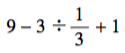安易に考えて,ただし,ベクトル演算で速度を上げても計算時間がそこそこかかる。さらに,解答先のコンピュータが若干遅く,しかも計算時間は 1 秒以下という制限があるので,とても,以下のプログラムでは無理。
g = function(L) {
# con = file("stdin", "r"); L = as.integer(readLines(con, 1))
eps = .Machine$double.eps
count = 0
for (b0 in seq_len(L %/% 2)) {
a = seq_len(b0) * 2
b = b0 * 2
c = sqrt(a^2 + b^2)
bool.c = (c == floor(c + eps))
if (any(bool.c)) {
az = a[bool.c]
cz = c[bool.c]
x = cz/2
a2 = x + (az + cz) * x / b
b2 = b * a2 / az
count = count + sum(a2 == floor(a2 + eps) & b2 == floor(b2 + eps))
}
}
count
}
計算結果
> system.time(cat(g(100))) # 15
15 ユーザ システム 経過
0.017 0.001 0.011
> system.time(cat(g(456))) # 77
77 ユーザ システム 経過
0.002 0.000 0.002
> system.time(cat(g(7654))) # 1405
1405 ユーザ システム 経過
0.292 0.014 0.296
> system.time(cat(g(75319))) # 14133
14133 ユーザ システム 経過
25.996 4.104 29.849
> system.time(cat(g(90346))) # 16972
16972 ユーザ システム 経過
37.587 6.840 44.132
> system.time(cat(g(1e+05))) # 18797
18797 ユーザ システム 経過
46.327 8.617 54.652
しらみつぶしにするのではなく,ピタゴラス数のセットを計算によって求めたほうが探索範囲はせばまる。
ということで,最終的な答が以下のプログラム。
g = function(L) {
euclid = function(m, n) {
while ((temp = n%%m) != 0) {
n = m
m = temp
}
m == 1
}
eps = .Machine$double.eps
count = 0
for (m in seq_len(347)) { # 347
for (n in seq_len(m - 1)) {
if (euclid(n, m) && (m - n) %% 2 == 1) {
a = min(m^2 - n^2, 2 * m * n)
b = max(m^2 - n^2, 2 * m * n)
c = m^2 + n^2
if (b <= L) {
Rep = seq_len(L %/% b)
a = a * Rep
b = b * Rep
c = c * Rep
x = c/2
a2 = x + (a + c) * x / b
b2 = b * a2 / a
count = count + sum(a2 == floor(a2 + eps) & b2 == floor(b2 +
eps))
} else break
}
}
}
cat(count)
}
計算結果
> system.time(cat(g(100))) # 15
15 ユーザ システム 経過
0.026 0.002 0.020
> system.time(cat(g(456))) # 77
77 ユーザ システム 経過
0.005 0.000 0.005
> system.time(cat(g(7654))) # 1405
1405 ユーザ システム 経過
0.035 0.005 0.040
> system.time(cat(g(75319))) # 14133
14133 ユーザ システム 経過
0.319 0.007 0.318
> system.time(cat(g(90346))) # 16972
16972 ユーザ システム 経過
0.379 0.011 0.380
> system.time(cat(g(1e+05))) # 18797
18797 ユーザ システム 経過
0.413 0.007 0.410