








「すぐに役立つ統計のコツ」(第5章、40ページ)はカテゴリカルデータ(計数データ)・・・、名義尺度データについて紹介しています。
そして、
量的データをカテゴリカルデータに変換(ダミー変数 0,1を付与)し、分割表形式の統計的方法や検定方法について説明しています。
量的データをカテゴリカルデータに変換(ダミー変数 0,1を付与)し、分割表形式の統計的方法や検定方法について説明しています。
ここでは、
データ解析環境「R」での操作についてご紹介します。
データ解析環境「R」での操作についてご紹介します。
まず、
例題として、下記URL(情報統計研究所)にアクセスして下さい。
例題として、下記URL(情報統計研究所)にアクセスして下さい。
http://kstat.sakura.ne.jp
TOP ページから、[Excel Sample]をクリック、[Excel Sample(1):表22~表5.19]をダウンロードし、Sheet名「表5.3」を開くと、本書(表5.3、42ページ)のデータを得ることが出来ます。
このデータを用いて「R」での操作をやってみましょう!
「R」を立ち上げ、
・「R Console」 の画面に、
dat<- read.delim("clipboard", header=T)
dat<- read.delim("clipboard", header=T)
と記載し、実行せずにおいて下さい。そして、
・「Excel_Sample(1).xlsx」(Sheet名「表5.3」)の「J列2行:O列102行」を選択しコピーします。
・「Excel_Sample(1).xlsx」(Sheet名「表5.3」)の「J列2行:O列102行」を選択しコピーします。
そして、
・「R Console」 の画面の、
dat<- read.delim("clipboard", header=T)
・「R Console」 の画面の、
dat<- read.delim("clipboard", header=T)
を実行しすれば、データを取り込む事が出来ます。
確認は次により行えば良いでしょう。
head(dat) # データの確認
そして、
・「R」→ファイル→新しいスクリプト
・新しいスクリプトの「無題・Rエディタ」に以下のプログラムを書き実行します。
・関数「table()、ftable()、xtabs()」を使って見ましょう。
・新しいスクリプトの「無題・Rエディタ」に以下のプログラムを書き実行します。
・関数「table()、ftable()、xtabs()」を使って見ましょう。
***
attach(dat)
C.table1<- table(Gender, TC) # table()による2×2分割表
C.table1
attach(dat)
C.table1<- table(Gender, TC) # table()による2×2分割表
C.table1
C.ftable1<- ftable(Gender, TC) # ftable()による2×2分割表
C.ftable1
C.ftable1
C.xtable1<- xtabs(~ Gender + TC) # xtabs()による2×2分割表
C.xtable1
C.xtable1
round(prop.table(C.table1), 3) # 全体の合計に対する比率
round(prop.table(C.table1, 1), 3) # 行の 合計に対する比率
round(prop.table(C.table1, 2), 3) # 列の 合計に対する比率
round(prop.table(C.table1, 1), 3) # 行の 合計に対する比率
round(prop.table(C.table1, 2), 3) # 列の 合計に対する比率
# 「ftable1」と「xtabs」も同じで、全体に対する比率は次のようにします。
round(prop.table(C.ftable1), 3)
round(prop.table(C.xtable1), 3)
round(prop.table(C.xtable1), 3)
出力結果:
次のような2×2分割表が出力されます。
次のような2×2分割表が出力されます。
TC
Gender 0 1
0 32 11
1 54 3
***
Gender 0 1
0 32 11
1 54 3
***
この出力結果を選択・コピーし、MS-Excel にテキスト・ペーストして整形すれば図1の様な分割表を作ることが出来ます。
図1 GenderとTC の分割表
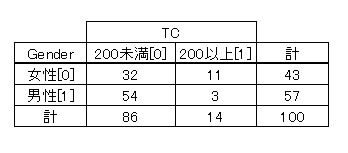
なお、カイ二乗計算は次により行えば良いでしょう。
***
chisq.test(C.table1, correct = T) # 補正あり(既定値)
chisq.test(C.table1, correct = F) # 補正なし
chisq.test(C.table1, simulate.p.value = T、B = 2000)
# モンテカルロ・シュミレーションの計算と試行回数
chisq.test(C.table1, correct = T) # 補正あり(既定値)
chisq.test(C.table1, correct = F) # 補正なし
chisq.test(C.table1, simulate.p.value = T、B = 2000)
# モンテカルロ・シュミレーションの計算と試行回数
fisher.test(C.table1) # フイッシャーの直接確率計算
***
***
長くなりますので、今回はここまでとします。
次回は「R」でピボットテーブルをご紹介したいと思います。
なお、
本書の表5.16(49ページ)のデータは加工したもので、「Excel_Sample(1).xlsx」とは一致しません。
本書の表5.16(49ページ)のデータは加工したもので、「Excel_Sample(1).xlsx」とは一致しません。
情報統計研究所はここから!




