みなさまこんにちわ。
今週のHarvard Medical school大学院の方のテーマはSurvey designです。これは以前自分もGCSRTプログラムで学習したつもりですが、やはり大学教員たるもの若手にちゃんと教えることができるようになるようにPitfallsなどをまとめておこうと思います。
アンケート調査の作成時の陥りがちな5つのこと。
*Avoiding five common pitfalls of Survey design. Academic Medicine, Vol. 86. no,10/October 2011.
1:一つの項目に聞きたいポイントを2つ以上入れてしまっている。ex) 何か問題があった場合に、どれくらいの頻度で看護師や上級医に相談していますか?
理由:並列になっていると、上級医にはあまり相談しないれど、看護師にはよくする場合には矛盾で答えられない。
打開策⇨Sruvey ietem should adress one idea at time.一つの質問に一つの内容!
2: 質問内容にNegativeなイメージの言い回しを入れる。ex) どれくらい朝の授業で遅刻しますか?
理由:Negatively worded survey items are challenging for respondents to comprehend and answer accurately. 回答者はネガティブな回答は無意識に避け、正しく回答しない傾向がある。また、二重否定などの今わしも同様で、回答者は混乱する。
打開策:Yesと答えが方が良いものにはYes. YesにはYes。NoにはNo. ex)週の平均でどのくらいの頻度で朝授業に間に合っていますか?
3:質問ではなく回答者の宣言になってしまっている。ex) 私はこの授業でAを習得した自信がある。
理由:Surveyは勘違いされているが、基本的には会話である。より正しい情報を引き出そうと思ったら、会話のキャッチボールにするべきで、一方的に宣言させてしまってはならない(回答者のバイアスが発生しやすくなる)
打開策:宣言タイプのから質問へ。ex)あなたはこの授業でAを習得した自信がありますか?
4:同意を聞く回答様式になっている。ex)The high cost of health care is the most important issue in America today. (現在のアメリカでは医療費は最重要課題である) • strongly disagree • disagree • neutral • agree • strongly agree
理由:興味のある構成要素固有の回答項目を使用します。そうすることで、回答者が無関心になることが減り、質問の構成要素に回答者が集中できるようになります。そうすることで、測定誤差も少なくなる。
打開策:ex) How important is the issue of high health care costs in America today?
5:選択肢の数が多すぎる、少なすぎる。ex) 選択肢3、ないし10個
理由:一般原則として、選択肢が少なすぎると調査の信頼性が落ちてしまう。
打開策:選択肢は5-7個程度でちょうど良い、先行研究的には9個以上に増やしたからと言って調査の精度をあげることはなかった。ex) 選択肢は5-7程度。

考えるべきポイント!
Relevancy and accuracy are two ideals that encompass the main outcome of creating reliable surveys. These two principles work together to write effective survey questions. To achieve relevancy, keep the following factors in mind. 関連性と正確性は、信頼性の高い調査を作成するための主要な成果を包含する2つの理想。
集めるべき必要な情報をまず見極める
・表現のスタイル、タイプ、質問の順序を工夫する。
・アンケートをアトラクティブにし、文章の長さや、全体に回答するのにかかる時間に注目する。
・アンケートを作成する際には、著者は自分自身を典型的な回答者として勘違いしてはいけない!そのような教育を受けていない回答者の立場であればどう回答するかを考える。
・関連性と正確性について考慮しなければならないことは質問の書き方と全体の長さ。なんのために、目的と、どのようなデータとして解析するか逆算する。
・センシティブな情報は正確性が落ちるために工夫する、ex) 実年齢を聞くよりは、生まれた西暦を聞くと回答の正確性が増加する。
・読みやすい質問を使用する - 読みやすく、素早く簡単に回答できる質問を作成。これにより、質問が完全に読まれる前に回答者が回答に飛びつくのを防ぐことができます。(質問や回答のリストが長くなると、データの質が低下することがあります, Iarossi 2006, 44)
・回答者に関連性のある質問にする - すべての質問が、すべての回答者および調査の目的に関連するものである必要がある。よってもし〜ならばなどの仮定の質問は避ける(Iarossi 2006, 44)。もしあなたが、タイのコーケンの市長の選挙についてアンケートされたとして、興味ないからちゃんと回答しないはず。
・回答者にとって苦痛のない質問を - アンケートの質問は、回答に可能な限り労力を必要としないものでなければならない。ほとんどの人は、難しく考えたり、時間をかけたりせずに、素早く回答してアンケートを完了させたいと考えているので、Rating scaleの真ん中のつけて終わったりなど。
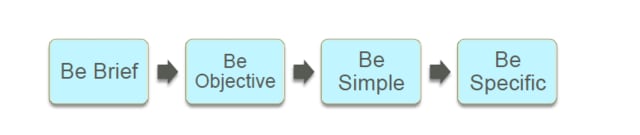
・目的と場合によって異なるのでこうすれば完璧というsuveryの質問作成はないが、良い悪い質問紙を作るポイントはある。(Be Brief:簡潔に、Be Objective:目的を明確に、Be Simple:シンプルに、Be Specific:具体的に)です
・Leading Question Biasを避ける。よくある質問自体が回答を先導するのを避ける!
Bad Example: We have recently upgraded SurveyMonkey‟s features to become a first-class tool. What are your thoughts on the new site?
Replace with: What are your thoughts on the upgrades to SurveyMonkey?
・Loaded questions biasを避ける。言葉やステレオタイプ、威信的なイメージなど、感情的な項目に作用してしまう。「回答者のエゴや要望を煽ったり、回答者のプライドを歪めたりするような言い回しは避ける。これは、回答者を特定の回答へ導く結果へ。
・回答者が質問内容に対して精通していると勝手に仮定しない。対象者は適切か?
・否定的な表現や二重否定的な表現は常に避ける。また【常に】や【決して】や【絶対に】などの断定的な言葉の使用は、回答者に質問への回答を避けさせる原因となる。
・曖昧さを避ける。人の思考プロセスはそれぞれ異なり人によっては異なる意味を想起する。ある人にとっての「しばしば」は週に1~2回、他の人にとっては月に数回という意味かもしれないので、明確にすると良い
・Balanced or non-balanced rating scaleにするかどうか。Here is where you decide if you want to provide a “neutral” middle category to your scale. If a neutral choice is a possibility, then you may want to include a midpoint answer choice. However, if you want the respondent to take one side over the other, then an even number of categories is suggested. This will force respondents away from the neutral response (Iraossi 2006, 61).
中間をつけることで、賛成、否定の両方の傾向でもない中間の層を拾えるが、質問の内容によっては中間になるかもしれない。本当にどちらかよりに明らかにしなければならない内容であれば偶数にしてしまうのも良い。N/Aとすることも場合にはOK。
・質問順序の作り方も:良いアンケートのデザインは想起を促すのに役立つのと、質問の順序は回答者の興味を和らげたり、喚起したり、調査の意図に対する疑問を解消したりすることにもつながる。一般的なガイドラインとして、質問の順序には、
Opening questions冒頭の質問:参加者は調査の目的を明確にする。参加者の興味と全体的な参加意欲を刺激するように。
Question flow 質問の流れ:アイデアの流れを汲み取り、回答者の能力に合わせたもの。トピックはグルーピングする。
Location of sensitive questionsセンシティブな質問は最後に:アンケートの最初に難しい・センシティブな質問を入れると回答者がアンケートを拒否して早々に退出してしまう可能性を考慮。
3つの領域を考えると良い。
・アンケートの構造を設計する際には、最初から最後まで一貫性のある形式とレイアウトが重要。わかりにくい、不十分に構成されたアンケートは、回答者が質問を飛ばしたり、アンケートへの回答を完全に拒否したりする可能性。
・レイアウトに注意を払い、回答者側、またはコーディングやデータクリーニングの部分でエラーが発生する可能性を極限まで減らす。解析からの逆算が必要。論理的で、識別性、コーディング性、および保存の容易性を熟慮。要は、データをとった後に偏っていたり、カテゴリカルデータに落とし込めなかったり、missing dataやデータ入力など含めて解析に使えるか。
・Pilot testを実施して、実際の必要な時間、データの漏れやすさ、上記が問題ないか最後ではあるが、もっとも重要な仕事。下記チェックリストを用いると良い。
✔︎回答者はアンケートの目的を理解できるか?
✔︎回答者は質問に安心して答えられるか?
✔︎アンケートの言葉遣いは明確で丁寧か?
✔︎回答者にとって使用する時間は適切か?
✔︎選択肢は、その問題に関する回答者の経験と一致しているか。
✔︎回答する前に、回答者が長く考えすぎたり、一生懸命考えたりする必要がある項目がないか? どの項目か?
✔︎どの項目が感情を揺さぶってしまうか?(イライラして、恥ずかしさ、答えにくさ)
✔︎質問のどれが回答に偏りを生じさせルカ?
✔︎収集された回答は、調査の目的を反映するデータてなるか?
✔︎受け取った回答には十分な多様性があるか?
✔︎アンケートは長すぎないか?
✔︎pilot test施工車の意見では何か他に重要な問題が見落とされていないか?