








みなさまこんにちわ。
今日は、Quality improvementの研究でもっとも大事だと思う(勝手に思っている)内容ですね。だって現場の感覚に沿っているので。
この辺りは、EpidemiologyとBiostatisticsの基本がないと難しいのですが、僕の場合はGCSRT時代に"津川先生のブログ"で昔勉強しました。なかなか、日本語でわかりやすく書いてある本質的な内容がないところを、津川先生のブログは神です。僕もGeneralisitが病院でQIをシンプルに勉強したい人が出てくるかもしれないことを考えて、やはり日々の感動や驚きはOutputし続けなえればならないと思います。
そもそもHarvardのEpidemiologyとBiostatisticsのコンセプトはだいたい同じなので、津川先生が書いてくださっている内容は不思議とだいたいテストや課題のポイントになってドカドカ出されます。恐ろしいくらいの的中率です。津川先生、お会いしたことはないですが、勝手に尊敬しています!!
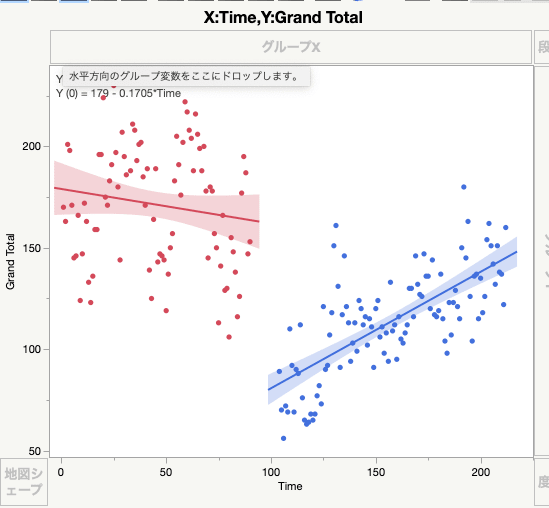
さて、INTERRUPTED TIME SERIES (ITS) ANALYSIS USING SEGMENTED REGRESSIONは上記のように簡単にJMPでFigureを作れそうです。僕はSTATAが好きですが、Visualizeする場合はどうしてもJMPに軍配が上がりそうです。
さてQUASI EXPERIMENTAL STUDY DESIGNS基本的な考え方としては、”A study design used to estimate the causal effect of a non-randomized intervention on an outcome in a target population”になります。ここ大事です。何でもかんでもRCT!RCT!のように言えば言い訳ではなく、実際の医療の現場、教育の現場、政策の現場ではそうは言えないですよね。そこで登場する概念です。
種類は大きく分けて3つ
•Simple before-after / pre-post
•Interrupted time series (ITS)
•Difference-in-differences / controlled interrupted time series (DID/CIT)
です。
ITSは必ずしも介入によるものかどうかは言えないので永遠のLimitationです。可能であれば同じ時間でコントロールを立てて、比較が望ましくなります。DIDは、差の差のを比較するわけで、CITSは、フォローアップ期間中に介入群がそのベースラインの傾向から逸脱する(ベースライン平均値と傾き)を比較した場合に比べて大きいかどうかを比較します。それでも、その他の要素が影響している可能性があるので、わかりやすく言うと1) コントロール群を立てる時に出来るだけ注意し,2 ) 潜在的交絡因子をregressionやマッチングで調整するのですね。
授業で用いた教科書はこの論文です。
Reference
1) International Journal of Technology Assessment in Health Care, 19:4 (2003), 613–623.

Y = ß0 + ß1time + ß2post + ß3time*post
ß0 = baseline LEVEL of outcome
ß1 = baseline TREND of outcome (slope prior to intervention)
ß2 = change in LEVEL after the intervention
ß3 = change in TREND after the intervention (the difference between pre-intervention and postintervention slopes)
このようなモデルに当てはめるときの、QIにおける極論的な理解は下記になります。
| Outcome | Methods of Statistical Analysis |
| Continuous | Linear regression |
| Binary | Logistic regression |
| Counts | Poisson regression |
極論ですが、僕にはわかりやすく感じます。Poisson regressionでまだ論文を発表したことがないので、今やっているCapstone QIで試しに使ってみたいと思います。