








1. Anscombe データセットの分析
Anscombe データセットは,記述統計学においてときどき言及されるものである。
4 組のデータ (x1, y1), (x2, y2), (x3, y3), (x4, y4) は,それぞれの変数の平均値,分散,二変数間の共分散,したがって相関係数も全て同じというものである。
# x1 x2 x3 x4 y1 y2 y3 y4
data = [
10 10 10 8 8.04 9.14 7.46 6.58
8 8 8 8 6.95 8.14 6.77 5.76
13 13 13 8 7.58 8.74 12.7 7.71
9 9 9 8 8.81 8.77 7.11 8.84
11 11 11 8 8.33 9.26 7.81 8.47
14 14 14 8 9.96 8.1 8.84 7.04
6 6 6 8 7.24 6.13 6.08 5.25
4 4 4 19 4.26 3.1 5.39 12.5
12 12 12 8 10.8 9.13 8.15 5.56
7 7 7 8 4.82 7.26 6.42 7.91
5 5 5 8 5.68 4.74 5.73 6.89
];
using DataFrames
df = DataFrame(data, [:x1, :x2, :x3, :x4, :y1, :y2, :y3, :y4])
using Statistics
[println("mean(x$i) = $(mean(df[:, i])), mean(y$i) = $(mean(df[:, 4+i]))") for i in 1:4];
[println("var(x$i) = $(var(df[:, i])), var(y$i) = $(var(df[:, 4+i]))") for i in 1:4];
[println("cov(x$i, y$i) = $(cov(df[:, i], df[:, 4+i])), cor(x$i, y$i) = $(cor(df[:, i], df[:, 4+i]))") for i in 1:4];
mean(x1) = 9.0, mean(y1) = 7.497272727272727
mean(x2) = 9.0, mean(y2) = 7.500909090909091
mean(x3) = 9.0, mean(y3) = 7.496363636363637
mean(x4) = 9.0, mean(y4) = 7.50090909090909
var(x1) = 11.0, var(y1) = 4.100701818181819
var(x2) = 11.0, var(y2) = 4.127629090909091
var(x3) = 11.0, var(y3) = 4.080845454545455
var(x4) = 11.0, var(y4) = 4.12324909090909
cov(x1, y1) = 5.489, cor(x1, y1) = 0.8172742068397078
cov(x2, y2) = 5.5, cor(x2, y2) = 0.8162365060002429
cov(x3, y3) = 5.481, cor(x3, y3) = 0.8180660798450472
cov(x4, y4) = 5.499, cor(x4, y4) = 0.8165214368885028
よく使われる統計量で見分けが付かなくても,これらを散布図で見れば,明らかな違いがある(fig1, fig2, fig3, fig4)。図に示した直線は回帰直線である。
using Plots
pyplot(grid=false, label="", xlabel="x", ylabel="y")
plt1 = scatter(df.x1, df.y1, smooth=true, title="fig1");
plt2 = scatter(df.x2, df.y2, smooth=true, title="fig2");
plt3 = scatter(df.x3, df.y3, smooth=true, title="fig3");
plt4 = scatter(df.x4, df.y4, smooth=true, title="fig4");
plt5 = scatter(df.y4, df.x4, smooth=true, xlabel="y", ylabel="x", title="fig5");
plot(plt1, plt2, plt3, plt4, plt5)

統計図の重要性を説くためのうってつけのデータセットである。
違いは確かにあるが,その先はどうするのかについてはあまり言及がない。予測という観点からデータを見てみよう。
1.1. fig2 は曲線相関である(2次曲線)ので,y = a + b x + c x^2 に当てはまる
using GLM
df.x_power2 = df.x1 .^ 2
result2 = lm(@formula(y2 ~ x2 + x_power2), df)
StatsModels.DataFrameRegressionModel{LinearModel{LmResp{Vector{Float64}}, DensePredChol{Float64, LinearAlgebra.Cholesky{Float64, Matrix{Float64}}}}, Matrix{Float64}}
Formula: y2 ~ 1 + x2 + x_power2
Coefficients:
──────────────────────────────────────────────────────
Estimate Std.Error t value Pr(>|t|)
──────────────────────────────────────────────────────
(Intercept) -5.99573 0.00432995 -1384.71 <1e-22
x2 2.78084 0.00104006 2673.74 <1e-24
x_power2 -0.126713 5.70977e-5 -2219.24 <1e-23
──────────────────────────────────────────────────────
予測値は完全に当てはまる。
scatter(df.x2, df.y2)
o = sortperm(df.x2)
xval = minimum(df.x2):0.05:maximum(df.x2)
predict2 = coef(result2)[1] .+ coef(result2)[2] .* xval + coef(result2)[3] .* xval .^2
plot!(xval, predict2)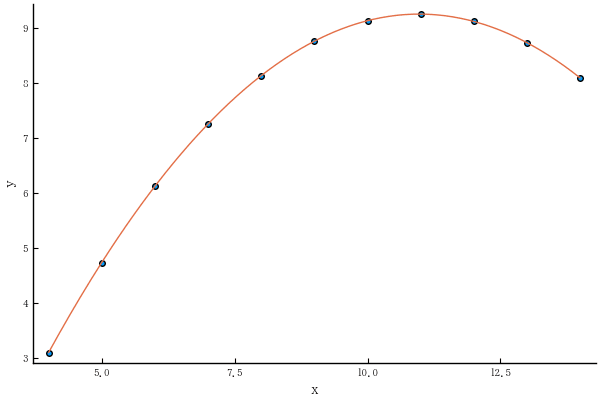
1.2. fig3 は,特異値があるので,ダミー変数を用いて当てはめができる
df.x3_dummy = df.x3 .== 13
result3 = lm(@formula(y3 ~ x3 + x3_dummy), df)
StatsModels.DataFrameRegressionModel{LinearModel{LmResp{Vector{Float64}}, DensePredChol{Float64, LinearAlgebra.Cholesky{Float64, Matrix{Float64}}}}, Matrix{Float64}}
Formula: y3 ~ 1 + x3 + x3_dummy
Coefficients:
─────────────────────────────────────────────────────
Estimate Std.Error t value Pr(>|t|)
─────────────────────────────────────────────────────
(Intercept) 4.00565 0.00292424 1369.81 <1e-22
x3 0.34539 0.000320591 1077.35 <1e-21
x3_dummy 4.20429 0.0035265 1192.2 <1e-21
─────────────────────────────────────────────────────
予測値は完全に当てはまる。
scatter(df.x3, df.y3)
o = sortperm(df.x3)
plot!(df.x3[o], predict(result3)[o])
1.3. fig4 は座標軸を入れ替えて,非線形関数に当てはめる
fig4 の x座標,y座標を入れ替えたものが fig5 である。回帰直線に当てはめるとどちらも同じようであるが,fig5 にロジスティック曲線を当てはめてみよう。
すなわち,図(データ)の解釈として,「従属変数 x は二値データ。独立変数 y が小さい内は反応がない(x=8)が,yが大きくなると反応が現れる(x = 19)」と考える。
なお,このままだと当てはめができないので,一点だけ変更する(下図の上に2点ある左の方)。
df.x4p = df.y4 .> 10
df.x4p[5] = 1
result4 = glm(@formula(x4p ~ y4), df, Binomial())
StatsModels.DataFrameRegressionModel{GeneralizedLinearModel{GlmResp{Vector{Float64}, Binomial{Float64}, LogitLink}, DensePredChol{Float64, LinearAlgebra.Cholesky{Float64, Matrix{Float64}}}}, Matrix{Float64}}
Formula: x4p ~ 1 + y4
Coefficients:
─────────────────────────────────────────────────────
Estimate Std.Error z value Pr(>|z|)
─────────────────────────────────────────────────────
(Intercept) -19.574 18.437 -1.06167 0.2884
y4 2.20803 2.20089 1.00324 0.3157
─────────────────────────────────────────────────────
予測曲線を描いてみるともっともらしく見えるようになる。
scatter(df.y4, df.x4p)
xval = minimum(df.y4):0.05:maximum(df.y4)
predict4 = 1 ./ (1 .+ exp.(-coef(result4)[1] .- coef(result4)[2] .* xval))
plot!(xval, predict4)
2. まとめ
以上のように,データの姿形,理論的背景をよく考えてモデルを構築する必要があるということだ。








