








どうも、最近お仕事が勉強と検討ずくめで頭が疲れているTです。
前回に引き続きLLM関連のことを書こうと思います。
今回はRAGについてです。
と言いつつ、タイトルからお察しの通りうまく動かなかった話です。
まず、「RAG」とは何ぞや?から簡単に書こうと思います。
RAGは「Retrieval Augmented Generation」の略で、直訳すると「検索拡張生成」です。
LLMはよく知らない知識をさも知っているかのようにでっち上げて回答する「ハルシネーション」を起こします。RAGは、ハルシネーションを減らすために「このデータをもとに回答して」と指示するLLMの使い方を指します。
データは事前に「Embedding」という処理を経て「ベクトルデータ(意味データ)」に変換しておく必要があります。こうすることで、例えば「リンゴ」と「アップル」、「Apple」のような「同じ意味だけど違う呼び方」を同じ一つの情報として認識できるようになります。
そして、今どきのRAG界隈では「Graph RAGがすごいぞ」と言われているようです。
「Graph RAG」は先に説明した「意味データ」だけでなく、データの相関図を作成することで検索精度を上げる手法のようです。例えば「リンゴはミカンやブドウなどと同じ果物である」や、「AppleはiPhoneなどを開発する企業名である」というデータの繋がりや重要度などを分析して、より質問に合った回答を導き出すようです。
言葉の意味を説明したところで、具体的に今回試してみたツールをご紹介します。
https://github.com/Cinnamon/kotaemon
読み方は「こたえもん」…でいいんですかね?ブログ中では「kotaemon」と書こうと思います。
kotaemonはRAGシステムを簡単に使えるようにしてくれるWeb UIアプリです。
RAGシステムってたいていはPythonの環境構築が必要になるので、使うハードルが高めです。kotaemonならインストーラを実行すれば環境構築を自動でやってくれます。
で、さっそくこちらを参考にインストールしてみたのですが…、残念ながらいくつかパッケージのインストールがうまくいかず、不完全な形でインストールされてしまいました。
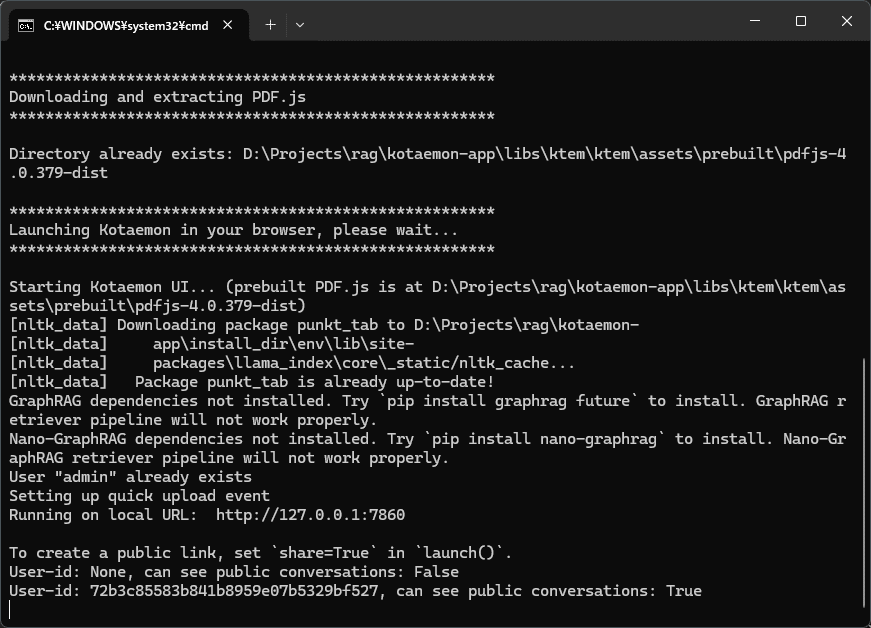
『「graphrag」や「nano-graphrag」がインストールされてないから正常に動かないよ』とエラーメッセージが出ています。
ただ、一応Web UIは表示されました。とりあえず一つ質問を投げてみましたが…
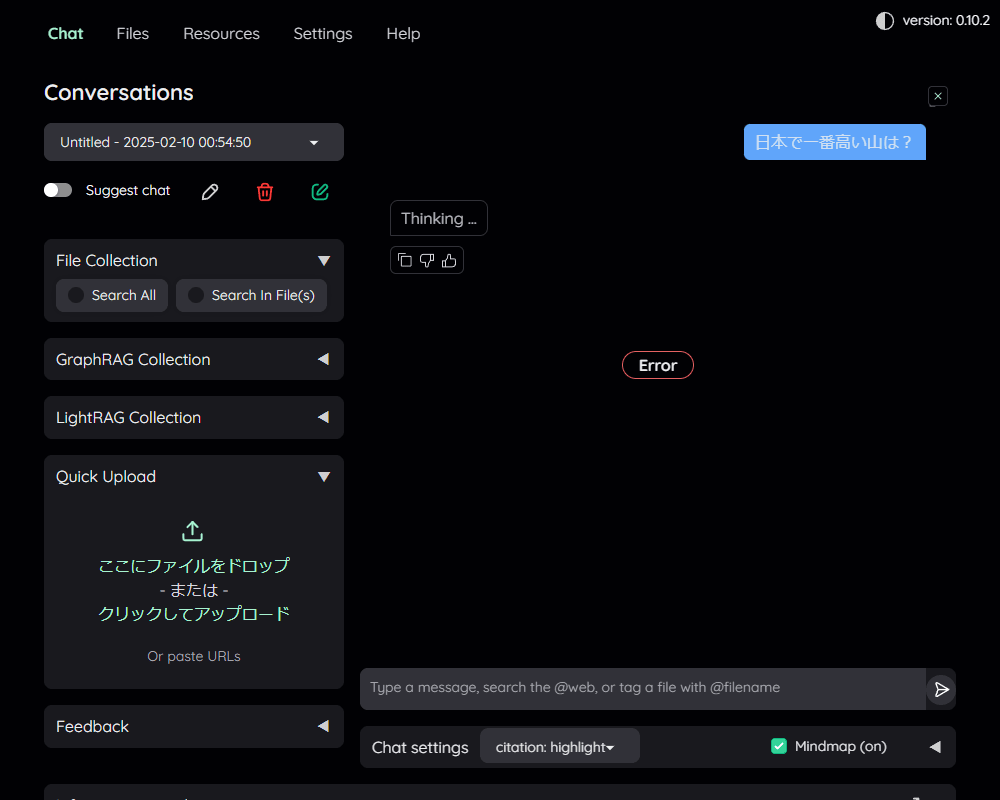
御覧の通り、エラーになってしまいました。
どうやらデフォルトでGoogleのLLMを使う設定になっているようで、APIキーなどを設定しないと使えないようです。
それから色々触ってみた結果
・しょっちゅう起動に失敗する
・依存関係のコンフリクトが原因で不足パッケージが発生
・ローカルLLMを使うには別途Ollamaが必要
・ローカルLLM設定はテキストファイルの編集が必要?
など、まだいくつか環境構築が必要なこと、原因不明な不安定さを抱えていることがわかりました。
なかなか一筋縄では行かず時間もかかってしまったので、今回はここまで。
動かせなかったのは残念ですが、インストーラだけでなくDockerでも提供されていたので、また時間のある時にOllamaのセットアップも含めてトライしてみようと思います。
それでは。
(T)
moni-meter
脱・手書き!点検データをデジタル化、誤検針を削減
AI自動読み取りで検針が楽になる設備点検支援システム
PLMソリューション
製品ライフサイクルの各データを活用しビジネスを改革
PLMシステム導入支援、最適なカスタマイズを提案します
EV用充電制御ソリューション
EV充電インフラ整備を促進するソリューションを提供
OCPP・ECHONET Liteなど設備の通信規格に柔軟に対応
株式会社NTTデータIMジェイエスピー
横浜に拠点を置くソフトウェア・システム開発、
製品開発(moniシリーズ)、それに農業も手がけるIT企業
前回に引き続きLLM関連のことを書こうと思います。
今回はRAGについてです。
と言いつつ、タイトルからお察しの通りうまく動かなかった話です。
まず、「RAG」とは何ぞや?から簡単に書こうと思います。
RAGは「Retrieval Augmented Generation」の略で、直訳すると「検索拡張生成」です。
LLMはよく知らない知識をさも知っているかのようにでっち上げて回答する「ハルシネーション」を起こします。RAGは、ハルシネーションを減らすために「このデータをもとに回答して」と指示するLLMの使い方を指します。
データは事前に「Embedding」という処理を経て「ベクトルデータ(意味データ)」に変換しておく必要があります。こうすることで、例えば「リンゴ」と「アップル」、「Apple」のような「同じ意味だけど違う呼び方」を同じ一つの情報として認識できるようになります。
そして、今どきのRAG界隈では「Graph RAGがすごいぞ」と言われているようです。
「Graph RAG」は先に説明した「意味データ」だけでなく、データの相関図を作成することで検索精度を上げる手法のようです。例えば「リンゴはミカンやブドウなどと同じ果物である」や、「AppleはiPhoneなどを開発する企業名である」というデータの繋がりや重要度などを分析して、より質問に合った回答を導き出すようです。
言葉の意味を説明したところで、具体的に今回試してみたツールをご紹介します。
https://github.com/Cinnamon/kotaemon
読み方は「こたえもん」…でいいんですかね?ブログ中では「kotaemon」と書こうと思います。
kotaemonはRAGシステムを簡単に使えるようにしてくれるWeb UIアプリです。
RAGシステムってたいていはPythonの環境構築が必要になるので、使うハードルが高めです。kotaemonならインストーラを実行すれば環境構築を自動でやってくれます。
で、さっそくこちらを参考にインストールしてみたのですが…、残念ながらいくつかパッケージのインストールがうまくいかず、不完全な形でインストールされてしまいました。
『「graphrag」や「nano-graphrag」がインストールされてないから正常に動かないよ』とエラーメッセージが出ています。
ただ、一応Web UIは表示されました。とりあえず一つ質問を投げてみましたが…
御覧の通り、エラーになってしまいました。
どうやらデフォルトでGoogleのLLMを使う設定になっているようで、APIキーなどを設定しないと使えないようです。
それから色々触ってみた結果
・しょっちゅう起動に失敗する
・依存関係のコンフリクトが原因で不足パッケージが発生
・ローカルLLMを使うには別途Ollamaが必要
・ローカルLLM設定はテキストファイルの編集が必要?
など、まだいくつか環境構築が必要なこと、原因不明な不安定さを抱えていることがわかりました。
なかなか一筋縄では行かず時間もかかってしまったので、今回はここまで。
動かせなかったのは残念ですが、インストーラだけでなくDockerでも提供されていたので、また時間のある時にOllamaのセットアップも含めてトライしてみようと思います。
それでは。
(T)
moni-meter
脱・手書き!点検データをデジタル化、誤検針を削減
AI自動読み取りで検針が楽になる設備点検支援システム
PLMソリューション
製品ライフサイクルの各データを活用しビジネスを改革
PLMシステム導入支援、最適なカスタマイズを提案します
EV用充電制御ソリューション
EV充電インフラ整備を促進するソリューションを提供
OCPP・ECHONET Liteなど設備の通信規格に柔軟に対応
株式会社NTTデータIMジェイエスピー
横浜に拠点を置くソフトウェア・システム開発、
製品開発(moniシリーズ)、それに農業も手がけるIT企業





