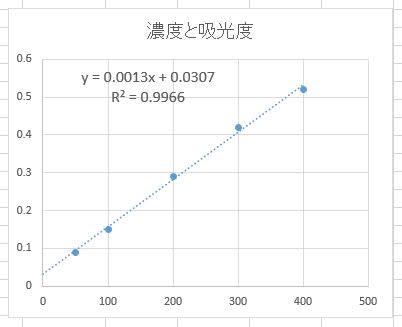
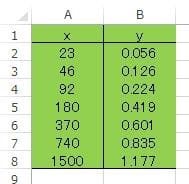
このブログは「すぐに役立つ統計のコツ」(オーム社)をもとに書いています。
杉本典夫 先生の
「統計学入門 第5章(5.5 各種手法の相互関係)」(下記URL)も参考にしています。
「統計学入門 第5章(5.5 各種手法の相互関係)」(下記URL)も参考にしています。
http://www.snap-tck.com/room04/c01/stat/stat05/stat0505.html
ところで、
上記URLに、「主軸回帰(MA回帰:Major axis regression」についての解説がありましたので、ひとつ下記の例題でやって見ましょう。例題は、
血清CPK活性値についてです。ちなみに、
CPK活性値は心筋梗塞の発症初期に異常に高い値を示しますので、心筋梗塞の診断によく用いられます。しかし、
採血し遠心分離した血清を窓際などの日射下に不用意に放置しておくとCPK値が減少しますので、採血後は速やかに冷蔵庫に保管し、なるべく、速やかに測定すべきでしょう。
上記URLに、「主軸回帰(MA回帰:Major axis regression」についての解説がありましたので、ひとつ下記の例題でやって見ましょう。例題は、
血清CPK活性値についてです。ちなみに、
CPK活性値は心筋梗塞の発症初期に異常に高い値を示しますので、心筋梗塞の診断によく用いられます。しかし、
採血し遠心分離した血清を窓際などの日射下に不用意に放置しておくとCPK値が減少しますので、採血後は速やかに冷蔵庫に保管し、なるべく、速やかに測定すべきでしょう。
さて、
例題は次の条件で測定した血清CPK活性値です。
例題は次の条件で測定した血清CPK活性値です。
・A1h:冷蔵庫に1時間放置
・B1h:室温28℃の日射下に1時間放置
・B1h:室温28℃の日射下に1時間放置
・A2h:冷蔵庫に2時間放置
・B2h:室温28℃の日射下に1時間放置
・B2h:室温28℃の日射下に1時間放置
図1 血清CPK活性値の比較

上記の2群間の相関関係は、単純に、相関回帰分析によって見ることが出来ます(すぐに役立つ統計のコツ、第6章 参照)。
ここでは、下記について既存の統計ソフトによる方法をご紹介します。
・単純な線形回帰の方法(OLS:Ordinary Least Squares):
ⅹに誤差がなくYに誤差がある。
・Deming の方法(重み付き線形回帰分析):
ⅩとYの分散比で補正。
・主軸回帰の方法(主軸回帰(MA回帰:Major axis regression):
Ⅹに対するY、Yに対するⅩの傾きの幾何平均による回帰分析。
・Passing&Bablokの方法(Passing–Bablok regression):
すべての傾きの中央値による回帰分析(ノンパラメトリック法)。
ⅹに誤差がなくYに誤差がある。
・Deming の方法(重み付き線形回帰分析):
ⅩとYの分散比で補正。
・主軸回帰の方法(主軸回帰(MA回帰:Major axis regression):
Ⅹに対するY、Yに対するⅩの傾きの幾何平均による回帰分析。
・Passing&Bablokの方法(Passing–Bablok regression):
すべての傾きの中央値による回帰分析(ノンパラメトリック法)。
ご紹介するソフトは下記URLからダウンロード出来ます。
ダウンロード先のご紹介(2017.6.24 現在確認):
「ValidationーSupport処理プログラム」
「ValidationーSupport処理プログラム」
http://www.jscc-jp.gr.jp/?page_id=1145
図2 日本臨床化学会

図3 ダウンロード

図3から、
「Validation-Support-V318-改良ソフト3 (zipファイル)」をダウンロードし展開(解凍)して本ソフトを立ち上げて下さい。
「Validation-Support-V318-改良ソフト3 (zipファイル)」をダウンロードし展開(解凍)して本ソフトを立ち上げて下さい。
そして、
Sheet名「相関分析」を開き→「解説」(1行C列)にマウスを重ねて説明に目を通して下さい。
Sheet名「相関分析」を開き→「解説」(1行C列)にマウスを重ねて説明に目を通して下さい。
次に、
図4の様に、例題(CPK)のデータ(A1h-B1h、A2h-B2h)のみを入力しますと、即座に結果が表示されます。
図4の様に、例題(CPK)のデータ(A1h-B1h、A2h-B2h)のみを入力しますと、即座に結果が表示されます。
図4 データの入力(コピー&ペースト)

なお、
出力結果の編集は出来ない様ですので、項目名をそのまま使用して下さい。
・試薬1→A1h
・試薬2→B1h
・Ⅹ2 →A2h
・Y2 →B2h
出力結果の編集は出来ない様ですので、項目名をそのまま使用して下さい。
・試薬1→A1h
・試薬2→B1h
・Ⅹ2 →A2h
・Y2 →B2h
●「ブートストラップ」をクリックし「Demingと標準主軸回帰の信頼限界」を求めて下さい。
● 誤差分散比は「1」を入力して下さい。
● 線形回帰(古典的回帰式)の「y→X」の係数(b)と切片(a)は、次により計算されている様です。
勾配(b)=Syy/Sxy=101474.6/126861.4≒0.8
切片(a)=Ymean-b*Xmean=81.65-0.8*96.05≒4.8
勾配(b)=Syy/Sxy=101474.6/126861.4≒0.8
切片(a)=Ymean-b*Xmean=81.65-0.8*96.05≒4.8
次回に、
データ解析環境「R」での方法とあわせて、分析結果を検証したいと思います。
データ解析環境「R」での方法とあわせて、分析結果を検証したいと思います。
情報統計研究所はここから!