








「Web ページからデータスクレイピング」の続き。
Web ページに,作表されたデータが表示されているとき,これを簡単に取り出すことができる。
1. R, Excel を立ち上げておく。
2. 目的のページを表示する
たとえば,
成人喫煙率(JT全国喫煙者率調査)
http://www.health-net.or.jp/tobacco/product/pd090000.html
を表示し,表の左上「年度」から表の右下「8.7」までのセルを,マウスドラッグで選択し,バッファにコピーする(command + c)。
3. Excel へペーストする。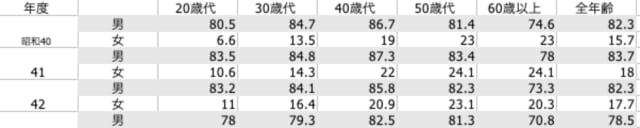
4. 表の本体,左上の 「20歳代」 から 右下の 「8.7」 までのセルを,マウスドラッグで選択し,バッファにコピーする(command + c)。
5. R のコンソールで,
data = read.table(pipe("pbpaste", "r"))
と入力する。
> head(data)
V1 V2 V3 V4 V5 V6
1 80.5 84.7 86.7 81.4 74.6 82.3
2 6.6 13.5 19.0 23.0 23.0 15.7
3 83.5 84.8 87.3 83.4 78.0 83.7
4 10.6 14.3 22.0 24.1 24.1 18.0
5 83.2 84.1 85.8 82.3 73.3 82.3
6 11.0 16.4 20.9 23.1 20.3 17.7
:
のようになる。
6. データは男女が交互になっているので,まず奇数行 data[1:54*2-1, ],次に偶数行 data[1:54*2, ] を取りだしたものを cbind() する。
data = cbind(data[1:54*2-1, ], data[1:54*2, ])
> head(data)
V1 V2 V3 V4 V5 V6 V1 V2 V3 V4 V5 V6
1 80.5 84.7 86.7 81.4 74.6 82.3 6.6 13.5 19.0 23.0 23.0 15.7
3 83.5 84.8 87.3 83.4 78.0 83.7 10.6 14.3 22.0 24.1 24.1 18.0
5 83.2 84.1 85.8 82.3 73.3 82.3 11.0 16.4 20.9 23.1 20.3 17.7
7 78.0 79.3 82.5 81.3 70.8 78.5 8.1 13.6 17.8 21.1 20.4 15.4
9 78.5 80.6 83.7 80.3 71.1 79.1 9.9 13.1 16.8 20.7 19.8 15.4
11 79.9 78.4 81.0 78.3 67.8 77.5 9.8 13.0 16.1 23.3 20.0 15.6
:
のようになる。
7. あとは,西暦年を列に付加するとか,変数名を付けるとか,どうしてもやりたければ整然データにするとか,どうにでも。
もう一つ例を挙げておく。
Wikipedia にある,「日本の自殺」の中の「自殺者数および人口10万人中の自殺率の推移」
これを上に書いたように範囲を指定してコピーし Excel などにペーストすると,数値のはいっているセルがだんだん右の方にズレている。
Excel ではなく,普通のエディタにペーストすればよい。数値がカンマで 3 桁区切りになっているので,全文置換でカンマを削除する。また,戦中のデータがないときの "" を NA に変換し,ヘッダー行を整えた後に,データ部分をバッファにコピーし,R で data = read.table(pipe("pbpaste", "r")) する。
ここでの教訓は,なんでもかんでもプログラム(特に tidyverse ?? なんか)に頼らないこと。得手不得手があるので,単純なエディタで十分な作業もあるんだということ。











