









日本語の豊富な造語能力は目を見張るものがありますがそれらは江戸期・明治期の先人の苦労によって支えられてきており、医学、哲学、工業技術、農業技術、法律などのさまざまな分野で役立てられました。
長い歴史の中で日本人が中国の漢字文化を模倣、吸収し、咀嚼しきってきたからこそ言語を越えた自由を獲得し、中国語の文法規則にも適うような造語も用いて近代にかけて作りあげていったため本家中国にも相当の数の和製漢語が採り入れられていったというのも明確な事実です。
こうした翻訳の産物である種々の言葉は近代文化のベースとなるだけではなく現在進行形の言葉の世界においてもいきいきと活躍しています。
そのなかでも使い勝手の良い漢語系接辞は応用範囲が広く日本語表現において欠かせないものとなっています。数が多すぎてここでは全部紹介しきれませんが手近なところをいくつか挙げたいと思います。
【接頭語の例】
非・不・無・反・本・抗・未・脱・汎・各・高・低・重・軽・長・短・超・正・被・元・現・対・誤・試・過・再・最・前・新・旧・全・準・純・激・名・怪
【接尾語の例】
法・的・化・式・状・然・用・系・中・内・性・度・値・期・機・制・製・先・派・風・流・説・上・下・人・者・家・場・所・調・力・界・型・感・点・観
三属性変換の第三の属性、属性ハではこうした接頭語・接尾語を含む言葉の変換が割り当てられており、字面ではわかるものの発音としては同音で混同しやすい例も多く通常の名詞(属性イ)あるいは用言(属性ロ)などとは独立した別物の扱いとすることで多少は変換目的にあった語句の認識ができていると思います。
またこうした接辞は1音2音の短いパーツが多く従来のIMEでは誤変換に悩まされる要因となるものでした。
(例)「か」と「化」「下」、「き」と「期」、「し」と「氏」「かく」と「各」など
もっともこれで万能というわけではなく、特に「し」など「氏・誌・士・死・師・詩・市」のように続くバリエーションが爆発的に多岐にわたる例もあるのでどれだけ有効なのかはうかがい知れませんが、
◆さとうし=佐藤氏・どうじんし=同人誌・えいようし=栄養士・ふしんし=不審死・ほめいにし=ホメイニ師・じょじし=叙事詩・ひだし=飛騨市
などのようにひとつづきの単語になったときには識別されやすく、”属性ハ”という付加情報があることでかなり適切に変換するのが助けられると思います。
悩ましかった「化」の誤変換ともおさらばできるのは非常に大きいです。IMEにとっては「化」の誤変換もしたくてしているわけではなく、-化と続く言葉がいつでてきてもおかしくないため常に「化」が頻発してしまうIMEの「力み」みたいなものもある程度理解はできるのですが、この方法であれば「力み」からすっかり解放されて属性ハの指定があれば素直に-化で変換することができます。
逆に素のままの「-か」にしたいときは特に何も指定しなければいいだけなので使い分けの仕方もシンプルでわかりやすいです。多少手がかかるのは「-下」としたい語句があるときは選択しなければならないことぐらいですがこれでもトータルでみたら随分と改善されていると思います。
さらに発展して「-状態」「-現象」「-テイスト」「プチ-」などの少し長めの接頭語・接尾語(に準ずるもの?)なども三属性変換が役立つ場面があるかもしれません。
どちらかというと細切れ変換あるいは単発の語句での変換にも好都合ですが、長文一括変換時にもこうした三属性変換を如何にして有効的になじませていくか、タイミングはその都度三属性情報を投げていくのか仮変換後の修正に注力していく方法のほうがいいのかうまくいきそうなスタイルをいろいろ考えてみるのも必要なことだと思います。
長い歴史の中で日本人が中国の漢字文化を模倣、吸収し、咀嚼しきってきたからこそ言語を越えた自由を獲得し、中国語の文法規則にも適うような造語も用いて近代にかけて作りあげていったため本家中国にも相当の数の和製漢語が採り入れられていったというのも明確な事実です。
こうした翻訳の産物である種々の言葉は近代文化のベースとなるだけではなく現在進行形の言葉の世界においてもいきいきと活躍しています。
そのなかでも使い勝手の良い漢語系接辞は応用範囲が広く日本語表現において欠かせないものとなっています。数が多すぎてここでは全部紹介しきれませんが手近なところをいくつか挙げたいと思います。
【接頭語の例】
非・不・無・反・本・抗・未・脱・汎・各・高・低・重・軽・長・短・超・正・被・元・現・対・誤・試・過・再・最・前・新・旧・全・準・純・激・名・怪
【接尾語の例】
法・的・化・式・状・然・用・系・中・内・性・度・値・期・機・制・製・先・派・風・流・説・上・下・人・者・家・場・所・調・力・界・型・感・点・観
三属性変換の第三の属性、属性ハではこうした接頭語・接尾語を含む言葉の変換が割り当てられており、字面ではわかるものの発音としては同音で混同しやすい例も多く通常の名詞(属性イ)あるいは用言(属性ロ)などとは独立した別物の扱いとすることで多少は変換目的にあった語句の認識ができていると思います。
またこうした接辞は1音2音の短いパーツが多く従来のIMEでは誤変換に悩まされる要因となるものでした。
(例)「か」と「化」「下」、「き」と「期」、「し」と「氏」「かく」と「各」など
もっともこれで万能というわけではなく、特に「し」など「氏・誌・士・死・師・詩・市」のように続くバリエーションが爆発的に多岐にわたる例もあるのでどれだけ有効なのかはうかがい知れませんが、
◆さとうし=佐藤氏・どうじんし=同人誌・えいようし=栄養士・ふしんし=不審死・ほめいにし=ホメイニ師・じょじし=叙事詩・ひだし=飛騨市
などのようにひとつづきの単語になったときには識別されやすく、”属性ハ”という付加情報があることでかなり適切に変換するのが助けられると思います。
悩ましかった「化」の誤変換ともおさらばできるのは非常に大きいです。IMEにとっては「化」の誤変換もしたくてしているわけではなく、-化と続く言葉がいつでてきてもおかしくないため常に「化」が頻発してしまうIMEの「力み」みたいなものもある程度理解はできるのですが、この方法であれば「力み」からすっかり解放されて属性ハの指定があれば素直に-化で変換することができます。
逆に素のままの「-か」にしたいときは特に何も指定しなければいいだけなので使い分けの仕方もシンプルでわかりやすいです。多少手がかかるのは「-下」としたい語句があるときは選択しなければならないことぐらいですがこれでもトータルでみたら随分と改善されていると思います。
さらに発展して「-状態」「-現象」「-テイスト」「プチ-」などの少し長めの接頭語・接尾語(に準ずるもの?)なども三属性変換が役立つ場面があるかもしれません。
どちらかというと細切れ変換あるいは単発の語句での変換にも好都合ですが、長文一括変換時にもこうした三属性変換を如何にして有効的になじませていくか、タイミングはその都度三属性情報を投げていくのか仮変換後の修正に注力していく方法のほうがいいのかうまくいきそうなスタイルをいろいろ考えてみるのも必要なことだと思います。
文節の切れ目の解析という難題をカジュアルに解決して見せた…かにみえた「でにをは別口入力」ですが思ったよりオールマイティではなく基本的な言い回しもうまくカバーできていないなどの問題が出てきます。
例えば別口入力「で」は少々厄介で、様々な用法のものがありながらそれらをひとくくりに別口入力「で」で区切り目情報の付加をしています。それらの用法をひとつひとつ検討していくと、
1.格助詞としての「で」…場所/場面・手段/材料・原因/理由・コスト/時間・動作作用の行われる状態(例:疲労困憊で訪問する)・動作作用を行う主体となる組織団体(例:自治体でPRする) など
2.形容動詞の連用形の一部としての「で」…(例)優雅で、微妙で、タイトで
3.断定の助動詞「だ」の連用形として…であるの形で
4.伝聞の助動詞「そうだ」の連用形の一部として…そうであるの形で
5.たとえの助動詞「ようだ」の連用形の一部として…ようであるの形で
のような用法があり「でにをは別口入力」において使われます。「~べきである」なども同様だと思われます。
これらとは別に
別1.接続助詞「て」の濁ったもの…(例)お湯を注いで三分待つ
別2.副詞の一部である「で」…(例)まるで石油王みたいだ
これらはまぎらわしいですが「でにをは別口入力」には使われませんので注意が必要です。
ここまで「で」にまつわることを解説していきましたが、格助詞、形容動詞、助動詞と様々な用法のものを「で」キー一つでとりまわしていくのはなかなか一筋縄ではいかなそうです。
翻ってよく使われる言い回しの「です」「でした」の扱いに焦点をおいてみます。(「である」は「で」の解説中に出てきたのでひとまず置いておきます)
断定の助動詞「だ」の丁寧な形の「です」の活用は
◆「です」(丁寧な断定)
【未然形】でしょ
【連用形】でし
【終止形】です
【連体形】(です)
【仮定形】○・・・ありません
【命令形】○・・・ありません
となっており、断定の助動詞としての接続は体言や一部の助詞(例:古いのです)につきますが、丁寧語全般の用法としては大方の品詞に接続できるもののようです。(でしょう含む)
(「かわいいです」などのような形容詞+ですなどは当初は違和感があったかもしれないが昭和27年の国語審議会で認められており今では誤用とはいえない)
もちろん断定の助動詞だけでなく「でにをは」まわりで使われる形容動詞の活用語尾のですも同様です(【仮定形】「ですれ」がカッコつきで稀ではあるが存在するとあります)
この辺でなんだかモヤモヤするのは別口入力「だ」は終止形に限るとしており「だろ」(未然形)「だっ」(連用形)「なら」(仮定形)は別口入力につながらないという不明瞭さが脳裏によぎってくることです。
この問題と同様に「でしょ」「でし」「です」も「で」単体の区切りがあまりに良いものなので蔑ろにされている感があります。
確かに「である調」の文体においては問題なさそうですが「ですます調」の文体を書き進めていく上では大変具合が悪いです。
何か良い解決方法はないでしょうか?…思いつく限りでは下記の方策くらいしかでてきませんが一応記しておきます。
・[R][r]のル動詞の別口入力の考え方を拡張して
です→[で][R] <終止形>
でしょう→[で][r]う <未然形>+<推量の助動詞「う」>
でした→[で][r]た <連用形>+<過去の助動詞「た」>
でして→[で][r]て <連用形>+<原因/理由の接続助詞「て」>
のようにワイルドカード的に入力して語尾変化に対応する方法が考えられる。
※この方法をつかうにあたっては、別口入力[R][r]としてあったが、ル形動詞以外にも適用されるということなのでR(アール)にこだわらずともよく、ワイルドカードとして仮に○や×などの記号を用いたほうが適当ではないかとの考えに至るものである。(要検討課題)
※別口入力に煩わされて特異な入力をユーザーに強いるのも申し訳ないので、別口入力を用いずプレーンに(です・でした・でしょう)を入力してもどちらでも対応できるように文字列を柔軟に解析し、たとえ気まぐれに入力スタイルがその時々でまちまちであっても許容して解釈するような設計が求められる。
例えば別口入力「で」は少々厄介で、様々な用法のものがありながらそれらをひとくくりに別口入力「で」で区切り目情報の付加をしています。それらの用法をひとつひとつ検討していくと、
1.格助詞としての「で」…場所/場面・手段/材料・原因/理由・コスト/時間・動作作用の行われる状態(例:疲労困憊で訪問する)・動作作用を行う主体となる組織団体(例:自治体でPRする) など
2.形容動詞の連用形の一部としての「で」…(例)優雅で、微妙で、タイトで
3.断定の助動詞「だ」の連用形として…であるの形で
4.伝聞の助動詞「そうだ」の連用形の一部として…そうであるの形で
5.たとえの助動詞「ようだ」の連用形の一部として…ようであるの形で
のような用法があり「でにをは別口入力」において使われます。「~べきである」なども同様だと思われます。
これらとは別に
別1.接続助詞「て」の濁ったもの…(例)お湯を注いで三分待つ
別2.副詞の一部である「で」…(例)まるで石油王みたいだ
これらはまぎらわしいですが「でにをは別口入力」には使われませんので注意が必要です。
ここまで「で」にまつわることを解説していきましたが、格助詞、形容動詞、助動詞と様々な用法のものを「で」キー一つでとりまわしていくのはなかなか一筋縄ではいかなそうです。
翻ってよく使われる言い回しの「です」「でした」の扱いに焦点をおいてみます。(「である」は「で」の解説中に出てきたのでひとまず置いておきます)
断定の助動詞「だ」の丁寧な形の「です」の活用は
◆「です」(丁寧な断定)
【未然形】でしょ
【連用形】でし
【終止形】です
【連体形】(です)
【仮定形】○・・・ありません
【命令形】○・・・ありません
となっており、断定の助動詞としての接続は体言や一部の助詞(例:古いのです)につきますが、丁寧語全般の用法としては大方の品詞に接続できるもののようです。(でしょう含む)
(「かわいいです」などのような形容詞+ですなどは当初は違和感があったかもしれないが昭和27年の国語審議会で認められており今では誤用とはいえない)
もちろん断定の助動詞だけでなく「でにをは」まわりで使われる形容動詞の活用語尾のですも同様です(【仮定形】「ですれ」がカッコつきで稀ではあるが存在するとあります)
この辺でなんだかモヤモヤするのは別口入力「だ」は終止形に限るとしており「だろ」(未然形)「だっ」(連用形)「なら」(仮定形)は別口入力につながらないという不明瞭さが脳裏によぎってくることです。
この問題と同様に「でしょ」「でし」「です」も「で」単体の区切りがあまりに良いものなので蔑ろにされている感があります。
確かに「である調」の文体においては問題なさそうですが「ですます調」の文体を書き進めていく上では大変具合が悪いです。
何か良い解決方法はないでしょうか?…思いつく限りでは下記の方策くらいしかでてきませんが一応記しておきます。
・[R][r]のル動詞の別口入力の考え方を拡張して
です→[で][R] <終止形>
でしょう→[で][r]う <未然形>+<推量の助動詞「う」>
でした→[で][r]た <連用形>+<過去の助動詞「た」>
でして→[で][r]て <連用形>+<原因/理由の接続助詞「て」>
のようにワイルドカード的に入力して語尾変化に対応する方法が考えられる。
※この方法をつかうにあたっては、別口入力[R][r]としてあったが、ル形動詞以外にも適用されるということなのでR(アール)にこだわらずともよく、ワイルドカードとして仮に○や×などの記号を用いたほうが適当ではないかとの考えに至るものである。(要検討課題)
※別口入力に煩わされて特異な入力をユーザーに強いるのも申し訳ないので、別口入力を用いずプレーンに(です・でした・でしょう)を入力してもどちらでも対応できるように文字列を柔軟に解析し、たとえ気まぐれに入力スタイルがその時々でまちまちであっても許容して解釈するような設計が求められる。
みなさんは細切れ変換派でしょうかそれとも長文一括変換派でしょうか。昨今のIMEには複数の文節の区切りを自動的に決定し入力効率を高める連文節変換が標準で搭載されているものが主流でありせっかくの機能を活かしきれないのは非常にもったいないのですが、自分も言う割にあまり活用できていないのが現状です。
なかなか一括変換を常用するまでに至らないのは、誤変換にまつわるデメリットをつい心配してしまうから踏み込めないのかもしれません。
理想としてはひと続きの長い文章を一気に変換するとき、うまくいったときの爽快感はなかなかのものです。しかし、思うような変換にならず面倒な修正作業を強いられるのは厄介で思考も中断されてしまいますし、しまいには書こうとしていたことを忘れてしまったりしてダメージが大きな事態となってしまい煩わしい事この上ないものです。こうしたことが続くと地道に逐次変換していく方がかえって賢明ではないかと割り切れないながらも身についてしまっているのだと言えます。
ペンタクラスタキーボードにおける入力文には、でにをは別口入力で入力された助詞や助動詞などのパーツが未変換文字列中に内包されており、変換の際にはこれらのマーキング情報が入力文の解析に役立てられます。
ここで重要なのは「でにをは」等助詞助動詞をいくつか入力していてもなお、最終的に変換キーを押すまではでにをは情報はいったん宙に浮いたまま変換プロセスが依然継続しているということです。
世間一般のIME使用時の入力場面ではひとつふたつ助詞・助動詞の現れた区切り目で細切れ変換をしている例が多いかと思われますが、ペンタクラスタキーボード使用時は潜在的に文の区切りを別入力しているという期待感から変換のタイミングのスパンが大きくなる、もしくはしたくなるように仕向けて行こうという目論見があります。
これは実際やってみないとわからないものですが、細切れ変換派の方でも長文変換を任せてもらえるような信頼感を得られるようにしていくことが非常に大切だと思います。
こちらの魂胆としては、でにをは別口入力を伴った連文節変換は区切り情報がはっきりしているので適切な文節区切りを得ることができ通常の連文節変換よりも変換精度が高いはずであろうとの仮説があります。
それによってユーザーが長文一括変換を選択してもらえるような誘因となって自然にリスクを気にせず連文節変換をすることがだんだんと習慣になっていくことが究極の目標です。
つまるところ変換エンジンの解析の出来が成否を左右すると思われますが、これがでにをは別口入力と組み合わさったときの挙動を正確に見極める必要があると思います。
別口入力について細かい所をいうと助詞は一文字のものばかりではなく[ので][とは]などの複合助詞があったり、[から][まで][しか]など二文字以上の助詞もありさらにはそれらが単体の[か][で]などの接続と混同・干渉しないように判定を明確にしていかなければなりません。
「でにをは別口入力」の作用副作用、解析時においての振る舞いなど今一度掘り下げていくことがさらに必要になりそうです。
なかなか一括変換を常用するまでに至らないのは、誤変換にまつわるデメリットをつい心配してしまうから踏み込めないのかもしれません。
理想としてはひと続きの長い文章を一気に変換するとき、うまくいったときの爽快感はなかなかのものです。しかし、思うような変換にならず面倒な修正作業を強いられるのは厄介で思考も中断されてしまいますし、しまいには書こうとしていたことを忘れてしまったりしてダメージが大きな事態となってしまい煩わしい事この上ないものです。こうしたことが続くと地道に逐次変換していく方がかえって賢明ではないかと割り切れないながらも身についてしまっているのだと言えます。
ペンタクラスタキーボードにおける入力文には、でにをは別口入力で入力された助詞や助動詞などのパーツが未変換文字列中に内包されており、変換の際にはこれらのマーキング情報が入力文の解析に役立てられます。
ここで重要なのは「でにをは」等助詞助動詞をいくつか入力していてもなお、最終的に変換キーを押すまではでにをは情報はいったん宙に浮いたまま変換プロセスが依然継続しているということです。
世間一般のIME使用時の入力場面ではひとつふたつ助詞・助動詞の現れた区切り目で細切れ変換をしている例が多いかと思われますが、ペンタクラスタキーボード使用時は潜在的に文の区切りを別入力しているという期待感から変換のタイミングのスパンが大きくなる、もしくはしたくなるように仕向けて行こうという目論見があります。
これは実際やってみないとわからないものですが、細切れ変換派の方でも長文変換を任せてもらえるような信頼感を得られるようにしていくことが非常に大切だと思います。
こちらの魂胆としては、でにをは別口入力を伴った連文節変換は区切り情報がはっきりしているので適切な文節区切りを得ることができ通常の連文節変換よりも変換精度が高いはずであろうとの仮説があります。
それによってユーザーが長文一括変換を選択してもらえるような誘因となって自然にリスクを気にせず連文節変換をすることがだんだんと習慣になっていくことが究極の目標です。
つまるところ変換エンジンの解析の出来が成否を左右すると思われますが、これがでにをは別口入力と組み合わさったときの挙動を正確に見極める必要があると思います。
別口入力について細かい所をいうと助詞は一文字のものばかりではなく[ので][とは]などの複合助詞があったり、[から][まで][しか]など二文字以上の助詞もありさらにはそれらが単体の[か][で]などの接続と混同・干渉しないように判定を明確にしていかなければなりません。
「でにをは別口入力」の作用副作用、解析時においての振る舞いなど今一度掘り下げていくことがさらに必要になりそうです。
意味属性という切り口から望んだ語句の変換に素早くアプローチする三属性変換の特質として、短い語句の変換に機動的に対応できるという利点がありますが、長文を含む複数文節の一括変換はとても重要だと認識しています。確かに検索ワードの入力やファイル名フォルダ名の入力に威力を発揮しますが、日本語入力と名のつくものには長文の精度の高い変換は必須のものであり、決して軽視してはおりません。
でにをは別口入力の良さを存分に出せるのはむしろ一括変換の変換過程において発揮できるものであるということを強調したいと思います。
ただアプローチ方法が違います。従来の長文変換の処理過程では、形態素解析で要素をひとつひとつ取り出して品詞間の接続や単語そのものの接続しやすさなどを計算したり、時には意味解析や文脈解析などの高いレイヤーの処理を伴ったりしながら順を追ってプロセスを積み上げていき、一気に変換キー一発で目的の変換文に落とし込むという、シンプルでわかりやすい方法が提示されていますが、
ペンタクラスタキーボードにおいては端的に長文入力後の変換キー操作の一点に収束させるのではなく、でにをは別口入力で形態素を成形し準備立てるプロセスがあったり、≪≫キーで語句のかたまり間を移動して三属性変換をほどこし後から訂正しやすくしたり、まず最初は通常変換で無難な(冒険的でない)変換を試みて第二段階でユニークな部分の変換に移行するという形をとっています。
これは変換確定前後にわたって諸所に用意された重層的なプロセスで変換操作の対話性を重視したインターフェイスであり、仮に正解の語句変換が成功しなかったとしても違和感なく修正過程に自然と移行させる構図ができあがっています。
常に途切れることなく変換フェイズに関与しているという心理的効果があるとともに、ヒントを随時問いかけて正解に近づけていく数当てゲームのようなやりとりに似ているスタイルであり、ユーザーは最初は戸惑うかもしれませんが、終始このスタイルが貫徹されていることに慣れていけば、これはこれで一つのスタイルだな…と飲み込んで消化できるものとなっていると思います。
正解を出すための作業も大事ですが、かな漢字変換に誤変換はつきものですので、失敗したときの挽回策を手厚く用意することもユーザーの利便性のために必要なことであると考えます。
でにをは別口入力の良さを存分に出せるのはむしろ一括変換の変換過程において発揮できるものであるということを強調したいと思います。
ただアプローチ方法が違います。従来の長文変換の処理過程では、形態素解析で要素をひとつひとつ取り出して品詞間の接続や単語そのものの接続しやすさなどを計算したり、時には意味解析や文脈解析などの高いレイヤーの処理を伴ったりしながら順を追ってプロセスを積み上げていき、一気に変換キー一発で目的の変換文に落とし込むという、シンプルでわかりやすい方法が提示されていますが、
ペンタクラスタキーボードにおいては端的に長文入力後の変換キー操作の一点に収束させるのではなく、でにをは別口入力で形態素を成形し準備立てるプロセスがあったり、≪≫キーで語句のかたまり間を移動して三属性変換をほどこし後から訂正しやすくしたり、まず最初は通常変換で無難な(冒険的でない)変換を試みて第二段階でユニークな部分の変換に移行するという形をとっています。
これは変換確定前後にわたって諸所に用意された重層的なプロセスで変換操作の対話性を重視したインターフェイスであり、仮に正解の語句変換が成功しなかったとしても違和感なく修正過程に自然と移行させる構図ができあがっています。
常に途切れることなく変換フェイズに関与しているという心理的効果があるとともに、ヒントを随時問いかけて正解に近づけていく数当てゲームのようなやりとりに似ているスタイルであり、ユーザーは最初は戸惑うかもしれませんが、終始このスタイルが貫徹されていることに慣れていけば、これはこれで一つのスタイルだな…と飲み込んで消化できるものとなっていると思います。
正解を出すための作業も大事ですが、かな漢字変換に誤変換はつきものですので、失敗したときの挽回策を手厚く用意することもユーザーの利便性のために必要なことであると考えます。
この記事では変換インターフェイスの中でも頻繁に出てくる場面の多い、変換文節におけるカーソル移動操作についてと、[かな][カナ]キーでの変換について解説します。

キーボード下部の丸型四角形のキーの中でかな/カナ/≪≫と表示のあるえんじ色でひときわ目立つキーが左側にあります。
刻印されている≪≫(二重の不等号)キーのはたらきは、通常のIMEにおいて←→でおこなっている文節間の移動(下線部の区切りを移動)とほぼ同じ機能を持つキーでこれを左右に動かすことによって変換語句のかたまりを移動して指定します。
通常の←→での注目文節間の移動と少し違うのは、別口入力によって助詞の区切りがある程度断片化されているのでワードの指定範囲を移動するときに「でにをは」その他助詞を抜かした形で飛び石のように指定範囲が選択されるという点が特徴で、文節を伸ばしたり縮めたりする操作のときには普通の矢印キーを使って調整します。
≪≫の左右移動と←→の左右移動の二段構えでカーソル移動をするので、Shift+←のような同時押しの操作がない分カーソル・区切りの移動がすっきりと行えると思いますし、区切り位置をもし間違ってしまってもあとから仕切り直すのがスムーズに行えるのが利点です。
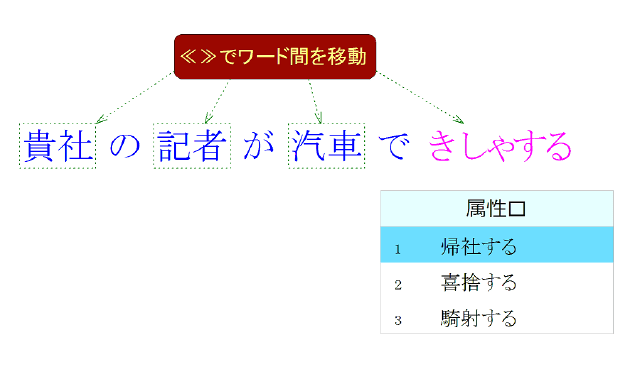
三属性変換との連携操作では、≪≫で「でにをは」等助詞を飛び越えつつワード間を移動して、それぞれの変換語句で三属性変換イ・ロ・ハのどれかを押せば指定した属性の語句へ(図の場合は属性ロ:用言・動詞など)変換されます。
これらは主に漢字の語句(送りがな付きを含む)あるいは漢字とひらがな・カタカナの混在した語句へ変換されます。さらに別口入力「な」(形容動詞の連体形)や「だ」(断定の助動詞・形容動詞の終止形)が挟む場合には「な」や「だ」はひらがなのままで、残りの字種はその語句の表記したい形(漢字・ひらがな・カタカナ)に適宜変換されます。
これは[かな][カナ]キーで変換するときも同様で各種助詞・助動詞・語尾部分はひらがなのままで、注目語句はカタカナなどに変換されます。
(例)シリアスな ファンキーだ
なお[カナ]キーで変換する際、1回押すと全角カナ、2回押すと半角カナへ変換されるようにすると順当でわかりやすいかと思います。
通常の環境であればF6・F7・F8を押して変換する(時にはFnキー同時押しの場合もある)ところをキーボード盤面中央付近の押しやすいところに配置しており、習慣的見地から見ても配慮の行き届いたものとなっています。
日常的動作なので押しやすい位置にキーが配置してあることは重要ですね。
キーボード下部の丸型四角形のキーの中でかな/カナ/≪≫と表示のあるえんじ色でひときわ目立つキーが左側にあります。
刻印されている≪≫(二重の不等号)キーのはたらきは、通常のIMEにおいて←→でおこなっている文節間の移動(下線部の区切りを移動)とほぼ同じ機能を持つキーでこれを左右に動かすことによって変換語句のかたまりを移動して指定します。
通常の←→での注目文節間の移動と少し違うのは、別口入力によって助詞の区切りがある程度断片化されているのでワードの指定範囲を移動するときに「でにをは」その他助詞を抜かした形で飛び石のように指定範囲が選択されるという点が特徴で、文節を伸ばしたり縮めたりする操作のときには普通の矢印キーを使って調整します。
≪≫の左右移動と←→の左右移動の二段構えでカーソル移動をするので、Shift+←のような同時押しの操作がない分カーソル・区切りの移動がすっきりと行えると思いますし、区切り位置をもし間違ってしまってもあとから仕切り直すのがスムーズに行えるのが利点です。
三属性変換との連携操作では、≪≫で「でにをは」等助詞を飛び越えつつワード間を移動して、それぞれの変換語句で三属性変換イ・ロ・ハのどれかを押せば指定した属性の語句へ(図の場合は属性ロ:用言・動詞など)変換されます。
これらは主に漢字の語句(送りがな付きを含む)あるいは漢字とひらがな・カタカナの混在した語句へ変換されます。さらに別口入力「な」(形容動詞の連体形)や「だ」(断定の助動詞・形容動詞の終止形)が挟む場合には「な」や「だ」はひらがなのままで、残りの字種はその語句の表記したい形(漢字・ひらがな・カタカナ)に適宜変換されます。
これは[かな][カナ]キーで変換するときも同様で各種助詞・助動詞・語尾部分はひらがなのままで、注目語句はカタカナなどに変換されます。
(例)シリアスな ファンキーだ
なお[カナ]キーで変換する際、1回押すと全角カナ、2回押すと半角カナへ変換されるようにすると順当でわかりやすいかと思います。
通常の環境であればF6・F7・F8を押して変換する(時にはFnキー同時押しの場合もある)ところをキーボード盤面中央付近の押しやすいところに配置しており、習慣的見地から見ても配慮の行き届いたものとなっています。
日常的動作なので押しやすい位置にキーが配置してあることは重要ですね。





