このブログは「すぐに役立つ統計のコツ」をもとに書いています。
統計分析は「習うより慣れろ・・!」ではないかと思っています。難しそうな統計学を一から始めるよりも、まずはやって見ましょう。
最近は、色々な無料の統計ソフトや著名な商用統計ソフトの試用版などが容易に使えますので、本書の内容をなぞってみては如何ですか。
統計分析は「習うより慣れろ・・!」ではないかと思っています。難しそうな統計学を一から始めるよりも、まずはやって見ましょう。
最近は、色々な無料の統計ソフトや著名な商用統計ソフトの試用版などが容易に使えますので、本書の内容をなぞってみては如何ですか。
このブログでは、無料の統計ソフトとMS-Excelでの方法を中心にご紹介しています。
それでは本題です。
「すぐに役立つ統計のコツ:表4.9(37ページ)」を見て下さい。
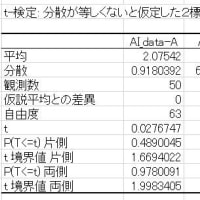
Kruskal Wallis テスト(K-W test)において、厳密にはバラツキが等しいかを調べます。参考までにその「R」での方法をご紹介しておきましょう。
前回のデータ(一元配置分散分析)の出力結果(縦長にしたデータ)を用いて試して下さい。
「R」での方法
***
fligner.test(VALUE ~ FACTOR, data=dat) # Fligner-Killeen(フリグナー・キリーン)
kruskal.test(VALUE ~ FACTOR, data=dat)
fligner.test(VALUE ~ FACTOR, data=dat) # Fligner-Killeen(フリグナー・キリーン)
kruskal.test(VALUE ~ FACTOR, data=dat)
出力結果:
Fligner-Killeen test of homogeneity of variances
data: VALUE by FACTOR
Fligner-Killeen:med chi-squared = 0.003643, df = 2, p-value = 0.9982
Fligner-Killeen:med chi-squared = 0.003643, df = 2, p-value = 0.9982
# p-value から、有意と言えませんので「バラツキは等しい」と判断します。
# 参考までに、Kruskal-Wallis test の結果は次の通りです。
# 「すぐに役立つ統計のコツ:表4.9(37ページ)」参照。
# 「すぐに役立つ統計のコツ:表4.9(37ページ)」参照。
Kruskal-Wallis rank sum test
data: VALUE by FACTOR
Kruskal-Wallis chi-squared = 10.312, df = 2, p-value = 0.005765
***
Kruskal-Wallis chi-squared = 10.312, df = 2, p-value = 0.005765
***
さて、
ここで一元配置分散分析(ANOVA)であれ、K-W test であれ、有意であればすべての組み合わせか、あるいは、どれかの組み合わせにおいて有意差があると言えます。それを調べるのが多重比較です。
ここで一元配置分散分析(ANOVA)であれ、K-W test であれ、有意であればすべての組み合わせか、あるいは、どれかの組み合わせにおいて有意差があると言えます。それを調べるのが多重比較です。
「すぐに役立つ統計のコツ」(第4章、29ページ)では、ノンパラメトリック法の「ホルム・ボンフェローニ」とパラメトリック法の「チューキのHSD」について説明しています。
本書では記載していませんが、多重比較でも効果量の記載が求められる様になってきましたので、例題でご紹介しておきましょう。例題は、
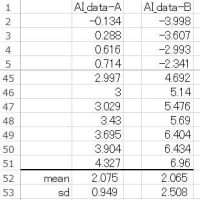
前回と同じ「すぐに役立つ統計のコツ:例題(表4.1、31ページ)」です。
前回と同じ「すぐに役立つ統計のコツ:例題(表4.1、31ページ)」です。
まずは、
「統計のコツのこつ(36)」でご紹介した検出力分析ソフト「G・Power」でやってみましょう。
「統計のコツのこつ(36)」でご紹介した検出力分析ソフト「G・Power」でやってみましょう。
●「GPower」による手順「統計のコツのこつ(36)参照)」
例えば、
本書(表4.1)の「投与前と2か月後」の効果量を求めて見ましょう。
本書(表4.1)の「投与前と2か月後」の効果量を求めて見ましょう。
test family→t-test→Mean:Wilcoxon-Mann-Whitney(two group)→Post hoc
[Tail(s):Two、Sample size group 1 = 6、Sample size group 2 = 6]→Determine→
[Tail(s):Two、Sample size group 1 = 6、Sample size group 2 = 6]→Determine→
◎ n1=n2[Mean group 1 = 221.3, Mean group 2 = 195.3, SD group 1 = 28.68, SD group 2 = 29.67]
→Calculate and transfer to main window→Calculate
出力結果:
Effect size d = 0.891、Power = 0.2738(27.38%)
Effect size d = 0.891、Power = 0.2738(27.38%)
注釈:
効果量(Effect size)はLarge(0.80以上)なのに、検出力(Power)は小さい。すなわち、効果量に見合ったデータ数で無い様です。下記のMann-Whitney U-test からも有意でないことが p-value から分かります。
効果量(Effect size)はLarge(0.80以上)なのに、検出力(Power)は小さい。すなわち、効果量に見合ったデータ数で無い様です。下記のMann-Whitney U-test からも有意でないことが p-value から分かります。
***
Mann-Whitney U-test
U = 11.5 , E(U) = 18 , V(U) = 38.86364
z-value = -1.043
p-value = 0.297107
***
Mann-Whitney U-test
U = 11.5 , E(U) = 18 , V(U) = 38.86364
z-value = -1.043
p-value = 0.297107
***
効果量を表す指標は色々あり、正直に言ってどの指標を用いるべきか迷う時もあります。しかし、大きく分ければ
・Cohen's d :平均値の差を標準化した効果量(d famiky:d族)
・r :相関関係の強さ(association:r family:r族)
・Cohen's d :平均値の差を標準化した効果量(d famiky:d族)
・r :相関関係の強さ(association:r family:r族)
の2種類が多用されていると思います。
長くなりましたので、「r family」の計算は次回にします。
それから、
この例題は「パラメトリック検定」のものを用いて紹介しています(念のため・・・)。
この例題は「パラメトリック検定」のものを用いて紹介しています(念のため・・・)。
情報統計研究所はここから!