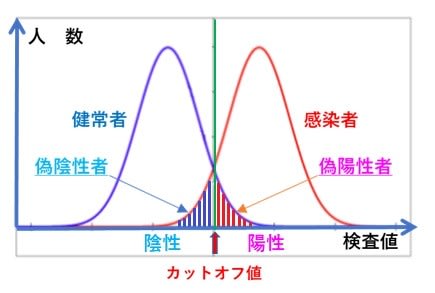
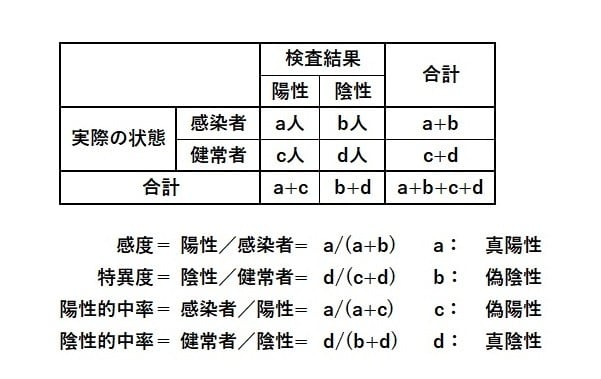
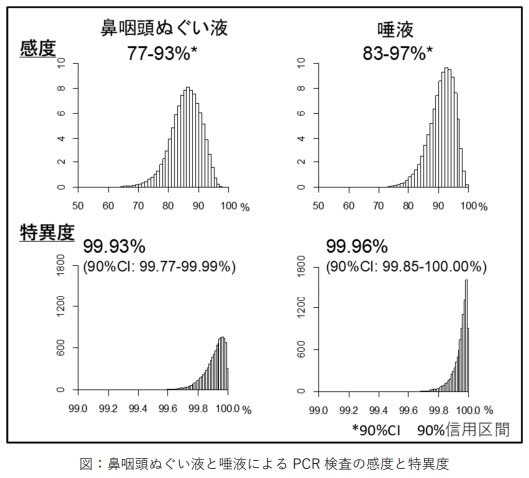
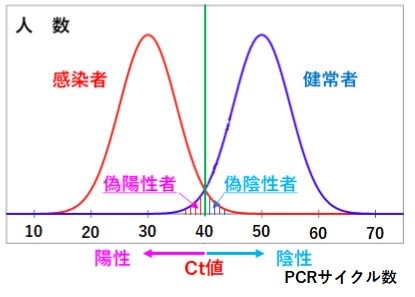
PCR検査の基本原理はこれまでにも書いてきたように、ある程度理解できたと思うが、実際にどのようにして検査が行われているかについてもう少し詳しく知りたく思い、YouTubeで検索していくつかの映像を見た。
その結果、高校の生物の授業、あるいは大学入試の生物の問題として扱われているものの中に、理解しやすいものが含まれていることが判り、これらから得られる情報を自分なりに整理して考えてみた。
我々の世代の者にとっては、DNAの二重らせん構造の発見、遺伝暗号の解読、そして全ゲノムの解析といった情報は同時進行形で経験をした内容であり、中学校や高校で学習したものではないが、現代の高校生にとっては普通に学んでいる内容ということのようである。
PCR法の原理もまた、高校生が生物の授業で学んでいるものということで、隔世の感がある。
ところで、今回こうしたことを知りたいと思った背景は、やはり新型コロナウイルスのPCR検査をめぐる議論が尽きないからで、専門家の間でもその有効性や限界について、意見が分かれているからである。その一端については前回紹介した。
また、今回PCR検査に関連して、中国から最初に報告された新型コロナウイルスの塩基配列を確認する作業を行ったが、その塩基配列を眺めていると、素人には理解不能なこともいくつか見られた。皆さんはどのように感じられるだろうか。我慢して後段まで読み進めていただければと思う。
先ず、新型コロナウイルスで採用されているPCR検査は、RT-PCRと呼ばれることがあるが、このRTには2通りの意味が込められている。
一つはRTが逆転写(Reverse Transcription)の意味で使用されている場合で、これは新型コロナウイルスの遺伝子がRNAであり、PCRでこのRNAを増幅させ、検出可能にするためには、先ず1本鎖のRNAを2本鎖のDNAにする逆転写プロセスを経る必要があり、RNAからDNAをつくるときに必要な酵素は逆転写酵素(Reverse Transcriptase)と呼ばれていて、PCR検査試薬にはこの逆転写酵素が添加されていることによる。
RTのもう一つの意味はリアルタイム(Real Time)の意味で使用されているもので、これは実用的なPCR検査が、常(リアルタイム)に反応の進行状態を光学的にモニターしていることによる。
従って、新型コロナウイルスの感染診断に用いるPCR法は、厳密にはRT-RT-PCRということになるが、通常はどちらかを優先的に考えてRT-PCRと記述されているようである。もちろん単にPCRと呼ばれていることも多い。
さて、新型コロナウイルスから抽出される遺伝子、RNAはその長さがおよそ3万塩基からなるとされる。中国がいち早く報告したとされる武漢コロナウイルスの塩基配列は次の様であり、30473個の塩基からなるとされている(Wuhan seafood market pneumonia virus isolate Wuhan-Hu-1, complete genome, GenBank: MN908947.1)。

中国からGenBankに最初に報告された新型武漢コロナウイルスに関するレポートの冒頭部(2020.1.12報告)
ここにはタイトルにもあるように、新型武漢コロナウイルスの全ゲノム配列が示されていて、次のようである。先端部と末端部を紹介する。PCR検査ではこの先端部と末端部にある、新型武漢コロナウイルスにのみ特徴的とされる塩基配列に着目して増幅が行われる。

上記レポートに記載されている武漢コロナウイルスの塩基配列(先頭部分)

上記レポートに記載されている武漢コロナウイルスの塩基配列(末端部分)
厚労省がこの新型コロナウイルス感染検査のために公表しているマニュアル『病原体検出マニュアル 2019-nCoV Ver.2.9.1(令和 2 年 3 月 19 日発行)』(これは前回引用した国会質疑の中で紹介されている感染研法に相当するものと思われるが)には、PCR検査に使用するF(フォワード)とR(リバース)の一対のプライマーと呼ばれる、増幅領域を決定するための短い塩基の配列が、ORF1a領域と、Spike領域の2か所について、それぞれ示されている。
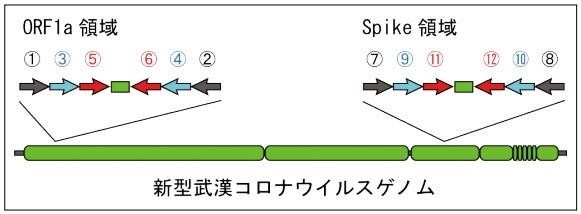
新型武漢コロナウイルスのPCR検査で増幅対象となる2つの領域
この2領域は 2-step RT-PCR 法に用いるものとされていて、プライマーの位置を示す番地は次のようである。
①F501、②R913、③F509、④R854、⑤F519、⑥R840、⑨F24381、⑩R24873、⑪F24383、⑫R24865(⑦、⑧の番地情報は示されていない)。
リアルタイム RT-PCR 法による遺伝子検査には別途次のプライマー情報が提供されている。
対象となる位置は上図のSpike領域よりもさらに末端部に近い2つの領域が選ばれていて、次のようである。プローブは増幅中に発光分子を取り込むために用いられるもの。

リアルタイムRT-PCR検査に使用するプライマーの塩基配列(厚労省マニュアルより)
ここで示されているプライマーは、19個または20個の塩基からなるもので、新型コロナウイルスを特徴づける場所128塩基、または158塩基からなる領域の両端の塩基配列を示している。
プライマーとしては、こうした塩基配列と結合するための、相補的な塩基配列になる。フォワードの塩基配列は、新型武漢コロナウイルスの塩基配列をそのまま示したものだが、リバースの塩基配列は、前記のようにRNAから逆転写したDNAの塩基配列に読み替えられている。
GenBankに登録された、前記の遺伝子配列にこの2つの領域を見つけることができる。プライマーの位置を黄色で示す。増幅される領域は、プライマーに挟まれた領域(青)を含むこととなるが、次のようである。ただ、どういうわけか番地が1つずれている。
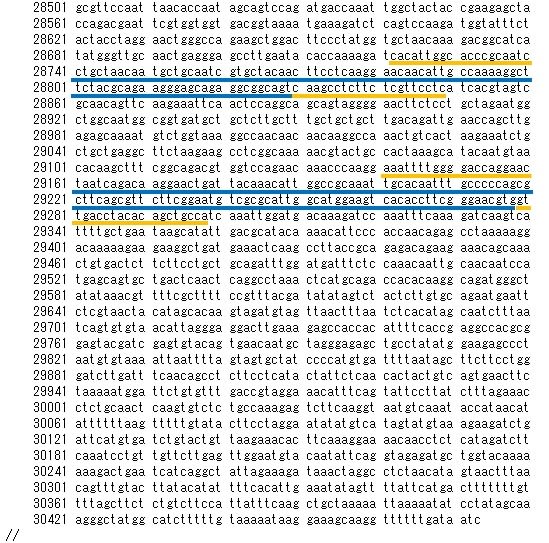
新型武漢コロナウイルスの塩基配列と、PCR検査の増幅対象とされている2つの領域
このプライマーの位置に関する情報が、米国のCDCがいち早く公表したとされるものであるのか、日本の国立感染症研究所が独自に決定した物かはここではわからない。
ところで、ここでこの20個の塩基からなるプライマーについて考えてみたい。
4種類のA(アデニン)、T(チミン)、G(グアニン)、そしてC(シトシン)のいずれかを20個つなぐ場合、その種類数は4の20乗≒10の12乗=1兆である。言い換えれば、20個の塩基からなるプライマーというのは1兆種類の中から選ばれた、ただ1種類ということである。
一方、新型コロナウイルスの塩基数はおよそ3万なので、目標とする場所以外の領域にこれらのプライマーが結合できる塩基配列が見つかる確率は、単純計算で約30000/1兆であり、0.000003%ということになる。
これは、同じような塩基数を持っている、新型コロナウイルスに類似した別のコロナウイルスが検体に混入しているとした場合、このコロナウイルスを誤って増幅させる可能性は実質的にゼロに等しいということも意味している。ただし、もちろんプライマーとして、両者に共通した塩基配列の領域をあえて選択した場合は別であるが。
ちなみに、新型武漢コロナウイルスと類似のウイルスの遺伝子の相同性は、コウモリのコロナウイルスでは96%、SARSでは80%、MERSでは55%であるとされる。
もうひとつ、PCR検査の検体には人体由来の遺伝子DNAが当然含まれていると思われるが、プライマーがこのDNAに結合する確率を見ておく必要があるだろう。
人のDNAはおよそ32億塩基対からなるとされる。このDNAの一方のどこかに、PCR検査用のプライマーが結合できる20個の塩基配列が見つかる確率は、やはり単純計算で約32億/1兆=0.32%ということになる。この数値も、実際にはフォワードとリバースの1対のDNAの両方で同時にプライマーの塩基配列に合致した部位が存在する確率も加味すると、実際上PCR検査結果に影響するレベルではないと言えるのではないだろうか。
PCR検査の有効性について、専門家の間でも様々な意見がある現状だが、PCR検査において、新型武漢コロナウイルス以外のRNAやDNAに誤って反応する可能性についての疑問は解消すると思えるのであるがどうだろうか。
次に、GenBankに登録された前述の新型武漢コロナウイルスの塩基配列情報そのものを詳しく見ておこうと思う。このデータは、その後2回にわたって更新され、Ver.2とVer.3が提出されていることが判っている。以下のようである。

新型武漢コロナウイルスの塩基配列を更新(Ver.2)したレポートの冒頭部(2020.1.14更新)

GenBank レポートのVer.2に報告されている新型武漢コロナウイルスの塩基配列の末端部(Ver.1よりも短くなっているが、最終端まで塩基配列は同じであることがわかる)
Ver.2の塩基配列は、長さがVer.1の30473塩基に比べると29875塩基と短くなっているが、1~29875番地までの塩基配列は、先端と末端の塩基配列を見る限り、完全に一致しているように見える。
しかし最後の図に示すように、ごく一部に差異のあることが判った。この違いは16個の塩基が抜けて、16個の塩基が挿入されているというものなので、結局のところ2か所のプライマーの指定位置の塩基配列情報は変わっていないという状況である。
厚労省が公開している検査マニュアルには、プライマーの情報はこのうちVer.1に基づいているとの注記がある。
次に、Ver.3の塩基配列を見ると、一見して、Ver.1およびVer.2とは異なる塩基配列である。しかし、これもよく見ると、先端付近の塩基が16個欠落した塩基配列になっていることが判り、16個ずらしてみると3者ともに同じ塩基配列を示している。
この16個のずれは不思議な配列の一致を生み出している。上でVer.2の塩基配列に16個の脱落と挿入があると書いたが、その結果、Ver.2とVer.3の塩基配列は5041番地から5100番地までぴったりと一致することになっている(最後の図参照)。
さらに別の場所では、最後の図に示したように一部に変異がみられる。この変異もまた16個の塩基が挿入され、60個分の間を置いて、今度は16個の塩基が抜けている。結果として、この2か所の変異部位に挟まれた番地だけは、Ver.1からVer.3の塩基配列が全く同一になるといった奇跡的なことが起きている。また、その後は再び16個分ずれた形になっていることが判る。
Ver.3の塩基配列では、このためプライマーとして指定されている番地の塩基配列は検査マニュアルのものとは異なっていて、同じ番地を探してもこのプライマーの塩基配列を見つけることはできない。以下に見るとおりである。Ver.3記載の塩基数はVer.2比では僅かに増加しているがVer.1に比べると減少していて、29903個である。
Ver.3が報告されたのは、下記の通り2020年3月18日であるが、データは2カ月も早く2020年1月17日にはVer.1やVer.2に代わるものとして置き換えられていたとのコメントがある。

新型武漢コロナウイルスの塩基配列を更新(Ver.3)したレポートの冒頭部(2020.3.18更新)

GenBank レポートのVer.3に報告されている新型武漢コロナウイルスの塩基配列の末端部(厚労省のマニュアルのプライマー用とされる塩基配列は、指定されている番地には見つからず、16個分だけずれた位置に見られる)
中国から報告されている新型武漢コロナウイルスの塩基配列情報をVer.1からVer.3まで部分的に比較すると次のようである。Ver.1とVer.2の塩基配列は長さは異なるが、番地も含めてほぼ完全に一致している。一方Ver.3は16塩基分だけ番地がずれた塩基配列である。ただ10021番地から10080番地までの配列は3者とも完全に一致している。
Ver.1-1 cggtgacgca tacaaaacat tcccaccata ccttcccagg taacaaacca accaactttc
Ver.2-1 cggtgacgca tacaaaacat tcccaccata ccttcccagg taacaaacca accaactttc
Ver.3-1 attaaaggtt tataccttcc caggtaacaa accaaccaac tttcgatctc ttgtagatct
Ver.1-61 gatctcttgt agatctgttc tctaaacgaa ctttaaaatc tgtgtggctg tcactcggct
Ver.2-61 gatctcttgt agatctgttc tctaaacgaa ctttaaaatc tgtgtggctg tcactcggct
Ver.3-61 gttctctaaa cgaactttaa aatctgtgtg gctgtcactc ggctgcatgc ttagtgcact
Ver.1-1021 agagctatga attgcagaca ccttttgaaa ttaaattggc aaagaaattt gacaccttca
Ver.2-1021 agagctatga attgcagaca ccttttgaaa ttaaattggc aaagaaattt gacaccttca
Ver.3-1021 gacacctttt gaaattaaat tggcaaagaa atttgacacc ttcaatgggg aatgtccaaa
Ver.1-5041 caatgacata tggacaacag tttggtccaa cttatttgga tggagctgat gttactaaaa
Ver.2-5041 acagtttggt ccaacttatt tggatggagc tgatgttac aaaataaaac ctcataattc
Ver.3-5041 acagtttggt ccaacttatt tggatggagc tgatgttac aaaataaaac ctcataattc
Ver.1-10021 atgttcttta ccaaccacca caaacctcta tcacctcagc tgttttgcag agtggtttta
Ver.2-10021 atgttcttta ccaaccacca caaacctcta tcacctcagc tgttttgcag agtggtttta
Ver.3-10021 atgttcttta ccaaccacca caaacctcta tcacctcagc tgttttgcag agtggtttta
Ver.1-20041 aaatgcccgt aatggtgttc ttattacaga aggtagtgtt aaaggtttac aaccatctgt
Ver.2-20041 aaatgcccgt aatggtgttc ttattacaga aggtagtgtt aaaggtttac aaccatctgt
Ver.3-20041 gttcttatta cagaaggtag tgttaaaggt ttacaaccat ctgtaggtcc caaacaagct
Ver.1-29041 ctgctgaggc ttctaagaag cctcggcaaa aacgtactgc cactaaagca tacaatgtaa
Ver.2-29041 ctgctgaggc ttctaagaag cctcggcaaa aacgtactgc cactaaagca tacaatgtaa
Ver.3-29041 gaagcctcgg caaaaacgta ctgccactaa agcatacaat gtaacacaag ctttcggcag
Ver.1-29821 aatgtgtaaa attaatttta gtagtgctat ccccatgtga ttttaatagc ttcttcctgg
Ver.2-29821 aatgtgtaaa attaatttta gtagtgctat ccccatgtga ttttaatagc ttctt
Ver.3-29821 tttagtagtg ctatccccat gtgattttaa tagcttctta ggagaatgac aaaaaaaaaa
最終端は比較するためではないが、次のようである。
Ver.1-30421 agggctatgg catctttttg taaaaataag gaaagcaagg ttttttgata atc 30473
Ver.2-29821 aatgtgtaaa attaatttta gtagtgctat ccccatgtga ttttaatagc ttctt 29875
Ver.3-29881 aaaaaaaaaa aaaaaaaaaa aaa 29903
最後に、Ver.1からVer.3までの塩基配列の変化を図示すると次のようである。一番下に日本の国立感染症研究所が一旦公開し、その後取り下げている新型コロナウイルスの全遺伝子配列の情報を追記した。中国のVer.1と比べるとほとんど一致する内容であるが、プライマー位置を含め、全体として43塩基分だけずれていることがわかる。
これらの塩基配列比較は、注意して見たが、全塩基配列をすべて比較したわけではないので、気が付かなかったところがあるかもしれないことをお断りしておく。目的としたところはPCR検査に使用するプライマーの位置情報を確認しておくためである。
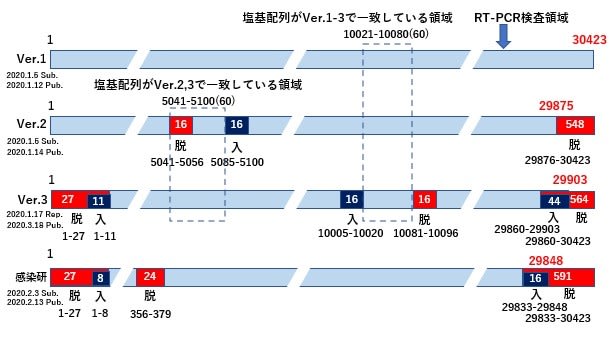
GenBankに登録されている新型武漢コロナウイルスの更新内容(Ver.1とVer.2はほぼすべての領域で塩基配列は一致しており、Ver.3だけは、ほとんどの領域で16塩基分のずれが起きている。参考までに一番下に日本の感染研からのデータを示す。2021.2.1 一部追記)
*2021.2.1 一部追記。