統計技術 第Ⅲ部 Free Online Caluclator (例題集)
第3章-2:Multiple Regression(重回帰分析)
ここでの重回帰分析は、2つ以上の独立(説明)変数と従属(目的)変数の関係を多項方程式
Y=b1X1+b2X2+・・・b0
で表す多変量分析の1つである.
使用する Free Online Calculator :
● Free Statistics Software (Calculator) - Web-enabled scientific services & applications
https://www.wessa.net
上記URLのトップページから、
↓
Regression Software
↓
Multiple Regression
↓
図1 Data X と Names of X columns: などの規定値を確認
↓
Compute をクリック
出力結果
--------------------------------------
図2 重回帰式(推定式)
図3 重回帰推定パラメータ
図4 重回帰統計量
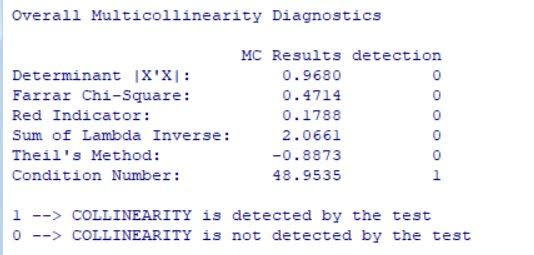
図5 多重共線性の検定
ここでの多重共線性は検出許容値(tolerance)または分散拡大係数(VIF)を用いている.
tolerance=1-Rj^2 VIF=1/tolerance
詳しくは、下記URL(統計学入門:杉本典夫)を参考にされたい.
http://www.snap-tck.com/room04/c01/stat/stat07/stat0702.html
また、下記URL「Gooブログ:医学と統計(44)(45)」に例題を示している.
医学と統計(44)
https://blog.goo.ne.jp/k-stat/e/7a9a0624fd14b888be1add8b4156d48d
ここで、
Rj^2 は、説明変数を他のすべての説明変数に回帰したときの決定係数であり、0.20または0.10未満、あるいは VIFが 5以上であれば、多重共線性が疑われる.
Farrar–Glauber 検定は変数が直交していれば多重共線性はないと判断し、直交していなければ、少なくともある程度の多重共線性があると判断する.
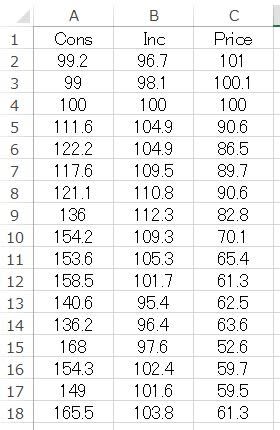
#「R」での実行:
# 既定値(Data X) を選択し、Excelにコピーしワークシートにペーストして利用すれば便利である.
----------------------------------------------------------
dat<- read.delim("clipboard", header=T) # データの読み込み
dat # データの確認
fit1<- lm(a ~ b + c , data=dat)
summary(fit1)
library(car)
vif(fit1)
# 別法
library(mctest)
fit2<- lm(a ~ b + c , data=dat)
summary(fit2)
# 統計量
id<-imcdiag(fit2); id$idiags[,1]
# VIFの閾値を「5 」としたとき.
imcdiag(fit2, method = "VIF", vif = 5)
----------------------------------------------------------
別法の出力結果:
図6 R(mctest)の統計量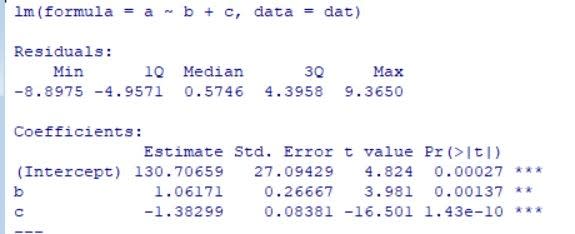
図7 R(mctest)によるVIF閾値=5での判定
# 1 --> COLLINEARITY ”あり”と判定
# 0 --> COLLINEARITY ”なし”と判定
----------------------------------------------------------
# Farrar–Glauber test:
omcdiag(fit2, detr=0.001, conf=0.99)
omcdiag(fit2)[1]
----------------------------------------------------------
Farrar–Glauber testの結果