以下の文は、Kan Nishida氏の『なぜコロナウイルスの感染者数のデータは意味がないのか』と題した記事の転載であります。
『なぜコロナウイルスの感染者数のデータは意味がないのか』
Kan Nishida
以前から言っていることですが、メディアでよく目にする感染者数という数字はあまり意味がないと思います。
特にその数字を持ってそれぞれの国を比べようとするときには意味がないどころが害すらあると思います。
というのも、感染者の数というのは検査の数に大きく影響を受けます。
そしてその検査をどれだけ、どのように行うかというのはそれぞれの国によって戦略も状況も違います。
しかし現実にはそういったことを考慮することなしに、感染者数の値を毎日見て、一喜一憂し、さらにはそれぞれの国の感染者数の値を比べ、どこの国がいいとか悪いと決めつけ、さらには感染者数の増加のトレンドをもとに「あなたの国もイタリアのようになってしまう」といった、無責任な報道が多くのメディアから毎日垂れ流されています。
これは日本だけでなく、私の住むアメリカでも一緒です。
そんな時、FiverThirtyEightのNate Silverが、いかに感染者数というデータが意味のないものであるかをシミュレーションも交えて解説する記事を出しいたので、みなさんと共有したいと思います。
シミュレーションの部分も含めると非常に長いので全ては紹介しきれないのですが、なぜ感染者数の数値が当てにならないのかという点について抜粋して紹介します。
コロナウイルスのデータは意味がない
あなたがFiverThirtyEightの読者であればスポーツや政治のデータを見るのに慣れていると思います。
バスケットボールや野球であればすべての行為が記録されたデータ。
選挙の場合は全体からのランダムに集めてきたサンプルを使った聞き取り調査データと言った具合です。
COVID-19の場合、特に感染者数というデータはそういったものとは全く違います。
このデータはベストなものでも、かなり十分ではありません。
そしてそれはもっと大きな問題の表面に見えている一部にしか過ぎません。
さらに、検査数と報告された感染者数のデータはランダムに集められているわけでも全くありません。
検査の目的
世界中の医療機関は限られたデータを使って現在の状況を把握しようと努めています。
彼らの検査の目的は限られた医療資源を最もそれを必要とする人に提供できるようにすることです。
感染症の研究者と統計学者が分析するために十分なデータセットを作ることではないのです。
検査の戦略の違い
検査がどう行われているかを考慮することなしに、こうしたデータから結論を導き出したのであれば、それはまったく見当違いのものとなるでしょう。
ちょっとした間違いを犯すというリスクがあるどころか、あなたの分析はとんでもないレベルの間違いを抱えてしまっているかもしれません。
もっとひどい場合は、実際に起きていることとは反対の結論が導きだされているかもしれません。
例えば他に比べてたくさんの検査をしているために感染者数が増えている国は実は感染の拡大をコントロールできているのかもしれません。
逆に、新規の感染者数が減少している国は、単純に検査をするためのシステムが崩壊していたり、PRのために検査の数を減らしているのかもしれず、実際には状況は悪化しているのかもしれません。
それぞれの国の検査に関する戦略を理解することなしに、国や州どうしを比べるということには意味がありません。
最近の感染症の2つの研究によると、データを集めるという点で最高の仕事をしている国(例えばノルウェーなど)と最悪の仕事をしている国(例えばイギリスなど)の間には感染者を見つけ出すことができる率においておよそ20倍ほどの違いあるとのことです。(USはおそらくこの中では真ん中あたりでしょう。)
ということは、ある国が1,000人の感染者数がいると報告している場合、それは5,000人なのかもしれず、また別の国で1,000人というときは実は100,000(10万人)なのかもしれないということです。
感染者数に関する不確実性
さらに一つの国の中でも不確実性が大きいです。
USで発見された感染者数の数は実際の数を低く見積もっているかもしれず、私達が専門家を対象に行ったアンケートの結果によると、その違いは2倍から100倍ほどでした。
これは他の国でも同じようなことが起きています。
最近ロンドンのインペリアル・カレッジによって発表された論文によると3月30日時点で実際に感染された人の数は80万から370万人の間ということですが、これは公表されている2万2141人という数字と比べると大きな隔たりがあります。
再生産数、Rの前提条件
どのような感染症のモデルでも最も重要な数字はRというものです。
これは再生産数とも言われます。
最初に感染した1人が新しいグループに入った時に何人を感染させてしまうことになるかという数値です。
例えば、もしある病気のRが3であれば、それぞれの感染者がさらに3人ずつ感染させてしまうということになります。
つまり、最初の1人が3人の新規感染者を作り、それが次には9人、それがさらには27人、さらには81人と言った具合です。
これが感染者数が短期間の間に指数関数的に増加していく所以です。
このRでさえ、それに関する前提は様々です。
一人の感染者から次のグループにどれだけ速く感染するかといった数値を定義しようとしているのですが、そこにはさまざまな前提がついてきます。
疫学者たちも、基本再生産数と呼ばれるR0と、実効再生産数とよばれるRを区別しています。
基本再生産数のR0とは、何も介入が行われず、さらに免疫もない環境でどれだけ速く広まるかという指標である。
実効再生産数のRは現在の環境においての再生産数であり、その環境は時と場所によって変わります。
Rはクルーズ船や大学の寮では高いでしょう。
逆にアラスカの離れた町のように人と出会うことがあまりないような場所では低いでしょう。
もちろん介入の内容は場所によって違いはあるものの、ソーシャル・ディスタンス(社会的距離)のような介入はRの値を下げるために行っています。
そうした施策のゴールはRを1より小さくすることです。
この状態になるとウイルスは数の上では死んでいくということになります。(1に近ければ緩やかに死んでいき、0に近ければ素早く死んでいく。)
最後に感染が社会の中でとても大きく広まると、Rは最終的には小さくなります。
というのも集団免疫ができるからです。
言い換えると、十分な数の人達がすでに感染し、そのことによって病気に対する免疫を持つと、ウイルスはそれ以上同じ速さで広まり続けることができなくなります。
筆者注:
この再生産数に関しては皆さんにより正しい情報を提供したいため、Wikipediaの基本再生産数のページより以下を抜粋しこちらに掲載しておきます。
基本再生産数 R0 は、環境因子や感染集団の行動による影響も受けるため、病原体に対する生物学的な定数ではない。
さらに、基本再生産数 R0 の値は通常、数理モデルから推定されるので、推定値は使用されたモデルや他のパラメータの値に依存する。
したがって、文献における値は特定の文脈においてのみ意味があり、古い値を使用したり、異なるモデルに基づく値を比較したりするべきではない[6]。
また基本再生産数 R0 自体は集団内における感染症の蔓延する速度を推定するものではない。
基本再生産数 R0 の最も重要な用途は新興感染症が集団内に蔓延するかどうかを決定することと、感染症を撲滅するためには集団のどのくらいの割合にワクチン接種をして免疫化すべきなのかを決定することである。
一般に使用される感染症モデル(英語版)では R0 > 1 のとき、感染症は集団内で蔓延をはじめ、R0 < 1 のときには蔓延しない。
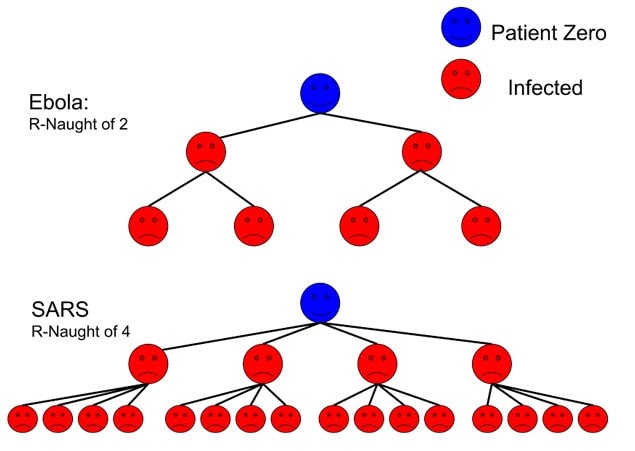
以下は同じくWikipediaからとってきた画像です。
青が最初に感染した人、赤は感染された人です。基本再生産数が2であるEbola(エボラ)の例と、基本再生産数が4であるSARSの例です。
この基本再生産数が上がると一気に感染の拡大が指数関数的に広がっていくのが分かると思います。
ちなみに、以下は様々な感染病の基本再生産数です。
終わり。
現在目にしている数字は2週間前の数字である
ある人が感染した時、症状が出た時、検査を受けた時、そしてその検査の結果が報告された時の間には長い時間のギャップがあります。
中国の武漢では症状が出てきた時と検査の結果が報告された時の間のギャップは10日から12日と言われています。
さらに感染してから症状が出るまでに少なくとも数日はかかると言われていることから、感染してから感染者として報告されるまでにはかなりの時間がかかります。
ですので、私のシミュレーションのシナリオではだいたい15日ほどの遅れがあると仮定しています。
しかしそれでも控えめな方で、実際には、検査体制が整ってないカリフォルニアの例などを考えるともっとかかるのではないでしょうか。
完璧なケースを考えてみましょう。
住民の100%が検査を受け、検査の精度も100%だっと言う場合です。
そこでRが2.6だとすると、15日の遅れは、どの時点でも実際の感染者数は報告される新規感染者数の約18倍ということになります。
つまり新規感染数を見ると言うことは、実際には私達はいつも2週間ほど前の状況を見ているということになります。
さらに、ソーシャル・ディスタンスの施策の効果がデータに現れまでにはおそらく2、3週間ほどかかるでしょう。
これは、とくに検査の要望が多いために検査の結果を出すためのプロセスに大きな時間がかかってしまっている時は特にこういった状況になります。
完璧でない検査
もう一つの現実世界での問題は、検査は完璧でないということです。
実際、ウォール・ストリート・ジャーナルの記事によると、実際にCOVID-19に感染しているうちのだいたい30%の人たちが検査の結果、陰性だと診断されるとのことです。
これは「偽陰性 (False Negative)」と呼ばれるものです。
もちろん、その逆の「偽陽性 (False Positive)」と呼ばれるものにも気をつけなくてはいけません。
検査の結果感染している(陽性)と診断されたが、実は感染してない(違う)という場合です。この数字がどれくらいになるかは突き止めるのが難しいです。
しかし私達は検査による偽陽性 (False Positive)」はほぼないと推定することができます。
なぜか?
症状のない大量の人たちが検査を受けたアイスランドでは、陽性と出た率は1%以下でした。
この集団に実際にはコロナウイルスに感染していた人たちがいたことを考えると、偽陽性 (False Positive)の率はさらに1%より低いと考えることができます。
そこで私のシミュレーションではこの数値を0.2%と仮定します。
しかし、この偽陽性 (False Positive)の率を計算する時にちょっとした数学のひっかけがあります。
というのも、例えこの偽陽性 (False Positive)の率が低かったとしても、感染者数が少ないときには偽陽性 (False Positive)の数が、真陽性 (True Positive)の数を上回ってしまうことになります。
例えば、10万人の町で感染の拡大の最初のステージがあったとしましょう。
さらに100人つまり0.1%の人がすでに感染したとします。
もし全ての人が検査を受けたとすると、先ほどの偽陽性の率、0.2%を使うと、偽陽性の人が約200人ということになってしまいます。
これは実際に感染している人たちの2倍である。
このことが陰陽性に関する議論をややこしくしてしまいます。
見つけ出せない感染者達
次の問題は、どんなにすばらしい検査の体制が整っていたとしても、それでも多くの感染者を見逃してしまうということです。
例えば感染していても症状が軽い人や症状のない人は検査を受けようとはしないでしょう。
また、20%の偽陰性率を持つ検査は、いつもある一定の数の人達を見つけることができません。
さらに、例え検査体制の整備が素早く拡大していったとしても、それはウイルスの拡大ほど速く拡大することはないでしょう。
検査の数に影響される感染者数
検査の数が増加すると病気の感染拡大の速度は実際よりも多く見積もられます。
逆に検査の数が一定、または減少していると感染拡大の速度は実際よりも低く見積もられます。
言い換えると、ドイツのようにある時突然真剣になって急に検査の数を増やし始めると、新規感染者数がものすごい速度で増加しているように見えるが、それは検査の数の増加と感染者の増加によるものであって、急激な増加はどちらによるものなのか区別することが難しくなります。
さらに、検査の数が最初はゆっくり増加し、その後ある時急激に増加し、その後また一定になったUSのようなケースでは、実際の感染者数と検査の結果が陽性であった人の数との間の歪みはもっとひどいものです。
例え最初の時期に実際のRが「たったの」2.6であったとしても、(もちろん、これはかなり恐ろしく高い数字であす。)報告される感染者数をベースにしたRは7.8に見えるのである。
これは検査体制を大幅に拡大しているからである。
ある数週間は感染者数の伸びがとてつもなく急なように見えます。
チャートを見たときにこのような急な伸びを示している国は、他の国に比べてとんでもなく悪くなっていくことを示しているようだと思うかもしれません。
しかし、実際の感染者数の数はどの時点でも前のシナリオのときと一緒なのです。
もちろん、これはこのシナリオがいいということを示すわけではありません。
この手の国は実際に知れ渡っているよりももっと大きな問題があったということで、それがようやくみんなの目に見えるようになってきたと言うだけです。
まとめ
最初に述べたように、この記事を書いた理由はみなさんに、COVID-19の感染者数という数字は、どのように検査が行われているのかを知らない限りは実際の状況を理解するのにはほとんど役に立たないものだということです。
いつもであれば説教臭くなるのは避けたいところなのですが、メディアによって毎日のように報道される上昇傾向にあるコロナウイルスの感染者数の数字をただ単に受け入れてしまうのでなく、その裏にある背景を理解しなくてはいけないということを伝えたいのです。
そういった背景には、どれだけの検査が行われているのか、病院の受け入れ能力なども含まれます。
以上、要約終わり。
最後に
日本は欧米のメディアから感染者数が少ないのは検査が少ないせいで、それは実際の感染者数を隠すためではないか、とかなり早い時期からずっと批判されてきました。
さらに当初はこの夏開催されるはずだった東京オリンピックがあったので、センセーショナルな陰謀論の的となってしまった面もあります。
そういう私も当初は、なぜ日本の感染者の数が他の国に比べて少ないのかをよく理解できていませんでした。
というのも最初はダイアモンド・プリンセスというクルーズ船での集団感染などの件があり、そもそも日本の感染者数が少ないということすら気づいていなかったのです。
そこでちょっと調べてみると実は、日本政府は国として医療崩壊を防くことで多くの救えるはずの人命を救うというのがゴールで、そのためには医者が見て必要と判断しない限りは検査しないという戦略をとっていたということを学びました。
ちなみに、この戦略は感染者数の増加を緩やかにするという、「Flatten the Curve」という目的のためのもので、この言葉は後に欧米でもある時を境に急に広まることとなりました。
そこで、国同士の被害を比べるのであれば、完璧でないとしても感染者数よりも、死亡者数のデータを見た方がよいのではないかと思います。
もちろん、この死亡者の定義も国によってまちまちなので、比べていいのかどうかは議論のあるところだと思います。
ところで感染者数のデータが頼りにならないというのは実はアメリカでも同じです。
もともとは日本のように医者が見て必要としない限りは検査をしないということで、検査はあまり積極的に行われていなかったのですが、急に3月の中旬あたりからニューヨークを中心に一気にその数が増えました。
そのことによってアメリカ全体の感染者数の数が上がり、さらにはそこにニューヨークのようにソーシャル・ディスタンスに関する施策が後手後手に回ってしまった州などでは一気に医療崩壊が起きてしまい、死者の数まで増えてしまったことで、アメリカ中は一気にパニックに陥りました。
さらに、あまりにも有名になったファイナンシャル・タイムスのそれぞれの国の感染者数の増加を時間の経過とともに表したチャートを見ると、まるでアメリカでの感染者数の増加の傾向が、3月上旬時点で最も悲惨な状況に陥っていたイタリアの後を追っている用に見えるチャートがメディアとインターネット中に広まり、一般市民は恐怖に怯える状態となってしまったのです。
以下は3月中旬のファイナンシャル・タイムスによる感染者数の増加のチャートです。
しかし、本文でも触れているように、この感染者数というのは、検査がどのような方針で行われているのか、さらに検査の性質というものを理解することなしには全く当てになりません。
さらに、国によってこうした検査の方針や体制は大きく異なるので、この数字を持って他の国と比べても仕方がありません。
しかし、手元にある最も身近でさらに、「ひどくなってる」ことを表しやすい数字がこの感染者数であったので、残念ながら多くのメディア、マスコミはこの感染者数というデータの裏にある背景を理解しようとすることなしに、ただ単に毎日垂れ流しては、一般市民の恐怖を煽り、さらには自国の政府に対する余計な不信を抱かせるということになってしまいました。
これは、大変残念なことだと思います。
というのも、政策を立案、アドバイス、監督する立場にいる人たちも、この感染者数という実態がよくわからないが事実であるかのように見えてしまうデータによって、現実を理解する能力が鈍ってしまいます。
さらには、政治は世論から逃れることはできません。(民主主義の国であれば。)
毎日メディアが自分たちの視聴率とクリックを稼ぐために垂れ流す数値によって多くの国民が恐怖感、不安感に襲われてしまっているとき、政治家は冷静に判断を下すのがより難しくなるでしょう。
結果として、感染者数の増加(そして一部の国、地域での死者数の増加)による恐怖感によって、多くの国では最も現実的ではないはずのロックダウンという施策が取られ、それによってビジネスがストップしてしまい、そのせいで失業者が歴史上前例を見ないほどに増えてしまい、さらには外に出るという基本的な人権まで失うことになってしまいました。
こうした犠牲が、コロナウイルスによる生命の犠牲を防ぐためにほんとうに必要であったのかどうかを判断するのはまだ時期早々ですが、今回の危機が終わった後、長い時間をかけて検証されていくのでしょう。
しかし、危機が去ったあとで検証したところで、一度与えられたダメージというのはなかなか簡単には回復されるものではありません。(回復不可能なものもあるでしょう。例えば失業による自殺など。)
今回のコロナウイルスによるパンデミックによる混乱を見にした時ほど、データ・リテラシーの重要さを痛感したことはありません。
データを見るということは、そのデータの裏にある背景を理解し、数値をさまざまな文脈でとらえ、さらには確率や不確実性といった概念を理解していくことでもあります。
その国の民主主義を正しく機能させることができ、さらには国民の安全と経済の成長を実現させるためには、多くの国民が高いデータ・リテラシーを持つことほど、重要なことはないのではないでしょうか。
転載終わり。