ans, 1, paste, collapse = ""), collapse = ","))
}
cat("\n")
}
f("56 37 36 55 35 46 45 47") # LO,LS
f("70 07 44 34 98 11 00 32") # -
f("63 60 67 65 64 62 61 66") # II
f("65 46 45 66 54 44 64 56") # LL
f("34 46 36 47 33 44 35 45") # II,SS,TT
f("85 75 76 84 83 73 86 74") # II,LL,OO
f("67 76 77 78 68 69 58 57") # LT,ST
f("44 45 34 55 43 35 33 56") # LO,LS
f("55 46 66 45 44 57 54 56") # LT,OT
f("43 24 35 33 34 32 23 44") # SS,TT
f("20 10 12 21 03 22 13 11") # LL,OS
f("53 54 75 45 55 35 65 56") # -
f("88 89 86 87 78 68 99 79") # -
f("28 37 25 38 35 47 46 36") # SS
f("94 93 01 03 02 91 92 04") # II
「ルーム・アンド・ルーフ」問題
相変わらず,題名が不適切であるが。
締め切りが 2017/02/16 10:00 AM なので,その 1 分後に投稿されるように予約
設問
一辺の長さが 1 の正方形を考えます。これを P0 と呼びます。
各頂点を時計回りに A, B, C, D とします。
P0 に対し、次の手順で新しい正方形を描きます。
辺 BC と同じ辺を持つ正三角形 BCE を P0 の外側に描きます。
D と E を線分で結びます。
そして線分 DE を一辺とする正方形を右側に描きます。この正方形を P1 と呼びます。

同じ作業を P1 に対し行い、正方形 P2 を描きます。
以降同様に、P3, P4, … と次々と正方形を描くことができます。
自然数 n に対し、Pn の面積の値を小数点以下で切り捨てた値を F(n) と定義します。
例えば F(1)=3 です。P1 の面積はおよそ 3.732 だからです。
同様に、F(2)=13, F(3)=51 となることが確かめられます。
標準入力から、自然数 n (1 ≦ n ≦ 10^6)が与えられます。
標準出力に F(n) を 10^6 で割った余りを出力するプログラムを書いてください。
==================================
答えは floor((2+sqrt(3))^n) になることがすぐにわかるが,この数列は,爆発的に大きくなる。
もう一つの答えは a(n) = 4*a(n-1)+a(n-2) の漸化式があるので,こちらを使って解を求める。
R では制限時間に引っかかるので, AWK や Java で書いたら,答えが違う。
その原因は整数剰余の定義の違いだった。
R では -5 %% 6 は 1 になるが,
AWK や Java では -5 になる。
ということで,R プログラムは
f = function(n) {
a1 = 2
a2 = 4
for (i in 2:n) {
a3 = (4*a2 - a1) %% 1e6
a1 = a2
a2 = a3
}
cat(a3-1)
}
f(4) # 193
f(10) # 524173
f(601) # 868003
f(749501) # 493043
f(987654) # 378701
f(999600) # 1
AWK では,
function f(n, a1, a2, a3, i) {
a1 = 2
a2 = 4
for (i = 2; n >= i; i++) {
a3 = 4*a2 - a1
if (a3 < 0) a3 += 1e6
a3 %= 1e6
a1 = a2
a2 = a3
}
print a3-1
}
{ f($0) }
出る杭
締め切りが 2017/02/16 10:00 AM なので,その 1 分後に投稿されるように予約
仕様
a-zの小文字で構成される文字列の真ん中の文字を大文字に変換してください。
文字列の文字数(N)が奇数の場合は N/2 の小数点以下を切り上げた位置を「真ん中」とします。
文字列の文字数(N)が偶数の場合は (N/2 + 1) の位置を「真ん中」とします。
標準入力
a-zの小文字で構成される文字列が入力されます
文字列の文字数は 1-10 文字とします
入力は5行固定です。行単位で真ん中の文字を大文字にしてください
例
c
vb
awk
java
scala
標準出力
標準入力の各行の真ん中の文字を大文字にしてください。
例
C
vB
aWk
jaVa
scAla
その他の仕様
標準入力の末尾には改行があります
標準出力の末尾に改行をつけてください
標準入力の仕様で説明した内容以外の入力は行われません(不正入力に対するチェックは不要)
=============================================
f = function(S) {
for (s in S) {
N = nchar(s)
i = (N+2-N%%2)/2
substr(s,i,i) = toupper(substr(s,i,i))
cat(s,"\n",sep="")
}
}
f(readLines(file("stdin", "r")))
「ぶーつすとらっぷ」じゃあ,ないよ。
どこぞやらで,だれかが,R を使ってブートストラップによる母相関係数の分布を推定するというブログを書いておったが,ちっとも R らしくなかったので,書いてみた。
具体例のデータは,サンプルサイズ 20 の以下のようなもの。
x = c(7.8, 25.1, 36.1, 27.1, 24.5, 11.4, 27.6, 12.3, 5.1, 4, 26.3, 21.8, 35.4, 18.5, 31.6, 7, 10.8, 24.2, 25.4, 17.9)
y = c(29.3, 13.5, 28.9, 38.8, 30.4, 8.1, 19.7, 25.9, 2.5, 16.2, 10.3, 21.2, 27.6, 12.5, 29.1, 8, 8.6, 29.7, 25.9, 13.8)
このデータから,x, y それぞれで,重複を許して 20 個のデータを抽出して相関係数を計算するというのを多数回繰り返す。
x から重複を許して 20 個のデータをリサンプリングするのは
sample(x, replace=TRUE)
y から重複を許して 20 個のデータをリサンプリングするのは
sample(x, replace=TRUE)
その相関係数を計算するのは
cor(sample(x, replace=TRUE), sample(y, replace=TRUE))
それを,たとえば 50000 回繰り返すのは
sapply(1:50000, function(i) cor(sample(x, replace=TRUE), sample(y, replace=TRUE)))
その結果を要素数 50000 のベクトル result に格納するのは
result = sapply(1:50000, function(i) cor(sample(x, replace=TRUE),
sample(y, replace=TRUE)))
そのヒストグラムは
hist(result)
リサンプリングデータにおける相関係数の絶対値が,観察されたデータでの相関係数 cor(x, y) より大きい割合は,
mean(abs(result) > cor(x, y))
sum(abs(result) > cor(x, y)) / 50000 としたいかもしれないが,それは mean だ!
リサンプリングによらず,観察されたデータでの母相関係数=0の検定(両側)の p 値は
cor.test(x, y)$p.value
sample 関数は乱数発生を伴うので,以下のプログラムでの結果は,毎回異なるが,mean(abs(result) > cor(x, y)) と cor.test(x, y)$p.value の結果はほぼ等しくなる。
> x = c(7.8, 25.1, 36.1, 27.1, 24.5, 11.4, 27.6, 12.3, 5.1, 4, 26.3, 21.8, 35.4, 18.5, 31.6, 7, 10.8, 24.2, 25.4, 17.9)
> length(sample(x, replace=TRUE))
[1] 20
> length(sample(x, replace=TRUE))
[1] 20
> x = c(7.8, 25.1, 36.1, 27.1, 24.5, 11.4, 27.6, 12.3, 5.1, 4, 26.3, 21.8, 35.4, 18.5, 31.6, 7, 10.8, 24.2, 25.4, 17.9)
> y = c(29.3, 13.5, 28.9, 38.8, 30.4, 8.1, 19.7, 25.9, 2.5, 16.2, 10.3, 21.2, 27.6, 12.5, 29.1, 8, 8.6, 29.7, 25.9, 13.8)
> result = sapply(1:50000, function(i) cor(sample(x, replace=TRUE), sample(y, replace=TRUE)))
> hist(result)
> mean(abs(result) > cor(x, y))
[1] 0.00994
> cor.test(x, y)$p.value
[1] 0.009260503
並べ替えの繰り返し2
締め切りが 2017/02/14 10:00 AM なので,その 1 分後に投稿されるように予約
設問
1〜m までの数字が1つずつ書かれた m 枚のカードがあります。
カードは一列に並べられており、一番左のカードに書かれている数字を見て、その数の枚数だけカードを左から取り、並びを逆順にする作業を繰り返します。
作業は左端が1になるまで続けます。
例えば、m = 4 のとき、最初の並びが「3 4 2 1」の順になっていると、以下の手順を繰り返して3回で停止します。
3 4 2 1
↓ 1回目:左端が3なので、左の3枚を反転
2 4 3 1
↓ 2回目:左端が2なので、左の2枚を反転
4 2 3 1
↓ 3回目:左端が4なので、4枚を反転
1 3 2 4
標準入力から m, n という2つの数がスペースで区切って与えられたとき、与えられた m 枚のカードに対して上記と同様の作業を n 回行って停止するような最初の並びが何通りあるかを求め、標準出力に出力してください。
(なお、mは最大で9とします。)
例えば、 m = 4, n = 3 のとき、上記のほかに以下のパターンがあり、合わせて4通りありますので、標準出力に「4」を出力します。
4 2 1 3
↓
3 1 2 4
↓
2 1 3 4
↓
1 2 3 4
4 1 3 2
↓
2 3 1 4
↓
3 2 1 4
↓
1 2 3 4
2 3 4 1
↓
3 2 4 1
↓
4 2 3 1
↓
1 3 2 4
【入出力サンプル】
標準入力
4 3
標準出力
4
=========================================================
R ならば短く書けるけど,実行時間が 1 秒を超える(せいぜい 4,5 秒なんだけど)
出題者は,再帰プログラムを望んでいるのだろうけど
f = function(m, n) {
g = function(x) {
count = 0
while (x[1] != 1) {
i = 1:x[1]
x = c(rev(x[i]), x[-i])
count = count+1
if (count > n) break
}
count == n
}
library(e1071)
a = permutations(m)
z = apply(a, 1, g)
cat(sum(z))
}
system.time(f(4, 3)) # 4
system.time(f(6, 2)) # 120
system.time(f(8, 15)) # 277
system.time(f(9, 30)) # 1
system.time(f(9, 0)) # 40320
=========================================================
Java ならば瞬殺
import java.util.Scanner;
public class sortCards {
public static void main(String[] args) {
Scanner cin = new Scanner(System.in);
String line;
String [] line2 = new String[2];
line = cin.nextLine();
line2 = line.split(" ");
int m = Integer.parseInt(line2[0]);
int n = Integer.parseInt(line2[1]);
int sizeZ = factorial(m);
// System.out.println(m+" "+sizeZ);
int [][] z = new int[sizeZ+1][m+1];
int ans = 0;
z = permutations(m);
for (int i = 1; sizeZ >= i; i++) {
int cnt = 0;
while (z[i][1] != 1) {
int k = z[i][1];
// System.out.println(k+" "+k/2);
for (int j = 1; k/2 >= k; j++) {
int temp = z[i][j];
z[i][j] = z[i][k-j+1];
z[i][k-j+1] = temp;
}
cnt++;
}
// System.out.println(cnt);
if (cnt == n) ans++;
}
System.out.println(ans);
}
static int factorial(int n) {
int i, result = 1;
for (i = 1; n >= i; i++) {
result *= i;
}
return result;
}
static int[][] permutations(int n) {
int sizeZ = factorial(n);
int sizeX = sizeZ / (n - 1);
int[][] z = new int[sizeZ+1][n+1];
int[][] x = new int[sizeX+1][n+1];
int nrowZ, ncolZ, nrowX, ncolX;
int i, i2, j, j2;
z[1][1] = 1;
nrowZ = ncolZ = 1;
for (i = 2; n >= i; i++) {
for (i2 = 1; nrowZ >= i2; i2++) {
for (j2 = 1; ncolZ >= j2; j2++) {
x[i2][j2] = z[i2][j2];
}
x[i2][ncolZ + 1] = i;
}
nrowX = nrowZ;
ncolX = ncolZ + 1;
for (j = 1; i >= j; j++) {
for (j2 = 1; nrowX >= j2; j2++) {
for (i2 = 1; ncolX >= i2; i2++) {
z[(j - 1) * nrowX + j2][i2] = x[j2][(j + i2 - 2) % i
+ 1];
}
}
}
nrowZ = i * nrowX;
ncolZ = ncolX;
}
return z;
}
}
ワイルドキーボード
締め切りが 2017/02/09 10:00 AM なので,その 1 分後に投稿されるように予約
設問
「バイッ!ナッッリ!」
(01の2進数だけで構成された文字列を、ASCII文字列のバイナリ表記とみなして、元のテキストに戻して欲しい。)
【入出力サンプル】
例1)
STDIN
011000010110001000001010
STDOUT
ab
例2)
STDIN
01100001000010100110001000001010
STDOUT
a
b
========================================
R は簡単でいいなぁ
関数が入れ子になるのもカッチョイイと思う
readLines(file("stdin", "")) は,標準入力から入力する
cat(intToUtf8(matrix(as.integer(unlist(strsplit(readLines(file("stdin", "")), ""))), ncol=8, byrow=TRUE) %*% 2^(7:0)))
スーパー素数
締め切りが 2017/02/09 8:00 AM なので,その 1 分後に投稿されるように予約
仕様
標準入力で指定された数値を元に N 番目のスーパー素数を表示してください。
スーパー素数とは
スーパー素数とは素数の数列の素数番目の要素で構成される数列である。
例
3, 5, 11, 17, 31, 41, 59, 67, 83, 109, 127, ...
標準入力
数値(1-2017)の範囲の整数が入力されます
標準出力
標準入力番目のスーパー素数を出力する
その他の仕様
・標準入力の末尾には改行があります
・標準出力の末尾に改行をつけてください
・標準入力の仕様で説明した内容以外の入力は行われません(不正入力に対するチェックは不要)
==========================
f = function(N, mx = 2e+05) {
tbl = 1:mx
tbl[1] = 0
for (i in 2:floor(sqrt(mx))) {
if (tbl[i]) {
mx2 = mx%/%i
tbl[2:mx2 * i] = 0
}
}
prime = tbl[tbl > 0]
a = prime[prime]
b = a[!is.na(a)]
b[N]
}
cat(f(2), "\n") # 5
cat(f(30), "\n") # 617
cat(f(2017), "\n") # 194591
ちょっと奇妙な足すと引く
締め切りが 2017/02/02 10:00 AM なので,その 1 分後に投稿されるように予約
【概要】
ここはとある遠い世界。この世界にも数式があり、足し算と引き算があります。
19+2-3-4
こんな具合。この式を、我々の世界では
((19+2)-3)-4
と解釈して
19+2-3-4 = 14
とするけど、この世界では
19+(2-(3-4))
と解釈して
19+2-3-4 = 22
となります。
要するに、「+と-の優先順位は同じで両方とも右結合」ということです。
で。
数式を与えます。この世界のルールで計算してください。
【入出力】
入力は
19+2-3-4
のような感じです。
演算子は+と-しか登場しません。括弧があることもあります。
1-4のように、計算結果が負の値になる場合には、我々の世界と同様に数字の前に「-」をつけて-3のようにしてください。
そうそう。言い忘れていましたが、数字はこの世界でも 10進数で、同じ記号を使います。
出力は計算結果になります。
【例】
入力 出力
19+2-3-4 22
1-4 -3
2-(2-2)-2 4
【補足】
不正な入力に対処する必要はありません。
入力文字列の長さは、1〜32 文字です。
入力に含まれる数は、十億以下 です。
入力文字列に、符号を示すマイナスは含まれません。
=======
入力をパースして逆ポーランド記法で表現し,それをスタックを使って数式を評価する
f = function(s) {
s = gsub("([-\\+()])", " \\1 ", s)
s = gsub(" *", " ", s)
s = unlist(strsplit(s, " "))
parse = stack = NULL
for (t in s) {
if (grepl("[0-9]+", t)) {
parse = c(parse, t)
} else if (t == "(") {
stack = c(t, stack)
} else if (t == ")") {
repeat {
if (length(stack) == 0) {
break
}
top = stack[1]
stack = stack[-1]
if (top == "(") {
break
}
parse = c(parse, top)
}
} else {
stack = c(t, stack)
}
}
parse = c(parse, stack)
stack = NULL
for (t in parse) {
if (grepl("\\-*[0-9]+", t)) {
stack = c(t, stack)
} else {
if (length(stack) > 1) {
ans = eval(parse(text=sprintf("%s%s%s", stack[2], t, stack[1])))
stack = stack[-1]
} else {
ans = stack[1]
}
stack[1] = ans
}
}
cat(stack)
}
#f(readLines(file("stdin", "r")))
f("19+2-3-4") # 22
f("19+(2-(3-4))") # 22
f("6-1-4-4-8-4-6-3-5-8-7-9-9-2-7-8") # 13
f("8-9+6+9+5+1+6-1-4-2+4+8-2+1+5+4") # -29
f("3+3-1-6+7-5+5+9+2+4-8+3+1-4+5+5") # -9
f("6-68-47-3-76-52-78-15-20-99-58") # 48
f("23+13+85-49+41+64+69-0+50-34-93") # 7
f("12-(3-4-(5-6-7)-8-(9-10-11))-123") # 128
f("9-(((((((((((((34)))))))))))))-1") # -24
f("987-(12-(3-45-6)-7-8)-9-(123+45)") # 781
f("(9-10)-(2-5)-(7-9)-(7-45)-(3-39)") # 2
f("(((((((99-8)-7)-6)-5)-4)-3)-2)-9") # 55
f("999999999+999999999+999999999+99") # 3000000096
f("1000000000-(99-19-3)+(88-32-11)") # 999999850
テキストから数値のみマスクしよう
締め切りが 2017/02/02 10:00 AM なので,その 1 分後に投稿されるように予約
あなたはとあるレポートを文章校正のため社外の機関に送るよう任されました。
ただしレポートに含まれる数値は機密情報のため、すべてマスクする必要があるとのこと。
さらに桁数すらわからないようにとのお達しのため、単純に数字(0-9)を記号に置換するだけというわけにもいきません。
そこで、テキストから数値のみを検出し、*(アスタリスク)一文字に置換するプログラムを作ることになりました。
求められるプログラムの前提条件は、以下の通りとなります。
標準入力から、制御文字を除くASCII文字のみで構成された文字列が送られる
※制御文字は入らないため、改行も含まれない
文字列は80byte以下とする
文字列に含む、すべての数値を*(アスタリスク)一文字に置き換える
数値とは、整数・小数点数・"2.43E-19"といった指数表記による数のことを指す
数の前に符号(-もしくは+)がある場合、符号も含めて数値とみなす
指数表記におけるEは小文字・大文字双方とも扱うものとする
すべての数値を*に置換した文字列を標準出力に返すこと
以下、置換例となります。
【入出力サンプル】
標準入力
x=12 y=-34.5 z=7e-8
標準出力
x=* y=* z=*
企業において、この数値をマスクするという作業は、実は社外だけではなく他部署に向けて公開する場合でもよくあることです。
例えば、特定プロジェクトの売上といったセンシティブな情報は、社内とはいえ取り扱いを厳重にしないといけない為です。
本当はこの機能、某社のOffice製品にこそあれば…おっとつい脱線しましたね。
是非挑戦してみてください!
【問題】
標準入力から、制御文字を除くASCII文字のみで構成されたテキストが送られます。
このテキストから数値のみを検出し、*(アスタリスク)一文字に置き換えて、その結果を標準出力に返してください。
============================
数を表す正規表現を正確に定義できるかどうかということ
s = readLines(file("stdin", "r"))
cat(gsub("(\\+|-)?[0-9]+((\\.[0-9]+)?((E|e)(\\+|-)?[0-9]+)?)?", "*", s))
PVアクセスランキング にほんブログ村







