








昨日届いたパソコンで、本格的に研究にとりかかったのですが、これがなかなか厄介な代物です。
まあ、とりあえずPDB(プロテインデータバンク)という、これまで見出された全タンパク質構造データを公開しているサイトがあるのですが、そのデータベースの全XMLファイルを落とそうとしたのです。ところが、これが予想外に大変な作業で、一括ダウンロードしようとすると、途中で接続が切れてしまうため、ほとんど手作業でせざるをえません。全部で44000個近いファイルが存在し、それらが約1000個のフォルダに分散しているので、手作業だとものすごく時間がかかります。昨日の夕方から今日の午前中の実質10時間で、ようやく150フォルダをダウンロードできました。
しかし、ダウンロードしたXMLデータを使おうと思っても、解凍が必要で、実際にいくつか解凍してみると、一つのファイルだけで35MBなどというデータも存在し、解凍にも結構時間がかかってしまいます。35MBの文字列の中から、有用なデータを探し出さなければなりませんから、ちょいと情報工学の方の知恵が必要でして、これから教官の共同研究者の方にメールしてみようかと思います。
いずれにせよ、一筋縄ではいかなさそうです。
いやはや、大変ですわ・・・。
まあ、とりあえずPDB(プロテインデータバンク)という、これまで見出された全タンパク質構造データを公開しているサイトがあるのですが、そのデータベースの全XMLファイルを落とそうとしたのです。ところが、これが予想外に大変な作業で、一括ダウンロードしようとすると、途中で接続が切れてしまうため、ほとんど手作業でせざるをえません。全部で44000個近いファイルが存在し、それらが約1000個のフォルダに分散しているので、手作業だとものすごく時間がかかります。昨日の夕方から今日の午前中の実質10時間で、ようやく150フォルダをダウンロードできました。
しかし、ダウンロードしたXMLデータを使おうと思っても、解凍が必要で、実際にいくつか解凍してみると、一つのファイルだけで35MBなどというデータも存在し、解凍にも結構時間がかかってしまいます。35MBの文字列の中から、有用なデータを探し出さなければなりませんから、ちょいと情報工学の方の知恵が必要でして、これから教官の共同研究者の方にメールしてみようかと思います。
いずれにせよ、一筋縄ではいかなさそうです。
いやはや、大変ですわ・・・。
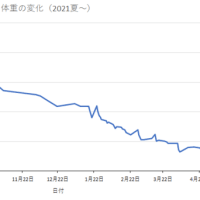




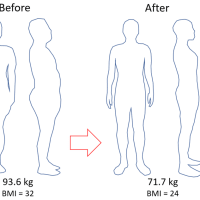



※コメント投稿者のブログIDはブログ作成者のみに通知されます