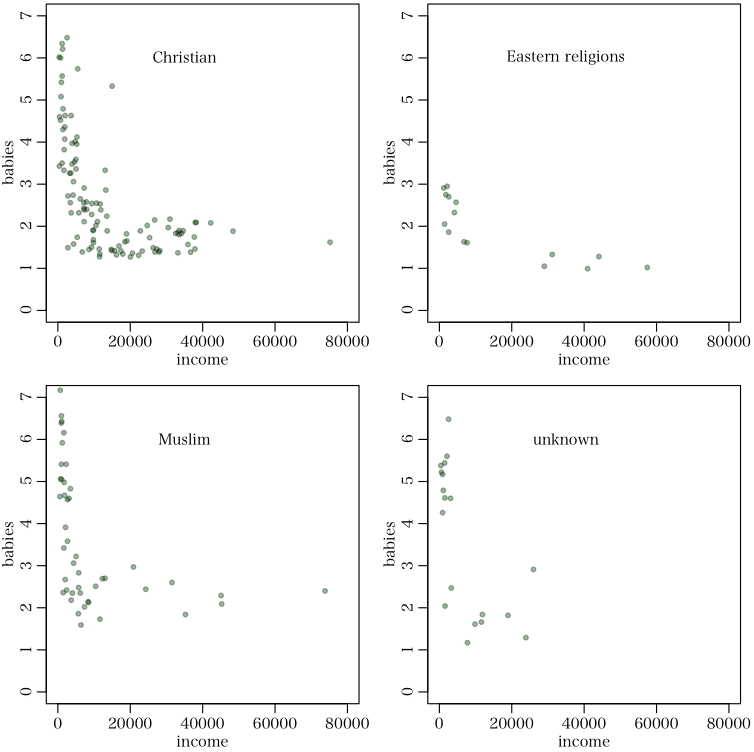
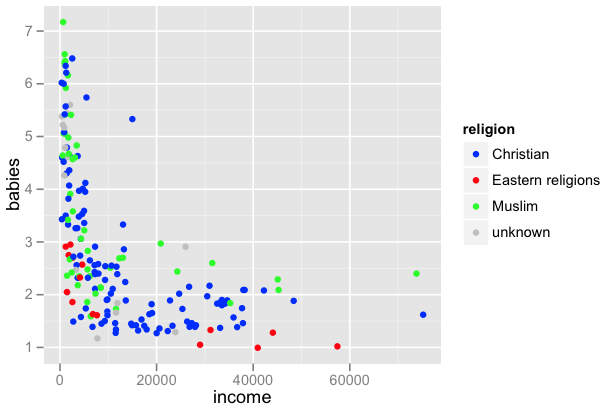
少なくとも,私の環境 Mac OS X 10.8.1 では,Rstudio 0.96.330 は,日本語入力においてユーザにストレスを感じさせる(入力中,全く入力状況が表示されない) 。とても,まともに使うことはできない。
偶然(?)発見した少しはましなやり方は,
1. 外部エディタ(私は Jedit 2.33)を使って,ソース(*.Rmd)を作る・編集する
2. Rstudio で,そのファイルを使用するようにしておくと,外部エディタの編集結果を保存すると,Rstudio のソース・ウインドウに *.Rmd の編集結果が反映される
3. Rstudio で "Preview" をクリックすると,その時点での *. Rmd ファイル から *.html ファイルが作成され,その結果が Rstudoio:Preview HTML ウインドウに表示される
これを繰り返して,最終的なファイルを得ることができるということ。
まあ,R コンソールで knit2html 関数を実行し,ブラウザで結果を確認するという繰り返しでもよいのだけど,少しだけ手間を省ける。