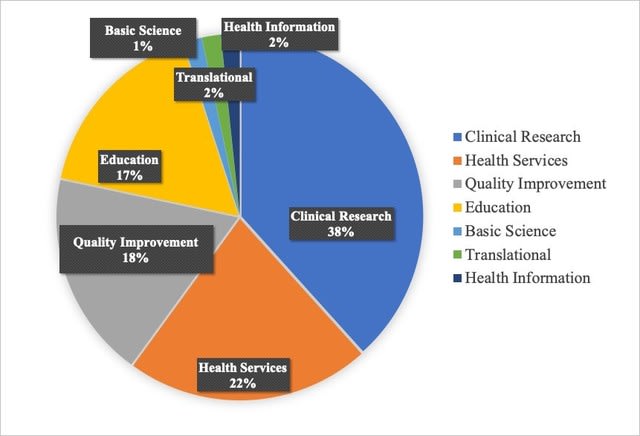
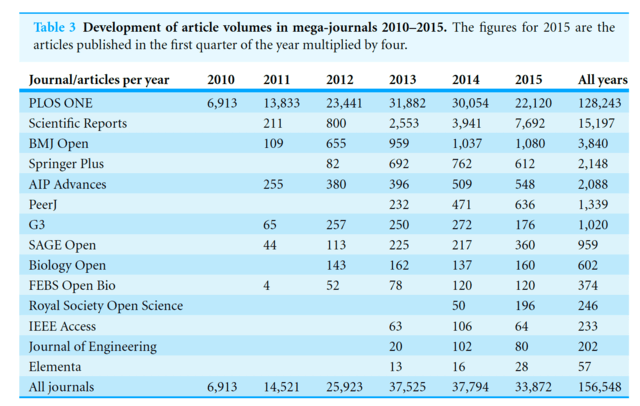
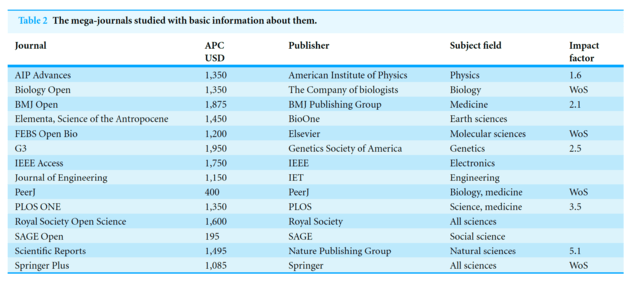
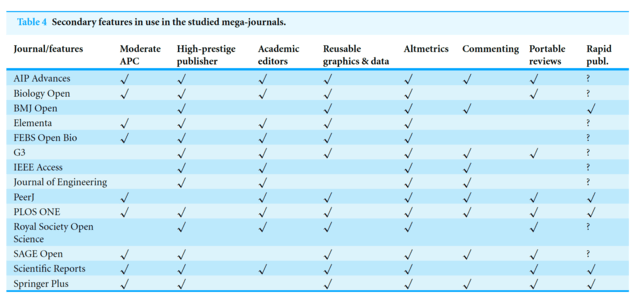
みなさまこんにちわ。
最近は、本当にCOVID-19 pandemicで本当に人生が翻弄されています。
しかしながら、プロフェッショナル大学院の進行状況は緩められることなく爆烈な課題量やケースの読み込みによる消化不良と毎日の炎上と、自分がやってきた仕事や研究も全てパラレルにコミットしなければならないわけで、本当に一つのことだけ集中できればいいなぁと実は嘆いていました。しかし、この年齢で勉強し続けれられることは本当にラッキーで、ありがたいことで、新しい発見があると最近ようやくWeChatで仲良くなった北京の女性医師と学んだことをやりとりしてます。時差も近いし、電話も時々できますし。
さて、今日は教科書を読んでふとまとめてみました。
僕は、STATAやSPSS、RCTなどの平均差などで簡単な場合は携帯のアプリ(medical calculatorなど)、
パッと早く計算したい場合はOpen epiを用いていましたが。自分が勘違いしていたところを多々あるので、
https://www.openepi.com/Menu/OE_Menu.htm
(こちらが医学生や若手の先生に教えるときのサイトです)
きっと皆様にもお役に立つのではないかと感じてノートを残しておきます。
元文献はHulley, Stephen B. Designing Clinical Research (pp.70-72). LWW.と言うHarvard Medical Schoolで用いられている臨床研究デザインの教科書です。とっても簡単な英語でわかりやすいです。
また、サンプルサイズの計算で原理原則の基本的なところは、今はもうYoutubeでやまほどありますので、Sample size AND calculationでググるとどんどんでてきます。
計算のための情報がたりない??場合のサンプルサイズの計算方法:
1先行研究の読み込み・・研究課題に関する過去の知見や関連する知見を徹底的に検索する。ほとんどがココ・大まかに比較可能な状況や、平凡でも、古くても十分である。
2本当に計算に使える情報がない場合・・小規模なパイロット研究を実施:パイロット研究は、さらに研究者が本試験の計画をよりよく練ることができるため最終的には時間の節約になり理にかなっている。
3正規分布で連続変数の場合・・標準偏差は一般的に発生する値の範囲の高端と低端の差の4分の1として推定することを利用する方法もある。Normal distribution であるDataであるかどうか。
4その連続またはカテゴリカル変数の平均と標準偏差が疑わしい場合、その変数を中央値/平均値で半分に分割して、Chi2検定へ落とし込む。この場合、多少高く見積もられる。
5臨床的な効果に基づき見積もる・・最終手法の一つなので研究者はその選択を専門家の同僚と一緒に吟味を。(例:ある研究者が重度の難治性胃穿孔症に対する新しい侵襲的治療法を研究しているとすると、この治療法は患者のせいぜい5%が自然に改善する状態とする。ある治療法が有効であることが示された場合(治療に必要な数NNTが5人とする)であれば、リスク差は20%(NNT = 1/リスク差)なので治験責任医師はP1 = 5%対P2 = 25%の比較に基づいてサンプルサイズを推定(だいたい0.80の検出力と0.05の両側αで各群約60人程度になる)。
6最終手段:欠落している成分の可能性の高い値について経験に基づいた推測から導く。これは通常、何の科学的根拠もない、例えば2群間で0.5の標準化されたEffect sizeを検出するために、両側α0.05で80%の検出力を持つように逆算で研究を設計(ちなみにこの場合は1群あたりのn = 64)。この教科書ではこのような完全に恣意的なサンプルサイズ計算を受け入れる科研費助成金はほとんどないと。
サンプルサイズ計算でよくある恥ずかしい間違い!
1. よくあるエラーは、研究の設計中にサンプルサイズを遅い段階で見積もることである。根本的な変更がまだ可能なときにかなり早い段階で行うことから始める。
2. Dichotomus dataがパーセンテージ(%)で表現されている場合、連続変数のように見えて。例)死亡,0 or 1は生存率で表現すると連続変数と誤解されて計算される。生存分析でも結果が連続変数のように勘違いしやすい(例えば、月単位での生存期間の中央値)。これらすべてにおいて、結果自体は実際にはBinary data(割合)であり、標本サイズを計画する際の適切な単純なアプローチはカイ二乗検定となる。
3. サンプルサイズははOutcomeの被験者の数を推定するものであり研究に必要な標本数ではない。Drop outやmissing dataを加味して計算する。
4. 研究対象となる2つのグループのサンプルサイズが等しいと仮定。多くの場合、研究ではそうではないことが多い. サンプル数数が等しくない場合は、ウェブや統計ソフトの表や計算機に記載されている計算式を使用。
5. アウトカム変数の標準偏差を因子として用いていない。標本サイズを推定するためにt検定を使用する場合、アウトカムが連続変数の変化である場合には変数自体の標準偏差ではなく、その変化の標準偏差を用いるべきである。
6. クラスター化されたデータは必ずしも均一でないことに注意。標本サイズのクラスタリングは問題である可能性が高い。
7. それでも研究のための標本サイズの推定が困難な場合は、研究仮説とデザインから見直す。
*Hulley, Stephen B.. Designing Clinical Research (pp.70-72). LWW.